
diff options
Diffstat (limited to 'doc/architecture')
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
104 files changed, 6173 insertions, 3421 deletions
diff --git a/doc/architecture/blueprints/_template.md b/doc/architecture/blueprints/_template.md index f7dea60e9b7..e22cc2e6857 100644 --- a/doc/architecture/blueprints/_template.md +++ b/doc/architecture/blueprints/_template.md @@ -50,10 +50,14 @@ Blueprint statuses you can use: - "accepted" - "ongoing" - "implemented" +- "postponed" - "rejected" --> +<!-- Blueprints often contain forward-looking statements --> +<!-- vale gitlab.FutureTense = NO --> + # {+ Title of Blueprint +} <!-- @@ -125,6 +129,9 @@ but keep it simple! This should have enough detail that reviewers can understand exactly what you're proposing, but should not include things like API designs or implementation. The "Design Details" section below is for the real nitty-gritty. + +You might want to consider including the pros and cons of the proposed solution so that they can be +compared with the pros and cons of alternatives. --> ## Design and implementation details @@ -153,3 +160,12 @@ Diagrams authored in GitLab flavored markdown are preferred. In cases where that is not feasible, images should be placed under `images/` in the same directory as the `index.md` for the proposal. --> + +## Alternative Solutions + +<!-- +It might be a good idea to include a list of alternative solutions or paths considered, although it is not required. Include pros and cons for +each alternative solution/path. + +"Do nothing" and its pros and cons could be included in the list too. +--> diff --git a/doc/architecture/blueprints/cells/cells-feature-admin-area.md b/doc/architecture/blueprints/cells/cells-feature-admin-area.md new file mode 100644 index 00000000000..31d5388d40b --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-admin-area.md @@ -0,0 +1,59 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Admin Area' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Admin Area + +In our Cells architecture proposal we plan to share all admin related tables in +GitLab. This allows simpler management of all Cells in one interface and reduces +the risk of settings diverging in different Cells. This introduces challenges +with admin pages that allow you to manage data that will be spread across all +Cells. + +## 1. Definition + +There are consequences for admin pages that contain data that spans "the whole +instance" as the Admin pages may be served by any Cell or possibly just 1 cell. +There are already many parts of the Admin interface that will have data that +spans many cells. For example lists of all Groups, Projects, Topics, Jobs, +Analytics, Applications and more. There are also administrative monitoring +capabilities in the Admin page that will span many cells such as the "Background +Jobs" and "Background Migrations" pages. + +## 2. Data flow + +## 3. Proposal + +We will need to decide how to handle these exceptions with a few possible +options: + +1. Move all these pages out into a dedicated per-cell Admin section. Probably + the URL will need to be routable to a single Cell like `/cells/<cell_id>/admin`, + then we can display this data per Cell. These pages will be distinct from + other Admin pages which control settings that are shared across all Cells. We + will also need to consider how this impacts self-managed customers and + whether, or not, this should be visible for single-cell instances of GitLab. +1. Build some aggregation interfaces for this data so that it can be fetched + from all Cells and presented in a single UI. This may be beneficial to an + administrator that needs to see and filter all data at a glance, especially + when they don't know which Cell the data is on. The downside, however, is + that building this kind of aggregation is very tricky when all the Cells are + designed to be totally independent, and it does also enforce more strict + requirements on compatibility between Cells. + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-agent-for-kubernetes.md b/doc/architecture/blueprints/cells/cells-feature-agent-for-kubernetes.md new file mode 100644 index 00000000000..37347cf836d --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-agent-for-kubernetes.md @@ -0,0 +1,30 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Agent for Kubernetes' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Agent for Kubernetes + +> TL;DR + +## 1. Definition + +## 2. Data flow + +## 3. Proposal + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-backups.md b/doc/architecture/blueprints/cells/cells-feature-backups.md new file mode 100644 index 00000000000..d596bdd2078 --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-backups.md @@ -0,0 +1,62 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Backups' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Backups + +Each cells will take its own backups, and consequently have its own isolated +backup / restore procedure. + +## 1. Definition + +GitLab Backup takes a backup of the PostgreSQL database used by the application, +and also Git repository data. + +## 2. Data flow + +Each cell has a number of application databases to back up (e.g. `main`, and `ci`). + +Additionally, there may be cluster-wide metadata tables (e.g. `users` table) +which is directly accesible via PostgreSQL. + +## 3. Proposal + +### 3.1. Cluster-wide metadata + +It is currently unknown how cluster-wide metadata tables will be accessible. We +may choose to have cluster-wide metadata tables backed up separately, or have +each cell back up its copy of cluster-wide metdata tables. + +### 3.2 Consistency + +#### 3.2.1 Take backups independently + +As each cell will communicate with each other via API, and there will be no joins +to the users table, it should be acceptable for each cell to take a backup +independently of each other. + +#### 3.2.2 Enforce snapshots + +We can require that each cell take a snapshot for the PostgreSQL databases at +around the same time to allow for a consistent-enough backup. + +## 4. Evaluation + +As the number of cells increases, it will likely not be feasible to take a +snapshot at the same time for all cells. Hence taking backups independently is +the better option. + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-ci-runners.md b/doc/architecture/blueprints/cells/cells-feature-ci-runners.md new file mode 100644 index 00000000000..e352be17dd3 --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-ci-runners.md @@ -0,0 +1,170 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: CI Runners' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: CI Runners + +GitLab in order to execute CI jobs [GitLab Runner](https://gitlab.com/gitlab-org/gitlab-runner/), +very often managed by customer in their infrastructure. + +All CI jobs created as part of CI pipeline are run in a context of project +it poses a challenge how to manage GitLab Runners. + +## 1. Definition + +There are 3 different types of runners: + +- instance-wide: runners that are registered globally with specific tags (selection criteria) +- group runners: runners that execute jobs from a given top-level group or subprojects of that group +- project runners: runners that execute jobs from projects or many projects: some runners might + have projects assigned from projects in different top-level groups. + +This alongside with existing data structure where `ci_runners` is a table describing +all types of runners poses a challenge how the `ci_runners` should be managed in a Cells environment. + +## 2. Data flow + +GitLab Runners use a set of globally scoped endpoints to: + +- registration of a new runner via registration token `https://gitlab.com/api/v4/runners` + ([subject for removal](../runner_tokens/index.md)) (`registration token`) +- requests jobs via an authenticated `https://gitlab.com/api/v4/jobs/request` endpoint (`runner token`) +- upload job status via `https://gitlab.com/api/v4/jobs/:job_id` (`build token`) +- upload trace via `https://gitlab.com/api/v4/jobs/:job_id/trace` (`build token`) +- download and upload artifacts via `https://gitlab.com/api/v4/jobs/:job_id/artifacts` (`build token`) + +Currently three types of authentication tokens are used: + +- runner registration token ([subject for removal](../runner_tokens/index.md)) +- runner token representing an registered runner in a system with specific configuration (`tags`, `locked`, etc.) +- build token representing an ephemeral token giving a limited access to updating a specific + job, uploading artifacts, downloading dependent artifacts, downloading and uploading + container registry images + +Each of those endpoints do receive an authentication token via header (`JOB-TOKEN` for `/trace`) +or body parameter (`token` all other endpoints). + +Since the CI pipeline would be created in a context of a specific Cell it would be required +that pick of a build would have to be processed by that particular Cell. This requires +that build picking depending on a solution would have to be either: + +- routed to correct Cell for a first time +- be made to be two phase: request build from global pool, claim build on a specific Cell using a Cell specific URL + +## 3. Proposal + +This section describes various proposals. Reader should consider that those +proposals do describe solutions for different problems. Many or some aspects +of those proposals might be the solution to the stated problem. + +### 3.1. Authentication tokens + +Even though the paths for CI Runners are not routable they can be made routable with +those two possible solutions: + +- The `https://gitlab.com/api/v4/jobs/request` uses a long polling mechanism with + a ticketing mechanism (based on `X-GitLab-Last-Update` header). Runner when first + starts sends a request to GitLab to which GitLab responds with either a build to pick + by runner. This value is completely controlled by GitLab. This allows GitLab + to use JWT or any other means to encode `cell` identifier that could be easily + decodable by Router. +- The majority of communication (in terms of volume) is using `build token` making it + the easiest target to change since GitLab is sole owner of the token that Runner later + uses for specific job. There were prior discussions about not storing `build token` + but rather using `JWT` token with defined scopes. Such token could encode the `cell` + to which router could easily route all requests. + +### 3.2. Request body + +- The most of used endpoints pass authentication token in request body. It might be desired + to use HTTP Headers as an easier way to access this information by Router without + a need to proxy requests. + +### 3.3. Instance-wide are Cell local + +We can pick a design where all runners are always registered and local to a given Cell: + +- Each Cell has it's own set of instance-wide runners that are updated at it's own pace +- The project runners can only be linked to projects from the same organization + creating strong isolation. +- In this model the `ci_runners` table is local to the Cell. +- In this model we would require the above endpoints to be scoped to a Cell in some way + or made routable. It might be via prefixing them, adding additional Cell parameter, + or providing much more robust way to decode runner token and match it to Cell. +- If routable token is used, we could move away from cryptographic random stored in + database to rather prefer to use JWT tokens that would encode +- The Admin Area showing registered Runners would have to be scoped to a Cell + +This model might be desired since it provides strong isolation guarantees. +This model does significantly increase maintenance overhead since each Cell is managed +separately. + +This model may require adjustments to runner tags feature so that projects have consistent runner experience across cells. + +### 3.4. Instance-wide are cluster-wide + +Contrary to proposal where all runners are Cell local, we can consider that runners +are global, or just instance-wide runners are global. + +However, this requires significant overhaul of system and to change the following aspects: + +- `ci_runners` table would likely have to be split decomposed into `ci_instance_runners`, ... +- all interfaces would have to be adopted to use correct table +- build queuing would have to be reworked to be two phase where each Cell would know of all pending + and running builds, but the actual claim of a build would happen against a Cell containing data +- likely `ci_pending_builds` and `ci_running_builds` would have to be made `cluster-wide` tables + increasing likelihood of creating hotspots in a system related to CI queueing + +This model makes it complex to implement from engineering side. Does make some data being shared +between Cells. Creates hotspots / scalability issues in a system (ex. during abuse) that +might impact experience of organizations on other Cells. + +### 3.5. GitLab CI Daemon + +Another potential solution to explore is to have a dedicated service responsible for builds queueing +owning it's database and working in a model of either sharded or celled service. There were prior +discussions about [CI/CD Daemon](https://gitlab.com/gitlab-org/gitlab/-/issues/19435). + +If the service would be sharded: + +- depending on a model if runners are cluster-wide or cell-local this service would have to fetch + data from all Cells +- if the sharded service would be used we could adapt a model of either sharing database containing + `ci_pending_builds/ci_running_builds` with the service +- if the sharded service would be used we could consider a push model where each Cell pushes to CI/CD Daemon + builds that should be picked by Runner +- the sharded service would be aware which Cell is responsible for processing the given build and could + route processing requests to designated Cell + +If the service would be celled: + +- all expectations of routable endpoints are still valid + +In general usage of CI Daemon does not help significantly with the stated problem. However, this offers +a few upsides related to more efficient processing and decoupling model: push model and it opens a way +to offer stateful communication with GitLab Runners (ex. gRPC or Websockets). + +## 4. Evaluation + +Considering all solutions it appears that solution giving the most promise is: + +- use "instance-wide are Cell local" +- refine endpoints to have routable identities (either via specific paths, or better tokens) + +Other potential upsides is to get rid of `ci_builds.token` and rather use a `JWT token` +that can much better and easier encode wider set of scopes allowed by CI runner. + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-container-registry.md b/doc/architecture/blueprints/cells/cells-feature-container-registry.md new file mode 100644 index 00000000000..a5761808941 --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-container-registry.md @@ -0,0 +1,132 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Container Registry' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Container Registry + +GitLab Container Registry is a feature allowing to store Docker Container Images +in GitLab. You can read about GitLab integration [here](../../../user/packages/container_registry/index.md). + +## 1. Definition + +GitLab Container Registry is a complex service requiring usage of PostgreSQL, Redis +and Object Storage dependencies. Right now there's undergoing work to introduce +[Container Registry Metadata](../container_registry_metadata_database/index.md) +to optimize data storage and image retention policies of Container Registry. + +GitLab Container Registry is serving as a container for stored data, +but on it's own does not authenticate `docker login`. The `docker login` +is executed with user credentials (can be `personal access token`) +or CI build credentials (ephemeral `ci_builds.token`). + +Container Registry uses data deduplication. It means that the same blob +(image layer) that is shared between many projects is stored only once. +Each layer is hashed by `sha256`. + +The `docker login` does request JWT time-limited authentication token that +is signed by GitLab, but validated by Container Registry service. The JWT +token does store all authorized scopes (`container repository images`) +and operation types (`push` or `pull`). A single JWT authentication token +can be have many authorized scopes. This allows container registry and client +to mount existing blobs from another scopes. GitLab responds only with +authorized scopes. Then it is up to GitLab Container Registry to validate +if the given operation can be performed. + +The GitLab.com pages are always scoped to project. Each project can have many +container registry images attached. + +Currently in case of GitLab.com the actual registry service is served +via `https://registry.gitlab.com`. + +The main identifiable problems are: + +- the authentication request (`https://gitlab.com/jwt/auth`) that is processed by GitLab.com +- the `https://registry.gitlab.com` that is run by external service and uses it's own data store +- the data deduplication, the Cells architecture with registry run in a Cell would reduce + efficiency of data storage + +## 2. Data flow + +### 2.1. Authorization request that is send by `docker login` + +```shell +curl \ + --user "username:password" \ + "https://gitlab/jwt/auth?client_id=docker&offline_token=true&service=container_registry&scope=repository:gitlab-org/gitlab-build-images:push,pull" +``` + +Result is encoded and signed JWT token. Second base64 encoded string (split by `.