| Commit message (Collapse) | Author | Age | Files | Lines |
|---|
| | |
|
| | |
|
| |
|
|
| |
Combine everything in to one C function
|
| | |
|
| | |
|
| |
|
|
|
|
|
|
|
|
| |
* `GC.auto_compact=`, `GC.auto_compact` can be used to control when
compaction runs. Setting `auto_compact=` to true will cause
compaction to occurr duing major collections. At the moment,
compaction adds significant overhead to major collections, so please
test first!
[Feature #17176]
|
| |
|
|
| |
This patch allows to move more data types.
|
| |
|
|
|
| |
It's not necessary to check ivpt because objects are allocated as
"embedded" by default
|
| |
|
|
| |
Same as 5be42c1ef4f7ed0a8004cad750a9ce61869bd768
|
| |
|
|
|
|
|
|
| |
As of 0b81a484f3453082d28a48968a063fd907daa5b5, `ROBJECT_IVPTR` will
always return a value, so we don't need to test whether or not we got
one. T_OBJECTs always come to life as embedded objects, so they will
return an ivptr, and when they become "unembedded" they will have an
ivptr at that point too
|
| |
|
|
|
| |
We don't need to check the existence if an ivptr because non-embedded
objects will always have one
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
We are seeing an error where code that is generated with MJIT contains
references to objects that have been moved. I believe this is due to a
race condition in the compaction function.
`gc_compact` has two steps:
1. Run a full GC to pin objects
2. Compact / update references
Step one is executed with `garbage_collect`. `garbage_collect` calls
`gc_enter` / `gc_exit`, these functions acquire a JIT lock and release a
JIT lock. So a lock is held for the duration of step 1.
Step two is executed by `gc_compact_after_gc`. It also holds a JIT
lock.
I believe the problem is that the JIT is free to execute between step 1
and step 2. It copies call cache values, but doesn't pin them when it
copies them. So the compactor thinks it's OK to move the call cache
even though it is not safe.
We need to hold a lock for the duration of `garbage_collect` *and*
`gc_compact_after_gc`. This patch introduces a lock level which
increments and decrements. The compaction function can increment and
decrement the lock level and prevent MJIT from executing during both
steps.
|
| |
|
|
|
|
|
|
|
|
| |
rb_objspace_reachable_objects_from(obj) is used to traverse all
reachable objects from obj. This function modify objspace but it
is not ractor-safe (thread-safe). This patch fix the problem.
Strategy:
(1) call GC mark process during_gc
(2) call Ractor-local custom mark func when !during_gc
|
| |
|
|
|
|
|
| |
Unshareable objects should not be touched from multiple ractors
so ObjectSpace.each_object should be restricted. On multi-ractor
mode, ObjectSpace.each_object only iterates shareable objects.
[Feature #17270]
|
| |
|
|
|
|
|
|
|
|
|
|
| |
iv_index_tbl manages instance variable indexes (ID -> index).
This data structure should be synchronized with other ractors
so introduce some VM locks.
This patch also introduced atomic ivar cache used by
set/getinlinecache instructions. To make updating ivar cache (IVC),
we changed iv_index_tbl data structure to manage (ID -> entry)
and an entry points serial and index. IVC points to this entry so
that cache update becomes atomically.
|
| |
|
|
| |
DATA_PTR(ractor) can be NULL just after creation.
|
| |
|
|
|
|
|
| |
Heap allocated objects are never special constants. Since we're walking
the heap, we know none of these objects can be special. Also, adding
the object to the freelist will poison the object, so we can't check
that the type is T_NONE after poison.
|
| |
|
|
|
| |
Invalidating call cache walks the heap, so we need to take care to
un-poison objects when examining them
|
| |
|
|
|
| |
rb_vm_t::mark_object_ary is global resource so we need to
synchronize to access it.
|
| | |
|
| |
|
|
|
|
| |
If an object has a finalizer flag set on it, prevent it from moving.