`) contains JSON with authorized scopes. + +```json +{"auth_type":"none","access":[{"type":"repository","name":"gitlab-org/gitlab-build-images","actions":["pull"]}],"jti":"61ca2459-091c-4496-a3cf-01bac51d4dc8","aud":"container_registry","iss":"omnibus-gitlab-issuer","iat":1669309469,"nbf":166} +``` + +### 2.2. Docker client fetching tags + +```shell +curl \ + -H "Accept: application/vnd.docker.distribution.manifest.v2+json" \ + -H "Authorization: Bearer token" \ + https://registry.gitlab.com/v2/gitlab-org/gitlab-build-images/tags/list + +curl \ + -H "Accept: application/vnd.docker.distribution.manifest.v2+json" \ + -H "Authorization: Bearer token" \ + https://registry.gitlab.com/v2/gitlab-org/gitlab-build-images/manifests/danger-ruby-2.6.6 +``` + +### 2.3. Docker client fetching blobs and manifests + +```shell +curl \ + -H "Accept: application/vnd.docker.distribution.manifest.v2+json" \ + -H "Authorization: Bearer token" \ + https://registry.gitlab.com/v2/gitlab-org/gitlab-build-images/blobs/sha256:a3f2e1afa377d20897e08a85cae089393daa0ec019feab3851d592248674b416 +``` + +## 3. Proposal + +### 3.1. Shard Container Registry separately to Cells architecture + +Due to it's architecture it extensive architecture and in general highly scalable +horizontal architecture it should be evaluated if the GitLab Container Registry +should be run not in Cell, but in a Cluster and be scaled independently. + +This might be easier, but would definitely not offer the same amount of data isolation. + +### 3.2. Run Container Registry within a Cell + +It appears that except `/jwt/auth` which would likely have to be processed by Router +(to decode `scope`) the container registry could be run as a local service of a Cell. + +The actual data at least in case of GitLab.com is not forwarded via registry, +but rather served directly from Object Storage / CDN. + +Its design encodes container repository image in a URL that is easily routable. +It appears that we could re-use the same stateless Router service in front of Container Registry +to serve manifests and blobs redirect. + +The only downside is increased complexity of managing standalone registry for each Cell, +but this might be desired approach. + +## 4. Evaluation + +There do not seem any theoretical problems with running GitLab Container Registry in a Cell. +Service seems that can be easily made routable to work well. + +The practical complexities are around managing complex service from infrastructure side. + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-contributions-forks.md b/doc/architecture/blueprints/cells/cells-feature-contributions-forks.md new file mode 100644 index 00000000000..3e498c24144 --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-contributions-forks.md @@ -0,0 +1,121 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Contributions: Forks' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Contributions: Forks + +[Forking workflow](../../../user/project/repository/forking_workflow.md) allows users +to copy existing project sources into their own namespace of choice (personal or group). + +## 1. Definition + +[Forking workflow](../../../user/project/repository/forking_workflow.md) is common workflow +with various usage patterns: + +- allows users to contribute back to upstream project +- persist repositories into their personal namespace +- copy to make changes and release as modified project + +Forks allow users not having write access to parent project to make changes. The forking workflow +is especially important for the Open Source community which is able to contribute back +to public projects. However, it is equally important in some companies which prefer the strong split +of responsibilites and tighter access control. The access to project is restricted +to designated list of developers. + +Forks enable: + +- tigther control of who can modify the upstream project +- split of the responsibilites: parent project might use CI configuration connecting to production systems +- run CI pipelines in context of fork in much more restrictive environment +- consider all forks to be unveted which reduces risks of leaking secrets, or any other information + tied with the project + +The forking model is problematic in Cells architecture for following reasons: + +- Forks are clones of existing repositories, forks could be created across different organizations, Cells and Gitaly shards. +- User can create merge request and contribute back to upstream project, this upstream project might in a different organization and Cell. +- The merge request CI pipeline is to executed in a context of source project, but presented in a context of target project. + +## 2. Data flow + +## 3. Proposals + +### 3.1. Intra-Cluster forks + +This proposal makes us to implement forks as a intra-ClusterCell forks where communication is done via API +between all trusted Cells of a cluster: + +- Forks when created, they are created always in context of user choice of group. +- Forks are isolated from Organization. +- Organization or group owner could disable forking across organizations or forking in general. +- When a Merge Request is created it is created in context of target project, referencing + external project on another Cell. +- To target project the merge reference is transfered that is used for presenting information + in context of target project. +- CI pipeline is fetched in context of source project as it-is today, the result is fetched into + Merge Request of target project. +- The Cell holding target project internally uses GraphQL to fetch status of source project + and include in context of the information for merge request. + +Upsides: + +- All existing forks continue to work as-is, as they are treated as intra-Cluster forks. + +Downsides: + +- The purpose of Organizations is to provide strong isolation between organizations + allowing to fork across does break security boundaries. +- However, this is no different to ability of users today to clone repository to local computer + and push it to any repository of choice. +- Access control of source project can be lower than those of target project. System today + requires that in order to contribute back the access level needs to be the same for fork and upstream. + +### 3.2. Forks are created in a personal namespace of the current organization + +Instead of creating projects across organizations, the forks are created in a user personal namespace +tied with the organization. Example: + +- Each user that is part of organization receives their personal namespace. For example for `GitLab Inc.` + it could be `gitlab.com/organization/gitlab-inc/@ayufan`. +- The user has to fork into it's own personal namespace of the organization. +- The user has that many personal namespaces as many organizations it belongs to. +- The personal namespace behaves similar to currently offered personal namespace. +- The user can manage and create projects within a personal namespace. +- The organization can prevent or disable usage of personal namespaces disallowing forks. +- All current forks are migrated into personal namespace of user in Organization. +- All forks are part of to the organization. +- The forks are not federated features. +- The personal namespace and forked project do not share configuration with parent project. + +### 3.3. Forks are created as internal projects under current project + +Instead of creating projects across organizations, the forks are attachments to existing projects. +Each user forking a project receives their unique project. Example: + +- For project: `gitlab.com/gitlab-org/gitlab`, forks would be created in `gitlab.com/gitlab-org/gitlab/@kamil-gitlab`. +- Forks are created in a context of current organization, they do not cross organization boundaries + and are managed by the organization. +- Tied to the user (or any other user-provided name of the fork). +- The forks are not federated features. + +Downsides: + +- Does not answer how to handle and migrate all exisiting forks. +- Might share current group / project settings - breaking some security boundaries. + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-dashboard.md b/doc/architecture/blueprints/cells/cells-feature-dashboard.md new file mode 100644 index 00000000000..135f69c6ed3 --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-dashboard.md @@ -0,0 +1,30 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Dashboard' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Dashboard + +> TL;DR + +## 1. Definition + +## 2. Data flow + +## 3. Proposal + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-data-migration.md b/doc/architecture/blueprints/cells/cells-feature-data-migration.md new file mode 100644 index 00000000000..ef0865b4081 --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-data-migration.md @@ -0,0 +1,131 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Data migration' +--- + +<!-- vale gitlab.FutureTense = NO --> + +DISCLAIMER: +This page may contain information related to upcoming products, features and +functionality. It is important to note that the information presented is for +informational purposes only, so please do not rely on the information for +purchasing or planning purposes. Just like with all projects, the items +mentioned on the page are subject to change or delay, and the development, +release, and timing of any products, features, or functionality remain at the +sole discretion of GitLab Inc. + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Data migration + +It is essential for Cells architecture to provide a way to migrate data out of big Cells +into smaller ones. This describes various approaches to provide this type of split. + +We also need to handle for cases where data is already violating the expected +isolation constraints of Cells (ie. references cannot span multiple +organizations). We know that existing features like linked issues allowed users +to link issues across any projects regardless of their hierarchy. There are many +similar features. All of this data will need to be migrated in some way before +it can be split across different cells. This may mean some data needs to be +deleted, or the feature changed and modelled slightly differently before we can +properly split or migrate the organizations between cells. + +Having schema deviations across different Cells, which is a necessary +consequence of different databases, will also impact our ability to migrate +data between cells. Different schemas impact our ability to reliably replicate +data across cells and especially impact our ability to validate that the data is +correctly replicated. It might force us to only be able to move data between +cells when the schemas are all in sync (slowing down deployments and the +rebalancing process) or possibly only migrate from newer to older schemas which +would be complex. + +## 1. Definition + +## 2. Data flow + +## 3. Proposal + +### 3.1. Split large Cells + +A single Cell can only be divided into many Cells. This is based on principle +that it is easier to create exact clone of an existing Cell in many replicas +out of which some will be made authoritative once migrated. Keeping those +replicas up-to date with Cell 0 is also much easier due to pre-existing +replication solutions that can replicate the whole systems: Geo, PostgreSQL +physical replication, etc. + +1. All data of an organization needs to not be divided across many Cells. +1. Split should be doable online. +1. New Cells cannot contain pre-existing data. +1. N Cells contain exact replica of Cell 0. +1. The data of Cell 0 is live replicated to as many Cells it needs to be split. +1. Once consensus is achieved between Cell 0 and N-Cells the organizations to be migrated away + are marked as read-only cluster-wide. +1. The `routes` is updated on for all organizations to be split to indicate an authoritative + Cell holding the most recent data, like `gitlab-org` on `cell-100`. +1. The data for `gitlab-org` on Cell 0, and on other non-authoritative N-Cells are dormant + and will be removed in the future. +1. All accesses to `gitlab-org` on a given Cell are validated about `cell_id` of `routes` + to ensure that given Cell is authoritative to handle the data. + +#### More challenges of this proposal + +1. There is no streaming replication capability for Elasticsearch, but you could + snapshot the whole Elasticsearch index and recreate, but this takes hours. + It could be handled by pausing Elasticsearch indexing on the initial cell during + the migration as indexing downtime is not a big issue, but this still needs + to be coordinated with the migration process +1. Syncing Redis, Gitaly, CI Postgres, Main Postgres, registry Postgres, other + new data stores snapshots in an online system would likely lead to gaps + without a long downtime. You need to choose a sync point and at the sync + point you need to stop writes to perform the migration. The more data stores + there are to migrate at the same time the longer the write downtime for the + failover. We would also need to find a reliable place in the application to + actually block updates to all these systems with a high degree of + confidence. In the past we've only been confident by shutting down all rails + services because any rails process could write directly to any of these at + any time due to async workloads or other surprising code paths. +1. How to efficiently delete all the orphaned data. Locating all `ci_builds` + associated with half the organizations would be very expensive if we have to + do joins. We haven't yet determined if we'd want to store an `organization_id` + column on every table, but this is the kind of thing it would be helpful for. + +### 3.2. Migrate organization from an existing Cell + +This is different to split, as we intend to perform logical and selective replication +of data belonging to a single organization. + +Today this type of selective replication is only implemented by Gitaly where we can migrate +Git repository from a single Gitaly node to another with minimal downtime. + +In this model we would require identifying all resources belonging to a given organization: +database rows, object storage files, Git repositories, etc. and selectively copy them over +to another (likely) existing Cell importing data into it. Ideally ensuring that we can +perform logical replication live of all changed data, but change similarly to split +which Cell is authoritative for this organization. + +1. It is hard to identify all resources belonging to organization. +1. It requires either downtime for organization or a robust system to identify + live changes made. +1. It likely will require a full database structure analysis (more robust than project import/export) + to perform selective PostgreSQL logical replication. + +#### More challenges of this proposal + +1. Logical replication is still not performant enough to keep up with our + scale. Even if we could use logical replication we still don't have an + efficient way to filter data related to a single organization without + joining all the way to the `organizations` table which will slow down + logical replication dramatically. + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-database-sequences.md b/doc/architecture/blueprints/cells/cells-feature-database-sequences.md new file mode 100644 index 00000000000..d94dc3be864 --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-database-sequences.md @@ -0,0 +1,95 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Database Sequences' +--- + +<!-- vale gitlab.FutureTense = NO --> + +DISCLAIMER: +This page may contain information related to upcoming products, features and +functionality. It is important to note that the information presented is for +informational purposes only, so please do not rely on the information for +purchasing or planning purposes. Just like with all projects, the items +mentioned on the page are subject to change or delay, and the development, +release, and timing of any products, features, or functionality remain at the +sole discretion of GitLab Inc. + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Database Sequences + +GitLab today ensures that every database row create has unique ID, allowing +to access Merge Request, CI Job or Project by a known global ID. + +Cells will use many distinct and not connected databases, each of them having +a separate IDs for most of entities. + +It might be desirable to retain globally unique IDs for all database rows +to allow migrating resources between Cells in the future. + +## 1. Definition + +## 2. Data flow + +## 3. Proposal + +This are some preliminary ideas how we can retain unique IDs across the system. + +### 3.1. UUID + +Instead of using incremental sequences use UUID (128 bit) that is stored in database. + +- This might break existing IDs and requires adding UUID column for all existing tables. +- This makes all indexes larger as it requires storing 128 bit instead of 32/64 bit in index. + +### 3.2. Use Cell index encoded in ID + +Since significant number of tables already use 64 bit ID numbers we could use MSB to encode +Cell ID effectively enabling + +- This might limit amount of Cells that can be enabled in system, as we might decide to only + allocate 1024 possible Cell numbers. +- This might make IDs to be migratable between Cells, since even if entity from Cell 1 is migrated to Cell 100 + this ID would still be unique. +- If resources are migrated the ID itself will not be enough to decode Cell number and we would need + lookup table. +- This requires updating all IDs to 32 bits. + +### 3.3. Allocate sequence ranges from central place + +Each Cell might receive its own range of the sequences as they are consumed from a centrally managed place. +Once Cell consumes all IDs assigned for a given table it would be replenished and a next range would be allocated. +Ranges would be tracked to provide a faster lookup table if a random access pattern is required. + +- This might make IDs to be migratable between Cells, since even if entity from Cell 1 is migrated to Cell 100 + this ID would still be unique. +- If resources are migrated the ID itself will not be enough to decode Cell number and we would need + much more robust lookup table as we could be breaking previously assigned sequence ranges. +- This does not require updating all IDs to 64 bits. +- This adds some performance penalty to all `INSERT` statements in Postgres or at least from Rails as we need to check for the sequence number and potentially wait for our range to be refreshed from the ID server +- The available range will need to be stored and incremented in a centralized place so that concurrent transactions cannot possibly get the same value. + +### 3.4. Define only some tables to require unique IDs + +Maybe this is acceptable only for some tables to have a globally unique IDs. It could be projects, groups +and other top-level entities. All other tables like `merge_requests` would only offer Cell-local ID, +but when referenced outside it would rather use IID (an ID that is monotonic in context of a given resource, like project). + +- This makes the ID 10000 for `merge_requests` be present on all Cells, which might be sometimes confusing + as for uniqueness of the resource. +- This might make random access by ID (if ever needed) be impossible without using composite key, like: `project_id+merge_request_id`. +- This would require us to implement a transformation/generation of new ID if we need to migrate records to another cell. This can lead to very difficult migration processes when these IDs are also used as foreign keys for other records being migrated. +- If IDs need to change when moving between cells this means that any links to records by ID would no longer work even if those links included the `project_id`. +- If we plan to allow these ids to not be unique and change the unique constraint to be based on a composite key then we'd need to update all foreign key references to be based on the composite key + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-git-access.md b/doc/architecture/blueprints/cells/cells-feature-git-access.md new file mode 100644 index 00000000000..70b3f136904 --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-git-access.md @@ -0,0 +1,164 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Git Access' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Git Access + +This document describes impact of Cells architecture on all Git access (over HTTPS and SSH) +patterns providing explanation of how potentially those features should be changed +to work well with Cells. + +## 1. Definition + +Git access is done through out the application. It can be an operation performed by the system +(read Git repository) or by user (create a new file via Web IDE, `git clone` or `git push` via command line). + +The Cells architecture defines that all Git repositories will be local to the Cell, +so no repository could be shared with another Cell. + +The Cells architecture will require that any Git operation done can only be handled by a Cell holding +the data. It means that any operation either via Web interface, API, or GraphQL needs to be routed +to the correct Cell. It means that any `git clone` or `git push` operation can only be performed +in a context of a Cell. + +## 2. Data flow + +The are various operations performed today by the GitLab on a Git repository. This describes +the data flow how they behave today to better represent the impact. + +It appears that Git access does require changes only to a few endpoints that are scoped to project. +There appear to be different types of repositories: + +- Project: assigned to Group +- Wiki: additional repository assigned to Project +- Design: similar to Wiki, additional repository assigned to Project +- Snippet: creates a virtual project to hold repository, likely tied to the User + +### 2.1. Git clone over HTTPS + +Execution of: `git clone` over HTTPS + +```mermaid +sequenceDiagram + User ->> Workhorse: GET /gitlab-org/gitlab.git/info/refs?service=git-upload-pack + Workhorse ->> Rails: GET /gitlab-org/gitlab.git/info/refs?service=git-upload-pack + Rails ->> Workhorse: 200 OK + Workhorse ->> Gitaly: RPC InfoRefsUploadPack + Gitaly ->> User: Response + User ->> Workhorse: POST /gitlab-org/gitlab.git/git-upload-pack + Workhorse ->> Gitaly: RPC PostUploadPackWithSidechannel + Gitaly ->> User: Response +``` + +### 2.2. Git clone over SSH + +Execution of: `git clone` over SSH + +```mermaid +sequenceDiagram + User ->> Git SSHD: ssh git@gitlab.com + Git SSHD ->> Rails: GET /api/v4/internal/authorized_keys + Rails ->> Git SSHD: 200 OK (list of accepted SSH keys) + Git SSHD ->> User: Accept SSH + User ->> Git SSHD: git clone over SSH + Git SSHD ->> Rails: POST /api/v4/internal/allowed?project=/gitlab-org/gitlab.git&service=git-upload-pack + Rails ->> Git SSHD: 200 OK + Git SSHD ->> Gitaly: RPC SSHUploadPackWithSidechannel + Gitaly ->> User: Response +``` + +### 2.3. Git push over HTTPS + +Execution of: `git push` over HTTPS + +```mermaid +sequenceDiagram + User ->> Workhorse: GET /gitlab-org/gitlab.git/info/refs?service=git-receive-pack + Workhorse ->> Rails: GET /gitlab-org/gitlab.git/info/refs?service=git-receive-pack + Rails ->> Workhorse: 200 OK + Workhorse ->> Gitaly: RPC PostReceivePack + Gitaly ->> Rails: POST /api/v4/internal/allowed?gl_repository=project-111&service=git-receive-pack + Gitaly ->> Rails: POST /api/v4/internal/pre_receive?gl_repository=project-111 + Gitaly ->> Rails: POST /api/v4/internal/post_receive?gl_repository=project-111 + Gitaly ->> User: Response +``` + +### 2.4. Git push over SSHD + +Execution of: `git clone` over SSH + +```mermaid +sequenceDiagram + User ->> Git SSHD: ssh git@gitlab.com + Git SSHD ->> Rails: GET /api/v4/internal/authorized_keys + Rails ->> Git SSHD: 200 OK (list of accepted SSH keys) + Git SSHD ->> User: Accept SSH + User ->> Git SSHD: git clone over SSH + Git SSHD ->> Rails: POST /api/v4/internal/allowed?project=/gitlab-org/gitlab.git&service=git-receive-pack + Rails ->> Git SSHD: 200 OK + Git SSHD ->> Gitaly: RPC ReceivePack + Gitaly ->> Rails: POST /api/v4/internal/allowed?gl_repository=project-111 + Gitaly ->> Rails: POST /api/v4/internal/pre_receive?gl_repository=project-111 + Gitaly ->> Rails: POST /api/v4/internal/post_receive?gl_repository=project-111 + Gitaly ->> User: Response +``` + +### 2.5. Create commit via Web + +Execution of `Add CHANGELOG` to repository: + +```mermaid +sequenceDiagram + Web ->> Puma: POST /gitlab-org/gitlab/-/create/main + Puma ->> Gitaly: RPC TreeEntry + Gitaly ->> Rails: POST /api/v4/internal/allowed?gl_repository=project-111 + Gitaly ->> Rails: POST /api/v4/internal/pre_receive?gl_repository=project-111 + Gitaly ->> Rails: POST /api/v4/internal/post_receive?gl_repository=project-111 + Gitaly ->> Puma: Response + Puma ->> Web: See CHANGELOG +``` + +## 3. Proposal + +The Cells stateless router proposal requires that any ambiguous path (that is not routable) +will be made to be routable. It means that at least the following paths will have to be updated +do introduce a routable entity (project, group, or organization). + +Change: + +- `/api/v4/internal/allowed` => `/api/v4/internal/projects/<gl_repository>/allowed` +- `/api/v4/internal/pre_receive` => `/api/v4/internal/projects/<gl_repository>/pre_receive` +- `/api/v4/internal/post_receive` => `/api/v4/internal/projects/<gl_repository>/post_receive` +- `/api/v4/internal/lfs_authenticate` => `/api/v4/internal/projects/<gl_repository>/lfs_authenticate` + +Where: + +- `gl_repository` can be `project-1111` (`Gitlab::GlRepository`) +- `gl_repository` in some cases might be a full path to repository as executed by GitLab Shell (`/gitlab-org/gitlab.git`) + +## 4. Evaluation + +Supporting Git repositories if a Cell can access only its own repositories does not appear to be complex. + +The one major complication is supporting snippets, but this likely falls in the same category as for the approach +to support user's personal namespaces. + +## 4.1. Pros + +1. The API used for supporting HTTPS/SSH and Hooks are well defined and can easily be made routable. + +## 4.2. Cons + +1. The sharing of repositories objects is limited to the given Cell and Gitaly node. +1. The across-Cells forks are likely impossible to be supported (discover: how this work today across different Gitaly node). diff --git a/doc/architecture/blueprints/cells/cells-feature-gitlab-pages.md b/doc/architecture/blueprints/cells/cells-feature-gitlab-pages.md new file mode 100644 index 00000000000..7e4ab785095 --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-gitlab-pages.md @@ -0,0 +1,30 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: GitLab Pages' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: GitLab Pages + +> TL;DR + +## 1. Definition + +## 2. Data flow + +## 3. Proposal + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-global-search.md b/doc/architecture/blueprints/cells/cells-feature-global-search.md new file mode 100644 index 00000000000..c1e2b93bc2d --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-global-search.md @@ -0,0 +1,48 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Global search' +--- + +<!-- vale gitlab.FutureTense = NO --> + +DISCLAIMER: +This page may contain information related to upcoming products, features and +functionality. It is important to note that the information presented is for +informational purposes only, so please do not rely on the information for +purchasing or planning purposes. Just like with all projects, the items +mentioned on the page are subject to change or delay, and the development, +release, and timing of any products, features, or functionality remain at the +sole discretion of GitLab Inc. + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Global search + +When we introduce multiple Cells we intend to isolate all services related to +those Cells. This will include Elasticsearch which means our current global +search functionality will not work. It may be possible to implement aggregated +search across all cells, but it is unlikely to be performant to do fan-out +searches across all cells especially once you start to do pagination which +requires setting the correct offset and page number for each search. + +## 1. Definition + +## 2. Data flow + +## 3. Proposal + +Likely first versions of Cells will simply not support global searches and then +we may later consider if building global searches to support popular use cases +is worthwhile. + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-graphql.md b/doc/architecture/blueprints/cells/cells-feature-graphql.md new file mode 100644 index 00000000000..d936a1b81ba --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-graphql.md @@ -0,0 +1,95 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: GraphQL' +--- + +<!-- vale gitlab.FutureTense = NO --> + +DISCLAIMER: +This page may contain information related to upcoming products, features and +functionality. It is important to note that the information presented is for +informational purposes only, so please do not rely on the information for +purchasing or planning purposes. Just like with all projects, the items +mentioned on the page are subject to change or delay, and the development, +release, and timing of any products, features, or functionality remain at the +sole discretion of GitLab Inc. + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: GraphQL + +GitLab extensively uses GraphQL to perform efficient data query operations. +GraphQL due to it's nature is not directly routable. The way how GitLab uses +it calls the `/api/graphql` endpoint, and only query or mutation of body request +might define where the data can be accessed. + +## 1. Definition + +## 2. Data flow + +## 3. Proposal + +There are at least two main ways to implement GraphQL in Cells architecture. + +### 3.1. GraphQL routable by endpoint + +Change `/api/graphql` to `/api/organization/<organization>/graphql`. + +- This breaks all existing usages of `/api/graphql` endpoint + since the API URI is changed. + +### 3.2. GraphQL routable by body + +As part of router parse GraphQL body to find a routable entity, like `project`. + +- This still makes the GraphQL query be executed only in context of a given Cell + and not allowing the data to be merged. + +```json +# Good example +{ + project(fullPath:"gitlab-org/gitlab") { + id + description + } +} + +# Bad example, since Merge Request is not routable +{ + mergeRequest(id: 1111) { + iid + description + } +} +``` + +### 3.3. Merging GraphQL Proxy + +Implement as part of router GraphQL Proxy which can parse body +and merge results from many Cells. + +- This might make pagination hard to achieve, or we might assume that + we execute many queries of which results are merged across all Cells. + +```json +{ + project(fullPath:"gitlab-org/gitlab"){ + id, description + } + group(fullPath:"gitlab-com") { + id, description + } +} +``` + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-organizations.md b/doc/architecture/blueprints/cells/cells-feature-organizations.md new file mode 100644 index 00000000000..03178d9e6ce --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-organizations.md @@ -0,0 +1,59 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Organizations' +--- + +<!-- vale gitlab.FutureTense = NO --> + +DISCLAIMER: +This page may contain information related to upcoming products, features and +functionality. It is important to note that the information presented is for +informational purposes only, so please do not rely on the information for +purchasing or planning purposes. Just like with all projects, the items +mentioned on the page are subject to change or delay, and the development, +release, and timing of any products, features, or functionality remain at the +sole discretion of GitLab Inc. + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Organizations + +One of the major designs of Cells architecture is strong isolation between Groups. +Organizations as described by this blueprint provides a way to have plausible UX +for joining together many Groups that are isolated from the rest of systems. + +## 1. Definition + +Cells do require that all groups and projects of a single organization can +only be stored on a single Cell since a Cell can only access data that it holds locally +and has very limited capabilities to read information from other Cells. + +Cells with Organizations do require strong isolation between organizations. + +It will have significant implications on various user-facing features, +like Todos, dropdowns allowing to select projects, references to other issues +or projects, or any other social functions present at GitLab. Today those functions +were able to reference anything in the whole system. With the introduction of +organizations such will be forbidden. + +This problem definition aims to answer effort and implications required to add +strong isolation between organizations to the system. Including features affected +and their data processing flow. The purpose is to ensure that our solution when +implemented consistently avoids data leakage between organizations residing on +a single Cell. + +## 2. Data flow + +## 3. Proposal + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-personal-namespaces.md b/doc/architecture/blueprints/cells/cells-feature-personal-namespaces.md new file mode 100644 index 00000000000..e8f5c250a8e --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-personal-namespaces.md @@ -0,0 +1,30 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Personal Namespaces' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Personal Namespaces + +> TL;DR + +## 1. Definition + +## 2. Data flow + +## 3. Proposal + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-router-endpoints-classification.md b/doc/architecture/blueprints/cells/cells-feature-router-endpoints-classification.md new file mode 100644 index 00000000000..7c2974ca258 --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-router-endpoints-classification.md @@ -0,0 +1,47 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Router Endpoints Classification' +--- + +<!-- vale gitlab.FutureTense = NO --> + +DISCLAIMER: +This page may contain information related to upcoming products, features and +functionality. It is important to note that the information presented is for +informational purposes only, so please do not rely on the information for +purchasing or planning purposes. Just like with all projects, the items +mentioned on the page are subject to change or delay, and the development, +release, and timing of any products, features, or functionality remain at the +sole discretion of GitLab Inc. + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Router Endpoints Classification + +Classification of all endpoints is essential to properly route request +hitting load balancer of a GitLab installation to a Cell that can serve it. + +Each Cell should be able to decode each request and classify for which Cell +it belongs to. + +GitLab currently implements hundreds of endpoints. This document tries +to describe various techniques that can be implemented to allow the Rails +to provide this information efficiently. + +## 1. Definition + +## 2. Data flow + +## 3. Proposal + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-schema-changes.md b/doc/architecture/blueprints/cells/cells-feature-schema-changes.md new file mode 100644 index 00000000000..d712b24a8a0 --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-schema-changes.md @@ -0,0 +1,56 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Schema changes' +--- + +<!