This partially reverts commit 1a9dd31910699c7cd69f2a84c94af20eacd5875c.
|
| | |
|
| | |
|
| |
|
|
|
|
|
|
|
|
| |
When finalizers run (in `rb_objspace_call_finalizer`) the table is
copied to a linked list that is not managed by the GC. If compaction
runs, the references in the linked list can go bad.
Finalizer table shouldn't be used frequently, so lets pin references in
the table so that the linked list in `rb_objspace_call_finalizer` is
safe.
|
| | |
|
| |
|
|
|
| |
Also improve specs and documentation for finalizers and more clearly
recommend a safe code pattern to use them.
|
| | |
|
| | |
|
| | |
|
| |
|
|
|
|
| |
rb_obj_raw_info is called while printing out crash messages and
sometimes called during garbage collection. Calling rb_raise() in these
situations is undesirable because it can start executing ensure blocks.
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
This commit introduces Ractor mechanism to run Ruby program in
parallel. See doc/ractor.md for more details about Ractor.
See ticket [Feature #17100] to see the implementation details
and discussions.
[Feature #17100]
This commit does not complete the implementation. You can find
many bugs on using Ractor. Also the specification will be changed
so that this feature is experimental. You will see a warning when
you make the first Ractor with `Ractor.new`.
I hope this feature can help programmers from thread-safety issues.
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
Previously, when an object is first initialized, ROBJECT_EMBED isn't
set. This means that for brand new objects, ROBJECT_NUMIV(obj) is 0 and
ROBJECT_IV_INDEX_TBL(obj) is NULL.
Previously, this combination meant that the inline cache would never be
initialized when setting an ivar on an object for the first time since
iv_index_tbl was NULL, and if it were it would never be used because
ROBJECT_NUMIV was 0. Both cases always fell through to the generic
rb_ivar_set which would then set the ROBJECT_EMBED flag and initialize
the ivar array.
This commit changes rb_class_allocate_instance to set the ROBJECT_EMBED
flag on the object initially and to initialize all members of the
embedded array to Qundef. This allows the inline cache to be set
correctly on first use and to be used on future uses.
This moves rb_class_allocate_instance to gc.c, so that it has access to
newobj_of. This seems appropriate given that there are other allocating
methods in this file (ex. rb_data_object_wrap, rb_imemo_new).
|
| |
|
|
| |
This error is about wb unprotected objects, not old objects.
|
| | |
|
| | |
|
| | |
|
| |
|
|
|
|
| |
Ruby strings don't always have a null terminator, so we can't use
it as a regular C string. By reading only the first len bytes of
the Ruby string, we won't read past the end of the Ruby string.
|
| |
|
|
|
| |
Remove all usages of RCAST() so that the header file can be excluded
from ruby/ruby.h's dependency.
|
| |
|
|
|
|
| |
`rb_objspace_call_finalizer` creates zombies, but does not do the correct accounting (it should increment `heap_pages_final_slots` whenever it creates a zombie). When we do correct accounting, `heap_pages_final_slots` should never underflow (the check for underflow was introduced in 39725a4db6b121c7779b2b34f7da9d9339415a1c).
The implementation moves the accounting from the functions that call `make_zombie` into `make_zombie` itself, which reduces code duplication.
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
Before this commit, iclasses were "shady", or not protected by write
barriers. Because of that, the GC needs to spend more time marking these
objects than otherwise.
Applications that make heavy use of modules should see reduction in GC
time as they have a significant number of live iclasses on the heap.
- Put logic for iclass method table ownership into a function
- Remove calls to WB_UNPROTECT and insert write barriers for iclasses
This commit relies on the following invariant: for any non oirigin
iclass `I`, `RCLASS_M_TBL(I) == RCLASS_M_TBL(RBasic(I)->klass)`. This
invariant did not hold prior to 98286e9 for classes and modules that
have prepended modules.