-- vale gitlab.FutureTense = NO --> + +DISCLAIMER: +This page may contain information related to upcoming products, features and +functionality. It is important to note that the information presented is for +informational purposes only, so please do not rely on the information for +purchasing or planning purposes. Just like with all projects, the items +mentioned on the page are subject to change or delay, and the development, +release, and timing of any products, features, or functionality remain at the +sole discretion of GitLab Inc. + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Schema changes + +When we introduce multiple Cells that own their own databases this will +complicate the process of making schema changes to Postgres and Elasticsearch. +Today we already need to be careful to make changes comply with our zero +downtime deployments. For example, +[when removing a column we need to make changes over 3 separate deployments](../../../development/database/avoiding_downtime_in_migrations.md#dropping-columns). +We have tooling like `post_migrate` that helps with these kinds of changes to +reduce the number of merge requests needed, but these will be complicated when +we are dealing with deploying multiple rails applications that will be at +different versions at any one time. This problem will be particularly tricky to +solve for shared databases like our plan to share the `users` related tables +among all Cells. + +A key benefit of Cells may be that it allows us to run different +customers on different versions of GitLab. We may choose to update our own cell +before all our customers giving us even more flexibility than our current +canary architecture. But doing this means that schema changes need to have even +more versions of backward compatibility support which could slow down +development as we need extra steps to make schema changes. + +## 1. Definition + +## 2. Data flow + +## 3. Proposal + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-secrets.md b/doc/architecture/blueprints/cells/cells-feature-secrets.md new file mode 100644 index 00000000000..20260c89ccd --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-secrets.md @@ -0,0 +1,49 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Secrets' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Secrets + +Where possible, each cell should have its own distinct set of secrets. +However, there will be some secrets that will be required to be the same for all +cells in the cluster + +## 1. Definition + +GitLab has a lot of +[secrets](https://docs.gitlab.com/charts/installation/secrets.html) that needs +to be configured. + +Some secrets are for inter-component communication, e.g. `GitLab Shell secret`, +and used only within a cell. + +Some secrets are used for features, e.g. `ci_jwt_signing_key`. + +## 2. Data flow + +## 3. Proposal + +1. Secrets used for features will need to be consistent across all cells, so that the UX is consistent. + 1. This is especially true for the `db_key_base` secret which is used for + encrypting data at rest in the database - so that projects that are + transferred to another cell will continue to work. We do not want to have + to re-encrypt such rows when we move projects/groups between cells. +1. Secrets which are used for intra-cell communication only should be uniquely generated + per-cell. + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-snippets.md b/doc/architecture/blueprints/cells/cells-feature-snippets.md new file mode 100644 index 00000000000..f5e72c0e3a0 --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-snippets.md @@ -0,0 +1,30 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Snippets' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Snippets + +> TL;DR + +## 1. Definition + +## 2. Data flow + +## 3. Proposal + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-template.md b/doc/architecture/blueprints/cells/cells-feature-template.md new file mode 100644 index 00000000000..3cece3dc99e --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-template.md @@ -0,0 +1,30 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Problem A' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: A + +> TL;DR + +## 1. Definition + +## 2. Data flow + +## 3. Proposal + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/cells-feature-uploads.md b/doc/architecture/blueprints/cells/cells-feature-uploads.md new file mode 100644 index 00000000000..fdac3a9977c --- /dev/null +++ b/doc/architecture/blueprints/cells/cells-feature-uploads.md @@ -0,0 +1,30 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Uploads' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Cells: Uploads + +> TL;DR + +## 1. Definition + +## 2. Data flow + +## 3. Proposal + +## 4. Evaluation + +## 4.1. Pros + +## 4.2. Cons diff --git a/doc/architecture/blueprints/cells/glossary.md b/doc/architecture/blueprints/cells/glossary.md new file mode 100644 index 00000000000..c3ec5fd12e4 --- /dev/null +++ b/doc/architecture/blueprints/cells/glossary.md @@ -0,0 +1,106 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Glossary' +--- + +# Cells: Glossary + +We use the following terms to describe components and properties of the Cells architecture. + +## Cell + +> Pod was renamed to Cell in <https://gitlab.com/gitlab-com/www-gitlab-com/-/merge_requests/121163> + +A Cell is a set of infrastructure components that contains multiple top-level groups that belong to different organizations. The components include both datastores (PostgreSQL, Redis etc.) and stateless services (web etc.). The infrastructure components provided within a Cell are shared among organizations and their top-level groups but not shared with other Cells. This isolation of infrastructure components means that Cells are independent from each other. + +<img src="images/term-cell.png" height="200"> + +### Cell properties + +- Each cell is independent from the others +- Infrastructure components are shared by organizations and their top-level groups within a Cell +- More Cells can be provisioned to provide horizontal scalability +- A failing Cell does not lead to failure of other Cells +- Noisy neighbor effects are limited to within a Cell +- Cells are not visible to organizations; it is an implementation detail +- Cells may be located in different geographical regions (for example, EU, US, JP, UK) + +Discouraged synonyms: GitLab instance, cluster, shard + +## Cluster + +A cluster is a collection of Cells. + +<img src="images/term-cluster.png" height="300"> + +### Cluster properties + +- A cluster holds cluster-wide metadata, for example Users, Routes, Settings. + +Discouraged synonyms: whale + +## Organizations + +GitLab references [Organizations in the initial set up](../../../topics/set_up_organization.md) and users can add a (free text) organization to their profile. There is no Organization entity established in the GitLab codebase. + +As part of delivering Cells, we propose the introduction of an `organization` entity. Organizations would represent billable entities or customers. + +Organizations are a known concept, present for example in [AWS](https://docs.aws.amazon.com/whitepapers/latest/organizing-your-aws-environment/core-concepts.html) and [GCP](https://cloud.google.com/resource-manager/docs/cloud-platform-resource-hierarchy#organizations). + +Organizations work under the following assumptions: + +1. Users care about what happens within their organizations. +1. Features need to work within an organization. +1. Only few features need to work across organizations. +1. Users understand that the majority of pages they view are only scoped to a single organization at a time. +1. Organizations are located on a single cell. + + + +### Organization properties + +- Top-level groups belong to organizations +- Organizations are isolated from each other by default meaning that cross-group features will only work for group that exist within a single organization +- User namespaces must not belong to an organization + +Discouraged synonyms: Billable entities, customers + +## Top-Level group + +Top-level group is the name given to the top most group of all other groups. Groups and projects are nested underneath the top-level group. + +Example: + +`https://gitlab.com/gitlab-org/gitlab/`: + +- `gitlab-org` is a `top-level group`; the root for all groups and projects of an organization +- `gitlab` is a `project`; a project of the organization. + +The top-level group has served as the defacto Organization entity. With the creation of Organization, top-level groups will be [nested underneath Organizations](https://gitlab.com/gitlab-org/gitlab/-/issues/394796). + +Over time there won't be a distinction between a top-level group and a group. All features that make Top-level groups different from groups will move to Organization. + +Discouraged synonyms: Root-level namespace + + + +### Top-level group properties + +- Top-level groups belonging to an organization are located on the same Cell +- Top-level groups can interact with other top-level groups that belong to the same organization + +## Users + +Users are available globally and not restricted to a single Cell. Users belong to a single organization, but can participate in many organizations through group and project membership with varying permissions. Inside organizations, users can create multiple top-level groups. User activity is not limited to a single organization but their contributions (for example TODOs) are only aggregated within an organization. This avoids the need for aggregating across cells. + +### User properties + +- Users are shared globally across all Cells +- Users can create multiple top-level groups +- Users can be a member of multiple top-level groups +- Users belong to one organization. See [!395736](https://gitlab.com/gitlab-org/gitlab/-/issues/395736) +- Users can be members of groups and projects in different organizations +- Users can administer organizations +- User activity is aggregated in an organization +- Every user has one personal namespace diff --git a/doc/architecture/blueprints/cells/goals.md b/doc/architecture/blueprints/cells/goals.md new file mode 100644 index 00000000000..67dc25625c7 --- /dev/null +++ b/doc/architecture/blueprints/cells/goals.md @@ -0,0 +1,59 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Goals' +--- + +# Cells: Goals + +## Scalability + +The main goal of this new shared-infrastructure architecture is to provide additional scalability for our SaaS Platform. GitLab.com is largely monolithic and we have estimated (internal) that the current architecture has scalability limitations, even when database partitioning and decomposition are taken into account. + +Cells provide a horizontally scalable solution because additional Cells can be created based on demand. Cells can be provisioned and tuned as needed for optimal scalability. + +## Increased availability + +A major challenge for shared-infrastructure architectures is a lack of isolation between top-level groups. This can lead to noisy neighbor effects. A organization's behavior inside a top-level group can impact all other organizations. This is highly undesirable. Cells provide isolation at the cell level. A group of organizations is fully isolated from other organizations located on a different Cell. This minimizes noisy neighbor effects while still benefiting from the cost-efficiency of shared infrastructure. + +Additionally, Cells provide a way to implement disaster recovery capabilities. Entire Cells may be replicated to read-only standbys with automatic failover capabilities. + +## A consistent experience + +Organizations should have the same user experience on our SaaS platform as they do on a self-managed GitLab instance. + +## Regions + +GitLab.com is only hosted within the United States of America. Organizations located in other regions have voiced demand for local SaaS offerings. Cells provide a path towards [GitLab Regions](https://gitlab.com/groups/gitlab-org/-/epics/6037) because Cells may be deployed within different geographies. Depending on which of the organization's data is located outside a Cell, this may solve data residency and compliance problems. + +## Market segment + +Cells would provide a solution for organizations in the small to medium business (up to 100 users) and the mid-market segment (up to 2000 users). +(See [segmentation definitions](https://about.gitlab.com/handbook/sales/field-operations/gtm-resources/#segmentation).) +Larger organizations may benefit substantially from [GitLab Dedicated](../../../subscriptions/gitlab_dedicated/index.md). + +At this moment, GitLab.com has "social-network"-like capabilities that may not fit well into a more isolated organization model. Removing those features, however, possesses some challenges: + +1. How will existing `gitlab-org` contributors contribute to the namespace?? +1. How do we move existing top-level groups into the new model (effectively breaking their social features)? + +We should evaluate if the SMB and mid market segment is interested in these features, or if not having them is acceptable in most cases. + +## Self-managed + +For reasons of consistency, it is expected that self-managed instances will +adopt the cells architecture as well. To expand, self-managed instances can +continue with just a single Cell while supporting the option of adding additional +Cells. Organizations, and possible User decomposition will also be adopted for +self-managed instances. + +## High-level architecture problems to solve + +A number of technical issues need to be resolved to implement Cells (in no particular order). This section will be expanded. + +1. How are Cells provisioned? - [Design discussion](https://gitlab.com/gitlab-org/gitlab/-/issues/396641) +1. What is a Cells topology? - [Design discussion](https://gitlab.com/gitlab-org/gitlab/-/issues/396641) +1. How are users of an organization routed to the correct Cell? - +1. How do users authenticate with Cells and Organizations? - [Design discussion](https://gitlab.com/gitlab-org/gitlab/-/issues/395736) +1. How are Cells rebalanced? +1. How can Cells implement disaster recovery capabilities? diff --git a/doc/architecture/blueprints/pods/images/pods-and-fulfillment.png b/doc/architecture/blueprints/cells/images/pods-and-fulfillment.png Binary files differindex fea32d1800e..fea32d1800e 100644 --- a/doc/architecture/blueprints/pods/images/pods-and-fulfillment.png +++ b/doc/architecture/blueprints/cells/images/pods-and-fulfillment.png diff --git a/doc/architecture/blueprints/cells/images/term-cell.png b/doc/architecture/blueprints/cells/images/term-cell.png Binary files differnew file mode 100644 index 00000000000..799b2eccd95 --- /dev/null +++ b/doc/architecture/blueprints/cells/images/term-cell.png diff --git a/doc/architecture/blueprints/cells/images/term-cluster.png b/doc/architecture/blueprints/cells/images/term-cluster.png Binary files differnew file mode 100644 index 00000000000..03c92850b64 --- /dev/null +++ b/doc/architecture/blueprints/cells/images/term-cluster.png diff --git a/doc/architecture/blueprints/cells/images/term-organization.png b/doc/architecture/blueprints/cells/images/term-organization.png Binary files differnew file mode 100644 index 00000000000..dd6367ad84a --- /dev/null +++ b/doc/architecture/blueprints/cells/images/term-organization.png diff --git a/doc/architecture/blueprints/cells/images/term-top-level-group.png b/doc/architecture/blueprints/cells/images/term-top-level-group.png Binary files differnew file mode 100644 index 00000000000..4af2468f50d --- /dev/null +++ b/doc/architecture/blueprints/cells/images/term-top-level-group.png diff --git a/doc/architecture/blueprints/cells/impact.md b/doc/architecture/blueprints/cells/impact.md new file mode 100644 index 00000000000..878af4d1a5e --- /dev/null +++ b/doc/architecture/blueprints/cells/impact.md @@ -0,0 +1,58 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells: Cross-section impact' +--- + +# Cells: Cross-section impact + +Cells is a fundamental architecture change that impacts other sections and stages. This section summarizes and links to other groups that may be impacted and highlights potential conflicts that need to be resolved. The Tenant Scale group is not responsible for achieving the goals of other groups but we want to ensure that dependencies are resolved. + +## Summary + +Based on discussions with other groups the net impact of introducing Cells and a new entity called organizations is mostly neutral. It may slow down development in some areas. We did not discover major blockers for other teams. + +1. We need to resolve naming conflicts (proposal is TBD) +1. Cells requires introducing Organizations. Organizations are a new entity **above** top-level groups. Because this is a new entity, it may impact the ability to consolidate settings for Group::Organization and influence their decision on [how to approach introducing a an organization](https://gitlab.com/gitlab-org/gitlab/-/issues/376285#approach-2-organization-is-built-on-top-of-top-level-groups) +1. Organizations may make it slightly easier for Fulfillment to realize their billing plans. + +## Impact on Group::Organization + +We synced with the Organization PM and Designer ([recording](https://youtu.be/b5Opn9cFWFk)) and discussed the similarities and differences between the Cells and Organization proposal ([presentation](https://docs.google.com/presentation/d/1FsUi22Up15b_tu6p2m-yLML3hCZ3rgrZrmzJAxUsNmU/edit?usp=sharing)). + +### Goals of Group::Organization + +As defined in the [organization documentation](../../../user/organization/index.md): + +1. Create an entity to manage everything you do as a GitLab administrator, including: + 1. Defining and applying settings to all of your groups, subgroups, and projects. + 1. Aggregating data from all your groups, subgroups, and projects. +1. Reach feature parity between SaaS and self-managed installations, with all Admin Area settings moving to groups (?). Hardware controls remain on the instance level. + +The [organization roadmap outlines](https://gitlab.com/gitlab-org/gitlab/-/issues/368237#high-level-goals) the current goals in detail. + +### Potential conflicts with Cells + +- Organization defines a new entity as the primary organizational object for groups and projects. +- We will only introduce one entity +- Group::Organization highlighted the need to further validate the key assumption that users only care about what happens within their organization. + +## Impact on Fulfillment + +We synced with Fulfillment ([recording](https://youtu.be/FkQF3uF7vTY)) to discuss how Cells would impact them. Fulfillment is supportive of an entity above top-level groups. Their perspective is outline in [!5639](https://gitlab.com/gitlab-org/customers-gitlab-com/-/merge_requests/5639/diffs). + +### Goals of Fulfillment + +- Fulfillment has a longstanding plan to move billing from the top-level group to a level above. This would mean that a license applies for an organization and all its top-level groups. +- Fulfillment uses Zuora for billing and would like to have a 1-to-1 relationship between an organization and their Zuora entity called BillingAccount. They want to move away from tying a license to a single user. +- If a customer needs multiple organizations, the corresponding BillingAccounts can be rolled up into a consolidated billing account (similar to [AWS consolidated billing](https://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/consolidated-billing.html)) +- Ideally, a self-managed instance has a single Organization by default, which should be enough for most customers. +- Fulfillment prefers only one additional entity. + +A rough representation of this is: + + + +### Potential conflicts with Cells + +- There are no known conflicts between Fulfillment's plans and Cells diff --git a/doc/architecture/blueprints/cells/index.md b/doc/architecture/blueprints/cells/index.md new file mode 100644 index 00000000000..9938875adb6 --- /dev/null +++ b/doc/architecture/blueprints/cells/index.md @@ -0,0 +1,360 @@ +--- +status: accepted +creation-date: "2022-09-07" +authors: [ "@ayufan", "@fzimmer", "@DylanGriffith" ] +coach: "@ayufan" +approvers: [ "@fzimmer" ] +owning-stage: "~devops::enablement" +participating-stages: [] +--- + +<!-- vale gitlab.FutureTense = NO --> + +# Cells + +This document is a work-in-progress and represents a very early state of the Cells design. Significant aspects are not documented, though we expect to add them in the future. + +Cells is a new architecture for our Software as a Service platform. This architecture is horizontally-scalable, resilient, and provides a more consistent user experience. It may also provide additional features in the future, such as data residency control (regions) and federated features. + +For more information about Cells, see also: + +- [Glossary](glossary.md) +- [Goals](goals.md) +- [Cross-section impact](impact.md) + +## Work streams + +We can't ship the entire Cells architecture in one go - it is too large. +Instead, we are defining key work streams required by the project. + +Not all objectives need to be fulfilled to reach production readiness. +It is expected that some objectives will not be completed for General Availability (GA), +but will be enough to run Cells in production. + +### 1. Data access layer + +Before Cells can be run in production we need to prepare the codebase to accept the Cells architecture. +This preparation involves: + +- Allowing data sharing between Cells. +- Updating the tooling for discovering cross-Cell data traversal. +- Defining code practices for cross-Cell data traversal. +- Analyzing the data model to define the data affinity. + +Under this objective the following steps are expected: + +1. **Allow to share cluster-wide data with database-level data access layer.** + + Cells can connect to a database containing shared data. For example: + application settings, users, or routing information. + +1. **Evaluate the efficiency of database-level access vs. API-oriented access layer.** + + Reconsider the consequences of database-level data access for data migration, resiliency of updates and of interconnected systems when we share only a subset of data. + +1. **Cluster-unique identifiers** + + Every object has a unique identifier that can be used to access data across the cluster. The IDs for allocated projects, issues and any other objects are cluster-unique. + +1. **Cluster-wide deletions** + + If entities deleted in Cell 2 are cross-referenced, they are properly deleted or nullified across clusters. We will likely re-use existing [loose foreign keys](../../../development/database/loose_foreign_keys.md) to extend it with cross-Cells data removal. + +1. **Data access layer** + + Ensure that a stable data-access (versioned) layer that allows to share cluster-wide data is implemented. + +1. **Database migration** + + Ensure that migrations can be run independently between Cells, and we safely handle migrations of shared data in a way that does not impact other Cells. + +### 2. Essential workflows + +To make Cells viable we require to define and support +essential workflows before we can consider the Cells +to be of Beta quality. Essential workflows are meant +to cover the majority of application functionality +that makes the product mostly useable, but with some caveats. + +The current approach is to define workflows from top to bottom. +The order defines the presumed priority of the items. +This list is not exhaustive as we would be expecting +other teams to help and fix their workflows after +the initial phase, in which we fix the fundamental ones. + +To consider a project ready for the Beta phase, it is expected +that all features defined below are supported by Cells. +In the cases listed below, the workflows define a set of tables +to be properly attributed to the feature. In some cases, +a table with an ambiguous usage has to be broken down. +For example: `uploads` are used to store user avatars, +as well as uploaded attachments for comments. It would be expected +that `uploads` is split into `uploads` (describing group/project-level attachments) +and `global_uploads` (describing, for example, user avatars). + +Except for initial 2-3 quarters this work is highly parallel. +It would be expected that **group::tenant scale** would help other +teams to fix their feature set to work with Cells. The first 2-3 quarters +would be required to define a general split of data and build required tooling. + +1. **Instance-wide settings are shared across cluster.** + + The Admin Area section for most part is shared across a cluster. + +1. **User accounts are shared across cluster.** + + The purpose is to make `users` cluster-wide. + +1. **User can create group.** + + The purpose is to perform a targeted decomposition of `users` and `namespaces`, because the `namespaces` will be stored locally in the Cell. + +1. **User can create project.** + + The purpose is to perform a targeted decomposition of `users` and `projects`, because the `projects` will be stored locally in the Cell. + +1. **User can change profile avatar that is shared in cluster.** + + The purpose is to fix global uploads that are shared in cluster. + +1. **User can push to Git repository.** + + The purpose is to ensure that essential joins from the projects table are properly attributed to be + Cell-local, and as a result the essential Git workflow is supported. + +1. **User can run CI pipeline.** + + The purpose is that `ci_pipelines` (like `ci_stages`, `ci_builds`, `ci_job_artifacts`) and adjacent tables are properly attributed to be Cell-local. + +1. **User can create issue, merge request, and merge it after it is green.** + + The purpose is to ensure that `issues` and `merge requests` are properly attributed to be `Cell-local`. + +1. **User can manage group and project members.** + + The `members` table is properly attributed to be either `Cell-local` or `cluster-wide`. + +1. **User can manage instance-wide runners.** + + The purpose is to scope all CI Runners to be Cell-local. Instance-wide runners in fact become Cell-local runners. The expectation is to provide a user interface view and manage all runners per Cell, instead of per cluster. + +1. **User is part of organization and can only see information from the organization.** + + The purpose is to have many organizations per Cell, but never have a single organization spanning across many Cells. This is required to ensure that information shown within an organization is isolated, and does not require fetching information from other Cells. + +### 3. Additional workflows + +Some of these additional workflows might need to be supported, depending on the group decision. +This list is not exhaustive of work needed to be done. + +1. **User can use all group-level features.** +1. **User can use all project-level features.** +1. **User can share groups with other groups in an organization.** +1. **User can create system webhook.** +1. **User can upload and manage packages.** +1. **User can manage security detection features.** +1. **User can manage Kubernetes integration.** +1. TBD + +### 4. Routing layer + +The routing layer is meant to offer a consistent user experience where all Cells are presented +under a single domain (for example, `gitlab.com`), instead of +having to navigate to separate domains. + +The user will able to use `https://gitlab.com` to access Cell-enabled GitLab. Depending +on the URL access, it will be transparently proxied to the correct Cell that can serve this particular +information. For example: + +- All requests going to `https://gitlab.com/users/sign_in` are randomly distributed to all Cells. +- All requests going to `https://gitlab.com/gitlab-org/gitlab/-/tree/master` are always directed to Cell 5, for example. +- All requests going to `https://gitlab.com/my-username/my-project` are always directed to Cell 1. + +1. **Technology.** + + We decide what technology the routing service is written in. + The choice is dependent on the best performing language, and the expected way + and place of deployment of the routing layer. If it is required to make + the service multi-cloud it might be required to deploy it to the CDN provider. + Then the service needs to be written using a technology compatible with the CDN provider. + +1. **Cell discovery.** + + The routing service needs to be able to discover and monitor the health of all Cells. + +1. **Router endpoints classification.** + + The stateless routing service will fetch and cache information about endpoints + from one of the Cells. We need to implement a protocol that will allow us to + accurately describe the incoming request (its fingerprint), so it can be classified + by one of the Cells, and the results of that can be cached. We also need to implement + a mechanism for negative cache and cache eviction. + +1. **GraphQL and other ambigious endpoints.** + + Most endpoints have a unique sharding key: the organization, which directly + or indirectly (via a group or project) can be used to classify endpoints. + Some endpoints are ambiguous in their usage (they don't encode the sharding key), + or the sharding key is stored deep in the payload. In these cases, we need to decide how to handle endpoints like `/api/graphql`. + +### 5. Cell deployment + +We will run many Cells. To manage them easier, we need to have consistent +deployment procedures for Cells, including a way to deploy, manage, migrate, +and monitor. + +We are very likely to use tooling made for [GitLab Dedicated](https://about.gitlab.com/dedicated/) +with its control planes. + +1. **Extend GitLab Dedicated to support GCP.** +1. TBD + +### 6. Migration + +When we reach production and are able to store new organizations on new Cells, we need +to be able to divide big Cells into many smaller ones. + +1. **Use GitLab Geo to clone Cells.** + + The purpose is to use GitLab Geo to clone Cells. + +1. **Split Cells by cloning them.** + + Once Cell is cloned we change routing information for organizations. + Organization will encode `cell_id`. When we update `cell_id` it will automatically + make the given Cell to be authoritative to handle the traffic for the given organization. + +1. **Delete redundant data from previous Cells.** + + Since the organization is now stored on many Cells, once we change `cell_id` + we will have to remove data from all other Cells based on `organization_id`. + +## Availability of the feature + +We are following the [Support for Experiment, Beta, and Generally Available features](../../../policy/alpha-beta-support.md). + +### 1. Experiment + +Expectations: + +- We can deploy a Cell on staging or another testing environment by using a separate domain (ex. `cell2.staging.gitlab.com`) + using [Cell deployment](#5-cell-deployment) tooling. +- User can create organization, group and project, and run some of the [essential workflows](#2-essential-workflows). +- It is not expected to be able to run a router to serve all requests under a single domain. +- We expect data-loss of data stored on additional Cells. +- We expect to tear down and create many new Cells to validate tooling. + +### 2. Beta + +Expectations: + +- We can run many Cells under a single domain (ex. `staging.gitlab.com`). +- All features defined in [essential workflows](#2-essential-workflows) are supported. +- Not all aspects of [Routing layer](#4-routing-layer) are finalized. +- We expect additional Cells to be stable with minimal data loss. + +### 3. GA + +Expectations: + +- We can run many Cells under a single domain (for example, `staging.gitlab.com`). +- All features defined in [essential workflows](#2-essential-workflows) are supported. +- All features of [routing layer](#4-routing-layer) are supported. +- Most of [additional workflows](#3-additional-workflows) are supported. +- We don't expect to support any of [migration](#6-migration) aspects. + +### 4. Post GA + +Expectations: + +- We support all [additional workflows](#3-additional-workflows). +- We can [migrate](#6-migration) existing organizations onto new Cells. + +## Iteration plan + +The delivered iterations will focus on solving particular steps of a given +key work stream. + +It is expected that initial iterations will rather +be slow, because they require substantially more +changes to prepare the codebase for data split. + +One iteration describes one quarter's worth of work. + +1. Iteration 1 - FY24Q1 + + - Data access layer: Initial Admin Area settings are shared across cluster. + - Essential workflows: Allow to share cluster-wide data with database-level data access layer + +1. Iteration 2 - FY24Q2 + + - Essential workflows: User accounts are shared across cluster. + - Essential workflows: User can create group. + +1. Iteration 3 - FY24Q3 + + - Essential workflows: User can create project. + - Essential workflows: User can push to Git repository. + - Cell deployment: Extend GitLab Dedicated to support GCP + - Routing: Technology. + +1. Iteration 4 - FY24Q4 + + - Essential workflows: User can run CI pipeline. + - Essential workflows: User can create issue, merge request, and merge it after it is green. + - Data access layer: Evaluate the efficiency of database-level access vs. API-oriented access layer + - Data access layer: Cluster-unique identifiers. + - Routing: Cell discovery. + - Routing: Router endpoints classification. + +1. Iteration 5 - FY25Q1 + + - TBD + +## Technical Proposals + +The Cells architecture do have long lasting implications to data processing, location, scalability and the GitLab architecture. +This section links all different technical proposals that are being evaluated. + +- [Stateless Router That Uses a Cache to Pick Cell and Is Redirected When Wrong Cell Is Reached](proposal-stateless-router-with-buffering-requests.md) + +- [Stateless Router That Uses a Cache to Pick Cell and pre-flight `/api/v4/cells/learn`](proposal-stateless-router-with-routes-learning.md) + +## Impacted features + +The Cells architecture will impact many features requiring some of them to be rewritten, or changed significantly. +This is the list of known affected features with the proposed solutions. + +- [Cells: Git Access](cells-feature-git-access.md) +- [Cells: Data Migration](cells-feature-data-migration.md) +- [Cells: Database Sequences](cells-feature-database-sequences.md) +- [Cells: GraphQL](cells-feature-graphql.md) +- [Cells: Organizations](cells-feature-organizations.md) +- [Cells: Router Endpoints Classification](cells-feature-router-endpoints-classification.md) +- [Cells: Schema changes (Postgres and Elasticsearch migrations)](cells-feature-schema-changes.md) +- [Cells: Backups](cells-feature-backups.md) +- [Cells: Global Search](cells-feature-global-search.md) +- [Cells: CI Runners](cells-feature-ci-runners.md) +- [Cells: Admin Area](cells-feature-admin-area.md) +- [Cells: Secrets](cells-feature-secrets.md) +- [Cells: Container Registry](cells-feature-container-registry.md) +- [Cells: Contributions: Forks](cells-feature-contributions-forks.md) +- [Cells: Personal Namespaces](cells-feature-personal-namespaces.md) +- [Cells: Dashboard: Projects, Todos, Issues, Merge Requests, Activity, ...](cells-feature-dashboard.md) +- [Cells: Snippets](cells-feature-snippets.md) +- [Cells: Uploads](cells-feature-uploads.md) +- [Cells: GitLab Pages](cells-feature-gitlab-pages.md) +- [Cells: Agent for Kubernetes](cells-feature-agent-for-kubernetes.md) + +## Decision log + +- 2022-03-15: Google Cloud as the cloud service. For details, see [issue 396641](https://gitlab.com/gitlab-org/gitlab/-/issues/396641#note_1314932272). + +## Links + +- [Internal Pods presentation](https://docs.google.com/presentation/d/1x1uIiN8FR9fhL7pzFh9juHOVcSxEY7d2_q4uiKKGD44/edit#slide=id.ge7acbdc97a_0_155) +- [Internal link to all diagrams](https://drive.google.com/file/d/13NHzbTrmhUM-z_Bf0RjatUEGw5jWHSLt/view?usp=sharing) +- [Cells Epic](https://gitlab.com/groups/gitlab-org/-/epics/7582) +- [Database Group investigation](https://about.gitlab.com/handbook/engineering/development/enablement/data_stores/database/doc/root-namespace-sharding.html) +- [Shopify Pods architecture](https://shopify.engineering/a-pods-architecture-to-allow-shopify-to-scale) +- [Opstrace architecture](https://gitlab.com/gitlab-org/opstrace/opstrace/-/blob/main/docs/architecture/overview.md) diff --git a/doc/architecture/blueprints/cells/proposal-stateless-router-with-buffering-requests.md b/doc/architecture/blueprints/cells/proposal-stateless-router-with-buffering-requests.md new file mode 100644 index 00000000000..f352fea84b1 --- /dev/null +++ b/doc/architecture/blueprints/cells/proposal-stateless-router-with-buffering-requests.md @@ -0,0 +1,649 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells Stateless Router Proposal' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Pods design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Pods, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Proposal: Stateless Router + +We will decompose `gitlab_users`, `gitlab_routes` and `gitlab_admin` related +tables so that they can be shared between all cells and allow any cell to +authenticate a user and route requests to the correct cell. Cells may receive +requests for the resources they don't own, but they know how to redirect back +to the correct cell. + +The router is stateless and does not read from the `routes` database which +means that all interactions with the database still happen from the Rails +monolith. This architecture also supports regions by allowing for low traffic +databases to be replicated across regions. + +Users are not directly exposed to the concept of Cells but instead they see +different data dependent on their chosen "organization". +[Organizations](glossary.md#organizations) will be a new model introduced to enforce isolation in the +application and allow us to decide which request route to which cell, since an +organization can only be on a single cell. + +## Differences + +The main difference between this proposal and the one [with learning routes](proposal-stateless-router-with-routes-learning.md) +is that this proposal always sends requests to any of the Cells. If the requests cannot be processed, +the requests will be bounced back with relevant headers. This requires that request to be buffered. +It allows that request decoding can be either via URI or Body of request by Rails. +This means that each request might be sent more than once and be processed more than once as result. + +The [with learning routes proposal](proposal-stateless-router-with-routes-learning.md) requires that +routable information is always encoded in URI, and the router sends a pre-flight request. + +## Summary in diagrams + +This shows how a user request routes via DNS to the nearest router and the router chooses a cell to send the request to. + +```mermaid +graph TD; + user((User)); + dns[DNS]; + router_us(Router); + router_eu(Router); + cell_us0{Cell US0}; + cell_us1{Cell US1}; + cell_eu0{Cell EU0}; + cell_eu1{Cell EU1}; + user-->dns; + dns-->router_us; + dns-->router_eu; + subgraph Europe + router_eu-->cell_eu0; + router_eu-->cell_eu1; + end + subgraph United States + router_us-->cell_us0; + router_us-->cell_us1; + end +``` + +<details><summary>More detail</summary> + +This shows that the router can actually send requests to any cell. The user will +get the closest router to them geographically. + +```mermaid +graph TD; + user((User)); + dns[DNS]; + router_us(Router); + router_eu(Router); + cell_us0{Cell US0}; + cell_us1{Cell US1}; + cell_eu0{Cell EU0}; + cell_eu1{Cell EU1}; + user-->dns; + dns-->router_us; + dns-->router_eu; + subgraph Europe + router_eu-->cell_eu0; + router_eu-->cell_eu1; + end + subgraph United States + router_us-->cell_us0; + router_us-->cell_us1; + end + router_eu-.->cell_us0; + router_eu-.->cell_us1; + router_us-.->cell_eu0; + router_us-.