[Feature #16984]
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
* Enable unaligned accesses on arm64
64-bit Arm platforms support unaligned accesses.
Running the string benchmarks this change improves performance
by an average of 1.04x, min .96x, max 1.21x, median 1.01x
* arm64 enable gc optimizations
Similar to x86 and powerpc optimizations.
| |compare-ruby|built-ruby|
|:------|-----------:|---------:|
|hash1 | 0.225| 0.237|
| | -| 1.05x|
|hash2 | 0.110| 0.110|
| | 1.00x| -|
* vm_exec.c: improve performance for arm64
| |compare-ruby|built-ruby|
|:------------------------------|-----------:|---------:|
|vm_array | 26.501M| 27.959M|
| | -| 1.06x|
|vm_attr_ivar | 21.606M| 31.429M|
| | -| 1.45x|
|vm_attr_ivar_set | 21.178M| 26.113M|
| | -| 1.23x|
|vm_backtrace | 6.621| 6.668|
| | -| 1.01x|
|vm_bigarray | 26.205M| 29.958M|
| | -| 1.14x|
|vm_bighash | 504.155k| 479.306k|
| | 1.05x| -|
|vm_block | 16.692M| 21.315M|
| | -| 1.28x|
|block_handler_type_iseq | 5.083| 7.004|
| | -| 1.38x|
|
| |
|
|
|
| |
Walking the heap can inadvertently pin objects. Only mark the object's
pin bit if the mark_func_data pointer is NULL (similar to the mark bits)
|
| |
|
|
|
|
|
|
|
|
|
|
| |
To optimize the sweep phase, there is bit operation to set mark
bits for out-of-range bits in the last bit_t.
However, if there is no out-of-ragnge bits, it set all last bit_t
as mark bits and it braek the assumption (unmarked objects will
be swept).
GC_DEBUG=1 makes sizeof(RVALUE)=64 on my machine and this condition
happens.
It took me one Saturday to debug this.
|
| |
|
|
|
| |
Each class/module/iclass can potentially have their own cc table.
Count their malloc usage.
|
| |
|
|
|
|
| |
imemo_callcache and imemo_callinfo were not handled by the `objspace`
module and were showing up as "unknown" in the dump. Extract the code for
naming imemos and use that in both the GC and the `objspace` module.
|
| |
|
|
|
| |
... because shifting by more than 31 bits has undefined behavior
(depending upon platform). Coverity Scan found this issue.
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
This commit expands heap pages to be exactly 16KiB and eliminates the
`REQUIRED_SIZE_BY_MALLOC` constant.
I believe the goal of `REQUIRED_SIZE_BY_MALLOC` was to make the heap
pages consume some multiple of OS page size. 16KiB is convenient because
OS page size is typically 4KiB, so one Ruby page is four OS pages.
Do not guess how malloc works
=============================
We should not try to guess how `malloc` works and instead request (and
use) four OS pages.
Here is my reasoning:
1. Not all mallocs will store metadata in the same region as user requested
memory. jemalloc specifically states[1]:
> Information about the states of the runs is stored as a page map at the beginning of each chunk.
2. We're using `posix_memalign` to request memory. This means that the
first address must be divisible by the alignment. Our allocation is
page aligned, so if malloc is storing metadata *before* the page,
then we've already crossed page boundaries.