->cell_eu1; +``` + +</details> + +<details><summary>Even more detail</summary> + +This shows the databases. `gitlab_users` and `gitlab_routes` exist only in the +US region but are replicated to other regions. Replication does not have an +arrow because it's too hard to read the diagram. + +```mermaid +graph TD; + user((User)); + dns[DNS]; + router_us(Router); + router_eu(Router); + cell_us0{Cell US0}; + cell_us1{Cell US1}; + cell_eu0{Cell EU0}; + cell_eu1{Cell EU1}; + db_gitlab_users[(gitlab_users Primary)]; + db_gitlab_routes[(gitlab_routes Primary)]; + db_gitlab_users_replica[(gitlab_users Replica)]; + db_gitlab_routes_replica[(gitlab_routes Replica)]; + db_cell_us0[(gitlab_main/gitlab_ci Cell US0)]; + db_cell_us1[(gitlab_main/gitlab_ci Cell US1)]; + db_cell_eu0[(gitlab_main/gitlab_ci Cell EU0)]; + db_cell_eu1[(gitlab_main/gitlab_ci Cell EU1)]; + user-->dns; + dns-->router_us; + dns-->router_eu; + subgraph Europe + router_eu-->cell_eu0; + router_eu-->cell_eu1; + cell_eu0-->db_cell_eu0; + cell_eu0-->db_gitlab_users_replica; + cell_eu0-->db_gitlab_routes_replica; + cell_eu1-->db_gitlab_users_replica; + cell_eu1-->db_gitlab_routes_replica; + cell_eu1-->db_cell_eu1; + end + subgraph United States + router_us-->cell_us0; + router_us-->cell_us1; + cell_us0-->db_cell_us0; + cell_us0-->db_gitlab_users; + cell_us0-->db_gitlab_routes; + cell_us1-->db_gitlab_users; + cell_us1-->db_gitlab_routes; + cell_us1-->db_cell_us1; + end + router_eu-.->cell_us0; + router_eu-.->cell_us1; + router_us-.->cell_eu0; + router_us-.->cell_eu1; +``` + +</details> + +## Summary of changes + +1. Tables related to User data (including profile settings, authentication credentials, personal access tokens) are decomposed into a `gitlab_users` schema +1. The `routes` table is decomposed into `gitlab_routes` schema +1. The `application_settings` (and probably a few other instance level tables) are decomposed into `gitlab_admin` schema +1. A new column `routes.cell_id` is added to `routes` table +1. A new Router service exists to choose which cell to route a request to. +1. A new concept will be introduced in GitLab called an organization and a user can select a "default organization" and this will be a user level setting. The default organization is used to redirect users away from ambiguous routes like `/dashboard` to organization scoped routes like `/organizations/my-organization/-/dashboard`. Legacy users will have a special default organization that allows them to keep using global resources on `Cell US0`. All existing namespaces will initially move to this public organization. +1. If a cell receives a request for a `routes.cell_id` that it does not own it returns a `302` with `X-Gitlab-Cell-Redirect` header so that the router can send the request to the correct cell. The correct cell can also set a header `X-Gitlab-Cell-Cache` which contains information about how this request should be cached to remember the cell. For example if the request was `/gitlab-org/gitlab` then the header would encode `/gitlab-org/* => Cell US0` (for example, any requests starting with `/gitlab-org/` can always be routed to `Cell US0` +1. When the cell does not know (from the cache) which cell to send a request to it just picks a random cell within it's region +1. Writes to `gitlab_users` and `gitlab_routes` are sent to a primary PostgreSQL server in our `US` region but reads can come from replicas in the same region. This will add latency for these writes but we expect they are infrequent relative to the rest of GitLab. + +## Detailed explanation of default organization in the first iteration + +All users will get a new column `users.default_organization` which they can +control in user settings. We will introduce a concept of the +`GitLab.com Public` organization. This will be set as the default organization for all existing +users. This organization will allow the user to see data from all namespaces in +`Cell US0` (for example, our original GitLab.com instance). This behavior can be invisible to +existing users such that they don't even get told when they are viewing a +global page like `/dashboard` that it's even scoped to an organization. + +Any new users with a default organization other than `GitLab.com Public` will have +a distinct user experience and will be fully aware that every page they load is +only ever scoped to a single organization. These users can never +load any global pages like `/dashboard` and will end up being redirected to +`/organizations/<DEFAULT_ORGANIZATION>/-/dashboard`. This may also be the case +for legacy APIs and such users may only ever be able to use APIs scoped to a +organization. + +## Detailed explanation of Admin Area settings + +We believe that maintaining and synchronizing Admin Area settings will be +frustrating and painful so to avoid this we will decompose and share all Admin Area +settings in the `gitlab_admin` schema. This should be safe (similar to other +shared schemas) because these receive very little write traffic. + +In cases where different cells need different settings (for example, the +Elasticsearch URL), we will either decide to use a templated +format in the relevant `application_settings` row which allows it to be dynamic +per cell. Alternatively if that proves difficult we'll introduce a new table +called `per_cell_application_settings` and this will have 1 row per cell to allow +setting different settings per cell. It will still be part of the `gitlab_admin` +schema and shared which will allow us to centrally manage it and simplify +keeping settings in sync for all cells. + +## Pros + +1. Router is stateless and can live in many regions. We use Anycast DNS to resolve to nearest region for the user. +1. Cells can receive requests for namespaces in the wrong cell and the user + still gets the right response as well as caching at the router that + ensures the next request is sent to the correct cell so the next request + will go to the correct cell +1. The majority of the code still lives in `gitlab` rails codebase. The Router doesn't actually need to understand how GitLab URLs are composed. +1. Since the responsibility to read and write `gitlab_users`, + `gitlab_routes` and `gitlab_admin` still lives in Rails it means minimal + changes will be needed to the Rails application compared to extracting + services that need to isolate the domain models and build new interfaces. +1. Compared to a separate routing service this allows the Rails application + to encode more complex rules around how to map URLs to the correct cell + and may work for some existing API endpoints. +1. All the new infrastructure (just a router) is optional and a single-cell + self-managed installation does not even need to run the Router and there are + no other new services. + +## Cons + +1. `gitlab_users`, `gitlab_routes` and `gitlab_admin` databases may need to be + replicated across regions and writes need to go across regions. We need to + do an analysis on write TPS for the relevant tables to determine if this is + feasible. +1. Sharing access to the database from many different Cells means that they are + all coupled at the Postgres schema level and this means changes to the + database schema need to be done carefully in sync with the deployment of all + Cells. This limits us to ensure that Cells are kept in closely similar + versions compared to an architecture with shared services that have an API + we control. +1. Although most data is stored in the right region there can be requests + proxied from another region which may be an issue for certain types + of compliance. +1. Data in `gitlab_users` and `gitlab_routes` databases must be replicated in + all regions which may be an issue for certain types of compliance. +1. The router cache may need to be very large if we get a wide variety of URLs + (for example, long tail). In such a case we may need to implement a 2nd level of + caching in user cookies so their frequently accessed pages always go to the + right cell the first time. +1. Having shared database access for `gitlab_users` and `gitlab_routes` + from multiple cells is an unusual architecture decision compared to + extracting services that are called from multiple cells. +1. It is very likely we won't be able to find cacheable elements of a + GraphQL URL and often existing GraphQL endpoints are heavily dependent on + ids that won't be in the `routes` table so cells won't necessarily know + what cell has the data. As such we'll probably have to update our GraphQL + calls to include an organization context in the path like + `/api/organizations/<organization>/graphql`. +1. This architecture implies that implemented endpoints can only access data + that are readily accessible on a given Cell, but are unlikely + to aggregate information from many Cells. +1. All unknown routes are sent to the latest deployment which we assume to be `Cell US0`. + This is required as newly added endpoints will be only decodable by latest cell. + This Cell could later redirect to correct one that can serve the given request. + Since request processing might be heavy some Cells might receive significant amount + of traffic due to that. + +## Example database configuration + +Handling shared `gitlab_users`, `gitlab_routes` and `gitlab_admin` databases, while having dedicated `gitlab_main` and `gitlab_ci` databases should already be handled by the way we use `config/database.yml`. We should also, already be able to handle the dedicated EU replicas while having a single US primary for `gitlab_users` and `gitlab_routes`. Below is a snippet of part of the database configuration for the Cell architecture described above. + +<details><summary>Cell US0</summary> + +```yaml +# config/database.yml +production: + main: + host: postgres-main.cell-us0.primary.consul + load_balancing: + discovery: postgres-main.cell-us0.replicas.consul + ci: + host: postgres-ci.cell-us0.primary.consul + load_balancing: + discovery: postgres-ci.cell-us0.replicas.consul + users: + host: postgres-users-primary.consul + load_balancing: + discovery: postgres-users-replicas.us.consul + routes: + host: postgres-routes-primary.consul + load_balancing: + discovery: postgres-routes-replicas.us.consul + admin: + host: postgres-admin-primary.consul + load_balancing: + discovery: postgres-admin-replicas.us.consul +``` + +</details> + +<details><summary>Cell EU0</summary> + +```yaml +# config/database.yml +production: + main: + host: postgres-main.cell-eu0.primary.consul + load_balancing: + discovery: postgres-main.cell-eu0.replicas.consul + ci: + host: postgres-ci.cell-eu0.primary.consul + load_balancing: + discovery: postgres-ci.cell-eu0.replicas.consul + users: + host: postgres-users-primary.consul + load_balancing: + discovery: postgres-users-replicas.eu.consul + routes: + host: postgres-routes-primary.consul + load_balancing: + discovery: postgres-routes-replicas.eu.consul + admin: + host: postgres-admin-primary.consul + load_balancing: + discovery: postgres-admin-replicas.eu.consul +``` + +</details> + +## Request flows + +1. `gitlab-org` is a top level namespace and lives in `Cell US0` in the `GitLab.com Public` organization +1. `my-company` is a top level namespace and lives in `Cell EU0` in the `my-organization` organization + +### Experience for paying user that is part of `my-organization` + +Such a user will have a default organization set to `/my-organization` and will be +unable to load any global routes outside of this organization. They may load other +projects/namespaces but their MR/Todo/Issue counts at the top of the page will +not be correctly populated in the first iteration. The user will be aware of +this limitation. + +#### Navigates to `/my-company/my-project` while logged in + +1. User is in Europe so DNS resolves to the router in Europe +1. They request `/my-company/my-project` without the router cache, so the router chooses randomly `Cell EU1` +1. `Cell EU1` does not have `/my-company`, but it knows that it lives in `Cell EU0` so it redirects the router to `Cell EU0` +1. `Cell EU0` returns the correct response as well as setting the cache headers for the router `/my-company/* => Cell EU0` +1. The router now caches and remembers any request paths matching `/my-company/*` should go to `Cell EU0` + +```mermaid +sequenceDiagram + participant user as User + participant router_eu as Router EU + participant cell_eu0 as Cell EU0 + participant cell_eu1 as Cell EU1 + user->>router_eu: GET /my-company/my-project + router_eu->>cell_eu1: GET /my-company/my-project + cell_eu1->>router_eu: 302 /my-company/my-project X-Gitlab-Cell-Redirect={cell:Cell EU0} + router_eu->>cell_eu0: GET /my-company/my-project + cell_eu0->>user: <h1>My Project... X-Gitlab-Cell-Cache={path_prefix:/my-company/} +``` + +#### Navigates to `/my-company/my-project` while not logged in + +1. User is in Europe so DNS resolves to the router in Europe +1. The router does not have `/my-company/*` cached yet so it chooses randomly `Cell EU1` +1. `Cell EU1` redirects them through a login flow +1. Still they request `/my-company/my-project` without the router cache, so the router chooses a random cell `Cell EU1` +1. `Cell EU1` does not have `/my-company`, but it knows that it lives in `Cell EU0` so it redirects the router to `Cell EU0` +1. `Cell EU0` returns the correct response as well as setting the cache headers for the router `/my-company/* => Cell EU0` +1. The router now caches and remembers any request paths matching `/my-company/*` should go to `Cell EU0` + +```mermaid +sequenceDiagram + participant user as User + participant router_eu as Router EU + participant cell_eu0 as Cell EU0 + participant cell_eu1 as Cell EU1 + user->>router_eu: GET /my-company/my-project + router_eu->>cell_eu1: GET /my-company/my-project + cell_eu1->>user: 302 /users/sign_in?redirect=/my-company/my-project + user->>router_eu: GET /users/sign_in?redirect=/my-company/my-project + router_eu->>cell_eu1: GET /users/sign_in?redirect=/my-company/my-project + cell_eu1->>user: <h1>Sign in... + user->>router_eu: POST /users/sign_in?redirect=/my-company/my-project + router_eu->>cell_eu1: POST /users/sign_in?redirect=/my-company/my-project + cell_eu1->>user: 302 /my-company/my-project + user->>router_eu: GET /my-company/my-project + router_eu->>cell_eu1: GET /my-company/my-project + cell_eu1->>router_eu: 302 /my-company/my-project X-Gitlab-Cell-Redirect={cell:Cell EU0} + router_eu->>cell_eu0: GET /my-company/my-project + cell_eu0->>user: <h1>My Project... X-Gitlab-Cell-Cache={path_prefix:/my-company/} +``` + +#### Navigates to `/my-company/my-other-project` after last step + +1. User is in Europe so DNS resolves to the router in Europe +1. The router cache now has `/my-company/* => Cell EU0`, so the router chooses `Cell EU0` +1. `Cell EU0` returns the correct response as well as the cache header again + +```mermaid +sequenceDiagram + participant user as User + participant router_eu as Router EU + participant cell_eu0 as Cell EU0 + participant cell_eu1 as Cell EU1 + user->>router_eu: GET /my-company/my-project + router_eu->>cell_eu0: GET /my-company/my-project + cell_eu0->>user: <h1>My Project... X-Gitlab-Cell-Cache={path_prefix:/my-company/} +``` + +#### Navigates to `/gitlab-org/gitlab` after last step + +1. User is in Europe so DNS resolves to the router in Europe +1. The router has no cached value for this URL so randomly chooses `Cell EU0` +1. `Cell EU0` redirects the router to `Cell US0` +1. `Cell US0` returns the correct response as well as the cache header again + +```mermaid +sequenceDiagram + participant user as User + participant router_eu as Router EU + participant cell_eu0 as Cell EU0 + participant cell_us0 as Cell US0 + user->>router_eu: GET /gitlab-org/gitlab + router_eu->>cell_eu0: GET /gitlab-org/gitlab + cell_eu0->>router_eu: 302 /gitlab-org/gitlab X-Gitlab-Cell-Redirect={cell:Cell US0} + router_eu->>cell_us0: GET /gitlab-org/gitlab + cell_us0->>user: <h1>GitLab.org... X-Gitlab-Cell-Cache={path_prefix:/gitlab-org/} +``` + +In this case the user is not on their "default organization" so their TODO +counter will not include their normal todos. We may choose to highlight this in +the UI somewhere. A future iteration may be able to fetch that for them from +their default organization. + +#### Navigates to `/` + +1. User is in Europe so DNS resolves to the router in Europe +1. Router does not have a cache for `/` route (specifically rails never tells it to cache this route) +1. The Router choose `Cell EU0` randomly +1. The Rails application knows the users default organization is `/my-organization`, so + it redirects the user to `/organizations/my-organization/-/dashboard` +1. The Router has a cached value for `/organizations/my-organization/*` so it then sends the + request to `POD EU0` +1. `Cell EU0` serves up a new page `/organizations/my-organization/-/dashboard` which is the same + dashboard view we have today but scoped to an organization clearly in the UI +1. The user is (optionally) presented with a message saying that data on this page is only + from their default organization and that they can change their default + organization if it's not right. + +```mermaid +sequenceDiagram + participant user as User + participant router_eu as Router EU + participant cell_eu0 as Cell EU0 + user->>router_eu: GET / + router_eu->>cell_eu0: GET / + cell_eu0->>user: 302 /organizations/my-organization/-/dashboard + user->>router: GET /organizations/my-organization/-/dashboard + router->>cell_eu0: GET /organizations/my-organization/-/dashboard + cell_eu0->>user: <h1>My Company Dashboard... X-Gitlab-Cell-Cache={path_prefix:/organizations/my-organization/} +``` + +#### Navigates to `/dashboard` + +As above, they will end up on `/organizations/my-organization/-/dashboard` as +the rails application will already redirect `/` to the dashboard page. + +### Navigates to `/not-my-company/not-my-project` while logged in (but they don't have access since this project/group is private) + +1. User is in Europe so DNS resolves to the router in Europe +1. The router knows that `/not-my-company` lives in `Cell US1` so sends the request to this +1. The user does not have access so `Cell US1` returns 404 + +```mermaid +sequenceDiagram + participant user as User + participant router_eu as Router EU + participant cell_us1 as Cell US1 + user->>router_eu: GET /not-my-company/not-my-project + router_eu->>cell_us1: GET /not-my-company/not-my-project + cell_us1->>user: 404 +``` + +#### Creates a new top level namespace + +The user will be asked which organization they want the namespace to belong to. +If they select `my-organization` then it will end up on the same cell as all +other namespaces in `my-organization`. If they select nothing we default to +`GitLab.com Public` and it is clear to the user that this is isolated from +their existing organization such that they won't be able to see data from both +on a single page. + +### Experience for GitLab team member that is part of `/gitlab-org` + +Such a user is considered a legacy user and has their default organization set to +`GitLab.com Public`. This is a "meta" organization that does not really exist but +the Rails application knows to interpret this organization to mean that they are +allowed to use legacy global functionality like `/dashboard` to see data across +namespaces located on `Cell US0`. The rails backend also knows that the default cell to render any ambiguous +routes like `/dashboard` is `Cell US0`. Lastly the user will be allowed to +navigate to organizations on another cell like `/my-organization` but when they do the +user will see a message indicating that some data may be missing (for example, the +MRs/Issues/Todos) counts. + +#### Navigates to `/gitlab-org/gitlab` while not logged in + +1. User is in the US so DNS resolves to the US router +1. The router knows that `/gitlab-org` lives in `Cell US0` so sends the request + to this cell +1. `Cell US0` serves up the response + +```mermaid +sequenceDiagram + participant user as User + participant router_us as Router US + participant cell_us0 as Cell US0 + user->>router_us: GET /gitlab-org/gitlab + router_us->>cell_us0: GET /gitlab-org/gitlab + cell_us0->>user: <h1>GitLab.org... X-Gitlab-Cell-Cache={path_prefix:/gitlab-org/} +``` + +#### Navigates to `/` + +1. User is in US so DNS resolves to the router in US +1. Router does not have a cache for `/` route (specifically rails never tells it to cache this route) +1. The Router chooses `Cell US1` randomly +1. The Rails application knows the users default organization is `GitLab.com Public`, so + it redirects the user to `/dashboards` (only legacy users can see + `/dashboard` global view) +1. Router does not have a cache for `/dashboard` route (specifically rails never tells it to cache this route) +1. The Router chooses `Cell US1` randomly +1. The Rails application knows the users default organization is `GitLab.com Public`, so + it allows the user to load `/dashboards` (only legacy users can see + `/dashboard` global view) and redirects to router the legacy cell which is `Cell US0` +1. `Cell US0` serves up the global view dashboard page `/dashboard` which is the same + dashboard view we have today + +```mermaid +sequenceDiagram + participant user as User + participant router_us as Router US + participant cell_us0 as Cell US0 + participant cell_us1 as Cell US1 + user->>router_us: GET / + router_us->>cell_us1: GET / + cell_us1->>user: 302 /dashboard + user->>router_us: GET /dashboard + router_us->>cell_us1: GET /dashboard + cell_us1->>router_us: 302 /dashboard X-Gitlab-Cell-Redirect={cell:Cell US0} + router_us->>cell_us0: GET /dashboard + cell_us0->>user: <h1>Dashboard... +``` + +#### Navigates to `/my-company/my-other-project` while logged in (but they don't have access since this project is private) + +They get a 404. + +### Experience for non-authenticated users + +Flow is similar to authenticated users except global routes like `/dashboard` will +redirect to the login page as there is no default organization to choose from. + +### A new customers signs up + +They will be asked if they are already part of an organization or if they'd +like to create one. If they choose neither they end up no the default +`GitLab.com Public` organization. + +### An organization is moved from 1 cell to another + +TODO + +### GraphQL/API requests which don't include the namespace in the URL + +TODO + +### The autocomplete suggestion functionality in the search bar which remembers recent issues/MRs + +TODO + +### Global search + +TODO + +## Administrator + +### Loads `/admin` page + +1. Router picks a random cell `Cell US0` +1. Cell US0 redirects user to `/admin/cells/cellus0` +1. Cell US0 renders an Admin Area page and also returns a cache header to cache `/admin/cellss/cellus0/* => Cell US0`. The Admin Area page contains a dropdown list showing other cells they could select and it changes the query parameter. + +Admin Area settings in Postgres are all shared across all cells to avoid +divergence but we still make it clear in the URL and UI which cell is serving +the Admin Area page as there is dynamic data being generated from these pages and +the operator may want to view a specific cell. + +## More Technical Problems To Solve + +### Replicating User Sessions Between All Cells + +Today user sessions live in Redis but each cell will have their own Redis instance. We already use a dedicated Redis instance for sessions so we could consider sharing this with all cells like we do with `gitlab_users` PostgreSQL database. But an important consideration will be latency as we would still want to mostly fetch sessions from the same region. + +An alternative might be that user sessions get moved to a JWT payload that encodes all the session data but this has downsides. For example, it is difficult to expire a user session, when their password changes or for other reasons, if the session lives in a JWT controlled by the user. + +### How do we migrate between Cells + +Migrating data between cells will need to factor all data stores: + +1. PostgreSQL +1. Redis Shared State +1. Gitaly +1. Elasticsearch + +### Is it still possible to leak the existence of private groups via a timing attack? + +If you have router in EU, and you know that EU router by default redirects +to EU located Cells, you know their latency (lets assume 10 ms). Now, if your +request is bounced back and redirected to US which has different latency +(lets assume that roundtrip will be around 60 ms) you can deduce that 404 was +returned by US Cell and know that your 404 is in fact 403. + +We may defer this until we actually implement a cell in a different region. Such timing attacks are already theoretically possible with the way we do permission checks today but the timing difference is probably too small to be able to detect. + +One technique to mitigate this risk might be to have the router add a random +delay to any request that returns 404 from a cell. + +## Should runners be shared across all cells? + +We have 2 options and we should decide which is easier: + +1. Decompose runner registration and queuing tables and share them across all + cells. This may have implications for scalability, and we'd need to consider + if this would include group/project runners as this may have scalability + concerns as these are high traffic tables that would need to be shared. +1. Runners are registered per-cell and, we probably have a separate fleet of + runners for every cell or just register the same runners to many cells which + may have implications for queueing + +## How do we guarantee unique ids across all cells for things that cannot conflict? + +This project assumes at least namespaces and projects have unique ids across +all cells as many requests need to be routed based on their ID. Since those +tables are across different databases then guaranteeing a unique ID will +require a new solution. There are likely other tables where unique IDs are +necessary and depending on how we resolve routing for GraphQL and other APIs +and other design goals it may be determined that we want the primary key to be +unique for all tables. diff --git a/doc/architecture/blueprints/cells/proposal-stateless-router-with-routes-learning.md b/doc/architecture/blueprints/cells/proposal-stateless-router-with-routes-learning.md new file mode 100644 index 00000000000..aadc08016e3 --- /dev/null +++ b/doc/architecture/blueprints/cells/proposal-stateless-router-with-routes-learning.md @@ -0,0 +1,673 @@ +--- +stage: enablement +group: Tenant Scale +description: 'Cells Stateless Router Proposal' +--- + +<!-- vale gitlab.FutureTense = NO --> + +This document is a work-in-progress and represents a very early state of the +Cells design. Significant aspects are not documented, though we expect to add +them in the future. This is one possible architecture for Cells, and we intend to +contrast this with alternatives before deciding which approach to implement. +This documentation will be kept even if we decide not to implement this so that +we can document the reasons for not choosing this approach. + +# Proposal: Stateless Router + +We will decompose `gitlab_users`, `gitlab_routes` and `gitlab_admin` related +tables so that they can be shared between all cells and allow any cell to +authenticate a user and route requests to the correct cell. Cells may receive +requests for the resources they don't own, but they know how to redirect back +to the correct cell. + +The router is stateless and does not read from the `routes` database which +means that all interactions with the database still happen from the Rails +monolith. This architecture also supports regions by allowing for low traffic +databases to be replicated across regions. + +Users are not directly exposed to the concept of Cells but instead they see +different data dependent on their chosen "organization". +[Organizations](glossary.md#organizations) will be a new model introduced to enforce isolation in the +application and allow us to decide which request route to which cell, since an +organization can only be on a single cell. + +## Differences + +The main difference between this proposal and one [with buffering requests](proposal-stateless-router-with-buffering-requests.md) +is that this proposal uses a pre-flight API request (`/api/v4/cells/learn`) to redirect the request body to the correct Cell. +This means that each request is sent exactly once to be processed, but the URI is used to decode which Cell it should be directed. + +## Summary in diagrams + +This shows how a user request routes via DNS to the nearest router and the router chooses a cell to send the request to. + +```mermaid +graph TD; + user((User)); + dns[DNS]; + router_us(Router); + router_eu(Router); + cell_us0{Cell US0}; + cell_us1{Cell US1}; + cell_eu0{Cell EU0}; + cell_eu1{Cell EU1}; + user-->dns; + dns-->router_us; + dns-->router_eu; + subgraph Europe + router_eu-->cell_eu0; + router_eu-->cell_eu1; + end + subgraph United States + router_us-->cell_us0; + router_us-->cell_us1; + end +``` + +### More detail + +This shows that the router can actually send requests to any cell. The user will +get the closest router to them geographically. + +```mermaid +graph TD; + user((User)); + dns[DNS]; + router_us(Router); + router_eu(Router); + cell_us0{Cell US0}; + cell_us1{Cell US1}; + cell_eu0{Cell EU0}; + cell_eu1{Cell EU1}; + user-->dns; + dns-->router_us; + dns-->router_eu; + subgraph Europe + router_eu-->cell_eu0; + router_eu-->cell_eu1; + end + subgraph United States + router_us-->cell_us0; + router_us-->cell_us1; + end + router_eu-.->cell_us0; + router_eu-.->cell_us1; + router_us-.->cell_eu0; + router_us-.->cell_eu1; +``` + +### Even more detail + +This shows the databases. `gitlab_users` and `gitlab_routes` exist only in the +US region but are replicated to other regions. Replication does not have an +arrow because it's too hard to read the diagram. + +```mermaid +graph TD; + user((User)); + dns[DNS]; + router_us(Router); + router_eu(Router); + cell_us0{Cell US0}; + cell_us1{Cell US1}; + cell_eu0{Cell EU0}; + cell_eu1{Cell EU1}; + db_gitlab_users[(gitlab_users Primary)]; + db_gitlab_routes[(gitlab_routes Primary)]; + db_gitlab_users_replica[(gitlab_users Replica)]; + db_gitlab_routes_replica[(gitlab_routes Replica)]; + db_cell_us0[(gitlab_main/gitlab_ci Cell US0)]; + db_cell_us1[(gitlab_main/gitlab_ci Cell US1)]; + db_cell_eu0[(gitlab_main/gitlab_ci Cell EU0)]; + db_cell_eu1[(gitlab_main/gitlab_ci Cell EU1)]; + user-->dns; + dns-->router_us; + dns-->router_eu; + subgraph Europe + router_eu-->cell_eu0; + router_eu-->cell_eu1; + cell_eu0-->db_cell_eu0; + cell_eu0-->db_gitlab_users_replica; + cell_eu0-->db_gitlab_routes_replica; + cell_eu1-->db_gitlab_users_replica; + cell_eu1-->db_gitlab_routes_replica; + cell_eu1-->db_cell_eu1; + end + subgraph United States + router_us-->cell_us0; + router_us-->cell_us1; + cell_us0-->db_cell_us0; + cell_us0-->db_gitlab_users; + cell_us0-->db_gitlab_routes; + cell_us1-->db_gitlab_users; + cell_us1-->db_gitlab_routes; + cell_us1-->db_cell_us1; + end + router_eu-.->cell_us0; + router_eu-.->cell_us1; + router_us-.->cell_eu0; + router_us-.->cell_eu1; +``` + +## Summary of changes + +1. Tables related to User data (including profile settings, authentication credentials, personal access tokens) are decomposed into a `gitlab_users` schema +1. The `routes` table is decomposed into `gitlab_routes` schema +1. The `application_settings` (and probably a few other instance level tables) are decomposed into `gitlab_admin` schema +1. A new column `routes.cell_id` is added to `routes` table +1. A new Router service exists to choose which cell to route a request to. +1. If a router receives a new request it will send `/api/v4/cells/learn?method=GET&path_info=/group-org/project` to learn which Cell can process it +1. A new concept will be introduced in GitLab called an organization +1. We require all existing endpoints to be routable by URI, or be fixed to a specific Cell for processing. This requires changing ambiguous endpoints like `/dashboard` to be scoped like `/organizations/my-organization/-/dashboard` +1. Endpoints like `/admin` would be routed always to the specific Cell, like `cell_0` +1. Each Cell can respond to `/api/v4/cells/learn` and classify each endpoint +1. Writes to `gitlab_users` and `gitlab_routes` are sent to a primary PostgreSQL server in our `US` region but reads can come from replicas in the same region. This will add latency for these writes but we expect they are infrequent relative to the rest of GitLab. + +## Pre-flight request learning + +While processing a request the URI will be decoded and a pre-flight request +will be sent for each non-cached endpoint. + +When asking for the endpoint GitLab Rails will return information about +the routable path. GitLab Rails will decode `path_info` and match it to +an existing endpoint and find a routable entity (like project). The router will +treat this as short-lived cache information. + +1. Prefix match: `/api/v4/cells/learn?method=GET&path_info=/gitlab-org/gitlab-test/-/issues` + + ```json + { + "path": "/gitlab-org/gitlab-test", + "cell": "cell_0", + "source": "routable" + } + ``` + +1. Some endpoints might require an exact match: `/api/v4/cells/learn?method=GET&path_info=/-/profile` + + ```json + { + "path": "/-/profile", + "cell": "cell_0", + "source": "fixed", + "exact": true + } + ``` + +## Detailed explanation of default organization in the first iteration + +All users will get a new column `users.default_organization` which they can +control in user settings. We will introduce a concept of the +`GitLab.com Public` organization. This will be set as the default organization for all existing +users. This organization will allow the user to see data from all namespaces in +`Cell US0` (ie. our original GitLab.com instance). This behavior can be invisible to +existing users such that they don't even get told when they are viewing a +global page like `/dashboard` that it's even scoped to an organization. + +Any new users with a default organization other than `GitLab.com Public` will have +a distinct user experience and will be fully aware that every page they load is +only ever scoped to a single organization. These users can never +load any global pages like `/dashboard` and will end up being redirected to +`/organizations/<DEFAULT_ORGANIZATION>/-/dashboard`. This may also be the case +for legacy APIs and such users may only ever be able to use APIs scoped to a +organization. + +## Detailed explanation of Admin Area settings + +We believe that maintaining and synchronizing Admin Area settings will be +frustrating and painful so to avoid this we will decompose and share all Admin Area +settings in the `gitlab_admin` schema. This should be safe (similar to other +shared schemas) because these receive very little write traffic. + +In cases where different cells need different settings (eg. the +Elasticsearch URL), we will either decide to use a templated +format in the relevant `application_settings` row which allows it to be dynamic +per cell. Alternatively if that proves difficult we'll introduce a new table +called `per_cell_application_settings` and this will have 1 row per cell to allow +setting different settings per cell. It will still be part of the `gitlab_admin` +schema and shared which will allow us to centrally manage it and simplify +keeping settings in sync for all cells. + +## Pros + +1. Router is stateless and can live in many regions. We use Anycast DNS to resolve to nearest region for the user. +1. Cells can receive requests for namespaces in the wrong cell and the user + still gets the right response as well as caching at the router that + ensures the next request is sent to the correct cell so the next request + will go to the correct cell +1. The majority of the code still lives in `gitlab` rails codebase. The Router doesn't actually need to understand how GitLab URLs are composed. +1. Since the responsibility to read and write `gitlab_users`, + `gitlab_routes` and `gitlab_admin` still lives in Rails it means minimal + changes will be needed to the Rails application compared to extracting + services that need to isolate the domain models and build new interfaces. +1. Compared to a separate routing service this allows the Rails application + to encode more complex rules around how to map URLs to the correct cell + and may work for some existing API endpoints. +1. All the new infrastructure (just a router) is optional and a single-cell + self-managed installation does not even need to run the Router and there are + no other new services. + +## Cons + +1. `gitlab_users`, `gitlab_routes` and `gitlab_admin` databases may need to be + replicated across regions and writes need to go across regions. We need to + do an analysis on write TPS for the relevant tables to determine if this is + feasible. +1. Sharing access to the database from many different Cells means that they are + all coupled at the Postgres schema level and this means changes to the + database schema need to be done carefully in sync with the deployment of all + Cells. This limits us to ensure that Cells are kept in closely similar + versions compared to an architecture with shared services that have an API + we control. +1. Although