3. Some allocators like glibc will use the memory at the end of the
page. I am able to demonstrate that glibc will return pointers
within the page boundary that contains `heap_page_body`[2]. We
*expected* the allocation to look like this:
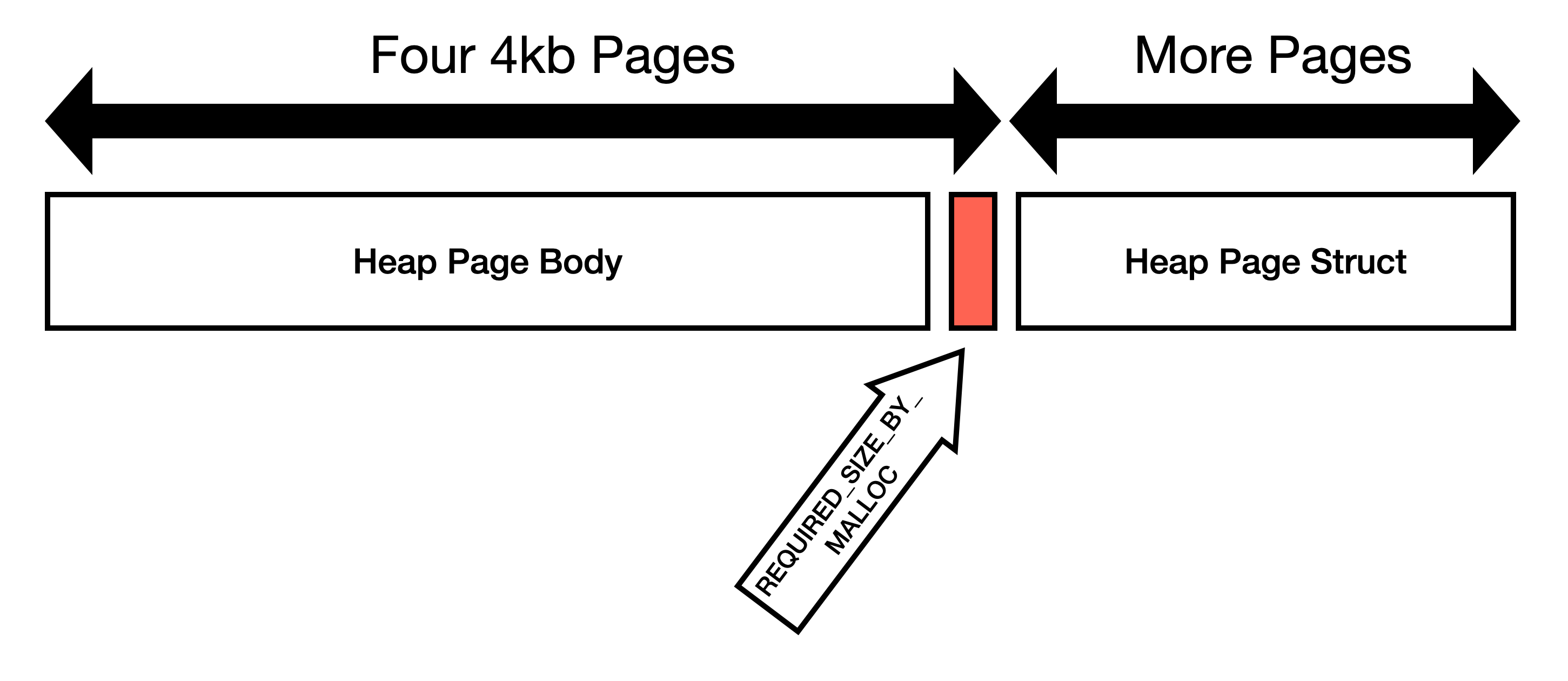
But since `heap_page` is allocated immediately after
`heap_page_body`[3], instead the layout looks like this:
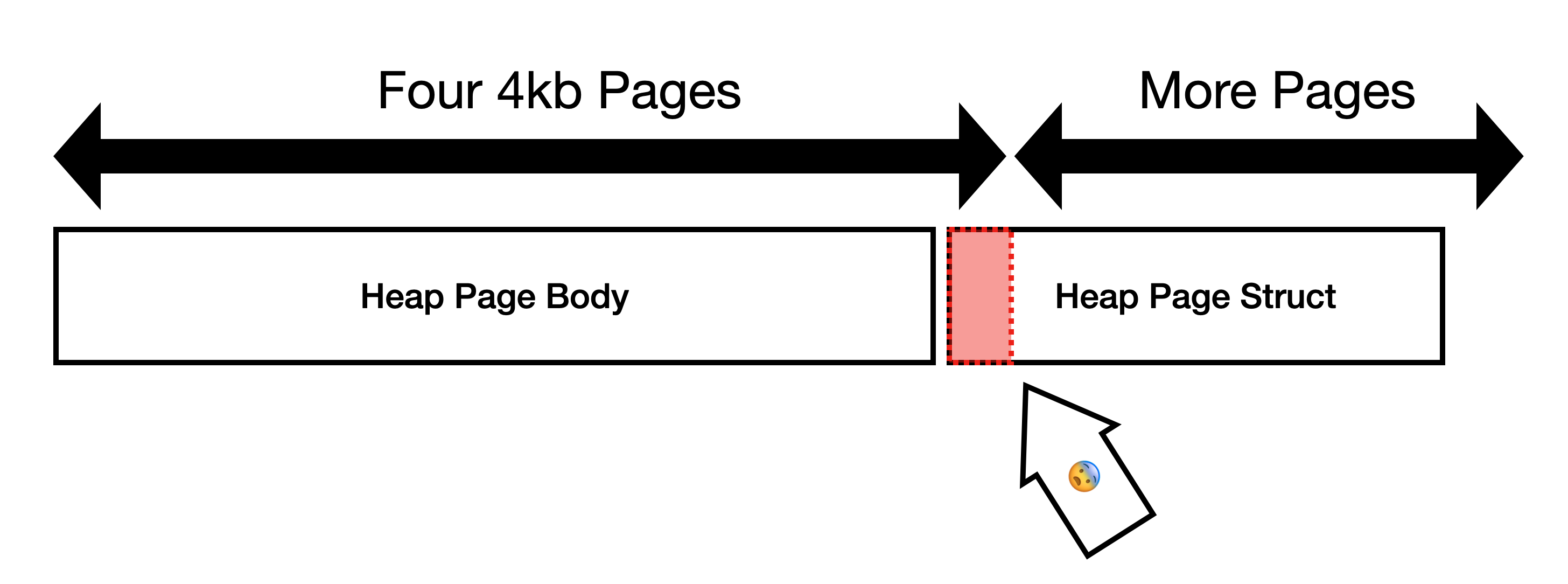
This is not optimal because `heap_page` gets allocated immediately
after `heap_page_body`. We frequently write to `heap_page`, so the
bottom OS page of `heap_page_body` is very likely to be copied.
One more object per page
========================
In jemalloc, allocation requests are rounded to the nearest boundary,
which in this case is 16KiB[4], so `REQUIRED_SIZE_BY_MALLOC` space is
just wasted on jemalloc.
On glibc, the space is not wasted, but instead it is very likely to
cause page faults.
Instead of wasting space or causing page faults, lets just use the space
to store one more Ruby object. Using the space to store one more Ruby
object will prevent page faults, stop wasting space, decrease memory
usage, decrease GC time, etc.
1. https://people.freebsd.org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf
2. https://github.com/ruby/ruby/commit/33390d15e7a6f803823efcb41205167c8b126fbb
3 https://github.com/ruby/ruby/blob/289a28e68f30e879760fd000833b512d506a0805/gc.c#L1757-L1763
4. https://people.freebsd.org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf page 4
Co-authored-by: John Hawthorn <john@hawthorn.email>
|
| |
|
|
|
| |
I'm not necessarily against every goto in general, but jumping into a
branch is definitely a bad idea. Better refactor.
|
| |
|
|
|
| |
I'm not necessarily against every goto in general, but jumping into a
branch is definitely a bad idea. Better refactor.
|
| |
|
|
|
|
|
|
| |
This commit converts RMoved slots to a doubly linked list. I want to
convert this to a doubly linked list because the read barrier (currently
in development) must remove nodes from the moved list sometimes.
Removing nodes from the list is much easier if the list is doubly
linked. In addition, we can reuse the list manipulation routines.
|