most data is stored in the right region there can be requests + proxied from another region which may be an issue for certain types + of compliance. +1. Data in `gitlab_users` and `gitlab_routes` databases must be replicated in + all regions which may be an issue for certain types of compliance. +1. The router cache may need to be very large if we get a wide variety of URLs + (ie. long tail). In such a case we may need to implement a 2nd level of + caching in user cookies so their frequently accessed pages always go to the + right cell the first time. +1. Having shared database access for `gitlab_users` and `gitlab_routes` + from multiple cells is an unusual architecture decision compared to + extracting services that are called from multiple cells. +1. It is very likely we won't be able to find cacheable elements of a + GraphQL URL and often existing GraphQL endpoints are heavily dependent on + ids that won't be in the `routes` table so cells won't necessarily know + what cell has the data. As such we'll probably have to update our GraphQL + calls to include an organization context in the path like + `/api/organizations/<organization>/graphql`. +1. This architecture implies that implemented endpoints can only access data + that are readily accessible on a given Cell, but are unlikely + to aggregate information from many Cells. +1. All unknown routes are sent to the latest deployment which we assume to be `Cell US0`. + This is required as newly added endpoints will be only decodable by latest cell. + Likely this is not a problem for the `/cells/learn` is it is lightweight + to process and this should not cause a performance impact. + +## Example database configuration + +Handling shared `gitlab_users`, `gitlab_routes` and `gitlab_admin` databases, while having dedicated `gitlab_main` and `gitlab_ci` databases should already be handled by the way we use `config/database.yml`. We should also, already be able to handle the dedicated EU replicas while having a single US primary for `gitlab_users` and `gitlab_routes`. Below is a snippet of part of the database configuration for the Cell architecture described above. + +**Cell US0**: + +```yaml +# config/database.yml +production: + main: + host: postgres-main.cell-us0.primary.consul + load_balancing: + discovery: postgres-main.cell-us0.replicas.consul + ci: + host: postgres-ci.cell-us0.primary.consul + load_balancing: + discovery: postgres-ci.cell-us0.replicas.consul + users: + host: postgres-users-primary.consul + load_balancing: + discovery: postgres-users-replicas.us.consul + routes: + host: postgres-routes-primary.consul + load_balancing: + discovery: postgres-routes-replicas.us.consul + admin: + host: postgres-admin-primary.consul + load_balancing: + discovery: postgres-admin-replicas.us.consul +``` + +**Cell EU0**: + +```yaml +# config/database.yml +production: + main: + host: postgres-main.cell-eu0.primary.consul + load_balancing: + discovery: postgres-main.cell-eu0.replicas.consul + ci: + host: postgres-ci.cell-eu0.primary.consul + load_balancing: + discovery: postgres-ci.cell-eu0.replicas.consul + users: + host: postgres-users-primary.consul + load_balancing: + discovery: postgres-users-replicas.eu.consul + routes: + host: postgres-routes-primary.consul + load_balancing: + discovery: postgres-routes-replicas.eu.consul + admin: + host: postgres-admin-primary.consul + load_balancing: + discovery: postgres-admin-replicas.eu.consul +``` + +## Request flows + +1. `gitlab-org` is a top level namespace and lives in `Cell US0` in the `GitLab.com Public` organization +1. `my-company` is a top level namespace and lives in `Cell EU0` in the `my-organization` organization + +### Experience for paying user that is part of `my-organization` + +Such a user will have a default organization set to `/my-organization` and will be +unable to load any global routes outside of this organization. They may load other +projects/namespaces but their MR/Todo/Issue counts at the top of the page will +not be correctly populated in the first iteration. The user will be aware of +this limitation. + +#### Navigates to `/my-company/my-project` while logged in + +1. User is in Europe so DNS resolves to the router in Europe +1. They request `/my-company/my-project` without the router cache, so the router chooses randomly `Cell EU1` +1. The `/cells/learn` is sent to `Cell EU1`, which responds that resource lives on `Cell EU0` +1. `Cell EU0` returns the correct response +1. The router now caches and remembers any request paths matching `/my-company/*` should go to `Cell EU0` + +```mermaid +sequenceDiagram + participant user as User + participant router_eu as Router EU + participant cell_eu0 as Cell EU0 + participant cell_eu1 as Cell EU1 + user->>router_eu: GET /my-company/my-project + router_eu->>cell_eu1: /api/v4/cells/learn?method=GET&path_info=/my-company/my-project + cell_eu1->>router_eu: {path: "/my-company", cell: "cell_eu0", source: "routable"} + router_eu->>cell_eu0: GET /my-company/my-project + cell_eu0->>user: <h1>My Project... +``` + +#### Navigates to `/my-company/my-project` while not logged in + +1. User is in Europe so DNS resolves to the router in Europe +1. The router does not have `/my-company/*` cached yet so it chooses randomly `Cell EU1` +1. The `/cells/learn` is sent to `Cell EU1`, which responds that resource lives on `Cell EU0` +1. `Cell EU0` redirects them through a login flow +1. User requests `/users/sign_in`, uses random Cell to run `/cells/learn` +1. The `Cell EU1` responds with `cell_0` as a fixed route +1. User after login requests `/my-company/my-project` which is cached and stored in `Cell EU0` +1. `Cell EU0` returns the correct response + +```mermaid +sequenceDiagram + participant user as User + participant router_eu as Router EU + participant cell_eu0 as Cell EU0 + participant cell_eu1 as Cell EU1 + user->>router_eu: GET /my-company/my-project + router_eu->>cell_eu1: /api/v4/cells/learn?method=GET&path_info=/my-company/my-project + cell_eu1->>router_eu: {path: "/my-company", cell: "cell_eu0", source: "routable"} + router_eu->>cell_eu0: GET /my-company/my-project + cell_eu0->>user: 302 /users/sign_in?redirect=/my-company/my-project + user->>router_eu: GET /users/sign_in?redirect=/my-company/my-project + router_eu->>cell_eu1: /api/v4/cells/learn?method=GET&path_info=/users/sign_in + cell_eu1->>router_eu: {path: "/users", cell: "cell_eu0", source: "fixed"} + router_eu->>cell_eu0: GET /users/sign_in?redirect=/my-company/my-project + cell_eu0-->>user: <h1>Sign in... + user->>router_eu: POST /users/sign_in?redirect=/my-company/my-project + router_eu->>cell_eu0: POST /users/sign_in?redirect=/my-company/my-project + cell_eu0->>user: 302 /my-company/my-project + user->>router_eu: GET /my-company/my-project + router_eu->>cell_eu0: GET /my-company/my-project + router_eu->>cell_eu0: GET /my-company/my-project + cell_eu0->>user: <h1>My Project... +``` + +#### Navigates to `/my-company/my-other-project` after last step + +1. User is in Europe so DNS resolves to the router in Europe +1. The router cache now has `/my-company/* => Cell EU0`, so the router chooses `Cell EU0` +1. `Cell EU0` returns the correct response as well as the cache header again + +```mermaid +sequenceDiagram + participant user as User + participant router_eu as Router EU + participant cell_eu0 as Cell EU0 + participant cell_eu1 as Cell EU1 + user->>router_eu: GET /my-company/my-project + router_eu->>cell_eu0: GET /my-company/my-project + cell_eu0->>user: <h1>My Project... +``` + +#### Navigates to `/gitlab-org/gitlab` after last step + +1. User is in Europe so DNS resolves to the router in Europe +1. The router has no cached value for this URL so randomly chooses `Cell EU0` +1. `Cell EU0` redirects the router to `Cell US0` +1. `Cell US0` returns the correct response as well as the cache header again + +```mermaid +sequenceDiagram + participant user as User + participant router_eu as Router EU + participant cell_eu0 as Cell EU0 + participant cell_us0 as Cell US0 + user->>router_eu: GET /gitlab-org/gitlab + router_eu->>cell_eu0: /api/v4/cells/learn?method=GET&path_info=/gitlab-org/gitlab + cell_eu0->>router_eu: {path: "/gitlab-org", cell: "cell_us0", source: "routable"} + router_eu->>cell_us0: GET /gitlab-org/gitlab + cell_us0->>user: <h1>GitLab.org... +``` + +In this case the user is not on their "default organization" so their TODO +counter will not include their normal todos. We may choose to highlight this in +the UI somewhere. A future iteration may be able to fetch that for them from +their default organization. + +#### Navigates to `/` + +1. User is in Europe so DNS resolves to the router in Europe +1. Router does not have a cache for `/` route (specifically rails never tells it to cache this route) +1. The Router choose `Cell EU0` randomly +1. The Rails application knows the users default organization is `/my-organization`, so + it redirects the user to `/organizations/my-organization/-/dashboard` +1. The Router has a cached value for `/organizations/my-organization/*` so it then sends the + request to `POD EU0` +1. `Cell EU0` serves up a new page `/organizations/my-organization/-/dashboard` which is the same + dashboard view we have today but scoped to an organization clearly in the UI +1. The user is (optionally) presented with a message saying that data on this page is only + from their default organization and that they can change their default + organization if it's not right. + +```mermaid +sequenceDiagram + participant user as User + participant router_eu as Router EU + participant cell_eu0 as Cell EU0 + user->>router_eu: GET / + router_eu->>cell_eu0: GET / + cell_eu0->>user: 302 /organizations/my-organization/-/dashboard + user->>router: GET /organizations/my-organization/-/dashboard + router->>cell_eu0: GET /organizations/my-organization/-/dashboard + cell_eu0->>user: <h1>My Company Dashboard... X-Gitlab-Cell-Cache={path_prefix:/organizations/my-organization/} +``` + +#### Navigates to `/dashboard` + +As above, they will end up on `/organizations/my-organization/-/dashboard` as +the rails application will already redirect `/` to the dashboard page. + +### Navigates to `/not-my-company/not-my-project` while logged in (but they don't have access since this project/group is private) + +1. User is in Europe so DNS resolves to the router in Europe +1. The router knows that `/not-my-company` lives in `Cell US1` so sends the request to this +1. The user does not have access so `Cell US1` returns 404 + +```mermaid +sequenceDiagram + participant user as User + participant router_eu as Router EU + participant cell_us1 as Cell US1 + user->>router_eu: GET /not-my-company/not-my-project + router_eu->>cell_us1: GET /not-my-company/not-my-project + cell_us1->>user: 404 +``` + +#### Creates a new top level namespace + +The user will be asked which organization they want the namespace to belong to. +If they select `my-organization` then it will end up on the same cell as all +other namespaces in `my-organization`. If they select nothing we default to +`GitLab.com Public` and it is clear to the user that this is isolated from +their existing organization such that they won't be able to see data from both +on a single page. + +### Experience for GitLab team member that is part of `/gitlab-org` + +Such a user is considered a legacy user and has their default organization set to +`GitLab.com Public`. This is a "meta" organization that does not really exist but +the Rails application knows to interpret this organization to mean that they are +allowed to use legacy global functionality like `/dashboard` to see data across +namespaces located on `Cell US0`. The rails backend also knows that the default cell to render any ambiguous +routes like `/dashboard` is `Cell US0`. Lastly the user will be allowed to +navigate to organizations on another cell like `/my-organization` but when they do the +user will see a message indicating that some data may be missing (eg. the +MRs/Issues/Todos) counts. + +#### Navigates to `/gitlab-org/gitlab` while not logged in + +1. User is in the US so DNS resolves to the US router +1. The router knows that `/gitlab-org` lives in `Cell US0` so sends the request + to this cell +1. `Cell US0` serves up the response + +```mermaid +sequenceDiagram + participant user as User + participant router_us as Router US + participant cell_us0 as Cell US0 + user->>router_us: GET /gitlab-org/gitlab + router_us->>cell_us0: GET /gitlab-org/gitlab + cell_us0->>user: <h1>GitLab.org... +``` + +#### Navigates to `/` + +1. User is in US so DNS resolves to the router in US +1. Router does not have a cache for `/` route (specifically rails never tells it to cache this route) +1. The Router chooses `Cell US1` randomly +1. The Rails application knows the users default organization is `GitLab.com Public`, so + it redirects the user to `/dashboards` (only legacy users can see + `/dashboard` global view) +1. Router does not have a cache for `/dashboard` route (specifically rails never tells it to cache this route) +1. The Router chooses `Cell US1` randomly +1. The Rails application knows the users default organization is `GitLab.com Public`, so + it allows the user to load `/dashboards` (only legacy users can see + `/dashboard` global view) and redirects to router the legacy cell which is `Cell US0` +1. `Cell US0` serves up the global view dashboard page `/dashboard` which is the same + dashboard view we have today + +```mermaid +sequenceDiagram + participant user as User + participant router_us as Router US + participant cell_us0 as Cell US0 + participant cell_us1 as Cell US1 + user->>router_us: GET / + router_us->>cell_us1: GET / + cell_us1->>user: 302 /dashboard + user->>router_us: GET /dashboard + router_us->>cell_us1: /api/v4/cells/learn?method=GET&path_info=/dashboard + cell_us1->>router_us: {path: "/dashboard", cell: "cell_us0", source: "routable"} + router_us->>cell_us0: GET /dashboard + cell_us0->>user: <h1>Dashboard... +``` + +#### Navigates to `/my-company/my-other-project` while logged in (but they don't have access since this project is private) + +They get a 404. + +### Experience for non-authenticated users + +Flow is similar to logged in users except global routes like `/dashboard` will +redirect to the login page as there is no default organization to choose from. + +### A new customers signs up + +They will be asked if they are already part of an organization or if they'd +like to create one. If they choose neither they end up no the default +`GitLab.com Public` organization. + +### An organization is moved from 1 cell to another + +TODO + +### GraphQL/API requests which don't include the namespace in the URL + +TODO + +### The autocomplete suggestion functionality in the search bar which remembers recent issues/MRs + +TODO + +### Global search + +TODO + +## Administrator + +### Loads `/admin` page + +1. The `/admin` is locked to `Cell US0` +1. Some endpoints of `/admin`, like Projects in Admin are scoped to a Cell + and users needs to choose the correct one in a dropdown, which results in endpoint + like `/admin/cells/cell_0/projects`. + +Admin Area settings in Postgres are all shared across all cells to avoid +divergence but we still make it clear in the URL and UI which cell is serving +the Admin Area page as there is dynamic data being generated from these pages and +the operator may want to view a specific cell. + +## More Technical Problems To Solve + +### Replicating User Sessions Between All Cells + +Today user sessions live in Redis but each cell will have their own Redis instance. We already use a dedicated Redis instance for sessions so we could consider sharing this with all cells like we do with `gitlab_users` PostgreSQL database. But an important consideration will be latency as we would still want to mostly fetch sessions from the same region. + +An alternative might be that user sessions get moved to a JWT payload that encodes all the session data but this has downsides. For example, it is difficult to expire a user session, when their password changes or for other reasons, if the session lives in a JWT controlled by the user. + +### How do we migrate between Cells + +Migrating data between cells will need to factor all data stores: + +1. PostgreSQL +1. Redis Shared State +1. Gitaly +1. Elasticsearch + +### Is it still possible to leak the existence of private groups via a timing attack? + +If you have router in EU, and you know that EU router by default redirects +to EU located Cells, you know their latency (lets assume 10 ms). Now, if your +request is bounced back and redirected to US which has different latency +(lets assume that roundtrip will be around 60 ms) you can deduce that 404 was +returned by US Cell and know that your 404 is in fact 403. + +We may defer this until we actually implement a cell in a different region. Such timing attacks are already theoretically possible with the way we do permission checks today but the timing difference is probably too small to be able to detect. + +One technique to mitigate this risk might be to have the router add a random +delay to any request that returns 404 from a cell. + +## Should runners be shared across all cells? + +We have 2 options and we should decide which is easier: + +1. Decompose runner registration and queuing tables and share them across all + cells. This may have implications for scalability, and we'd need to consider + if this would include group/project runners as this may have scalability + concerns as these are high traffic tables that would need to be shared. +1. Runners are registered per-cell and, we probably have a separate fleet of + runners for every cell or just register the same runners to many cells which + may have implications for queueing + +## How do we guarantee unique ids across all cells for things that cannot conflict? + +This project assumes at least namespaces and projects have unique ids across +all cells as many requests need to be routed based on their ID. Since those +tables are across different databases then guaranteeing a unique ID will +require a new solution. There are likely other tables where unique IDs are +necessary and depending on how we resolve routing for GraphQL and other APIs +and other design goals it may be determined that we want the primary key to be +unique for all tables. diff --git a/doc/architecture/blueprints/ci_data_decay/index.md b/doc/architecture/blueprints/ci_data_decay/index.md index e26e7d5dbd3..2eac27def18 100644 --- a/doc/architecture/blueprints/ci_data_decay/index.md +++ b/doc/architecture/blueprints/ci_data_decay/index.md @@ -8,12 +8,14 @@ owning-stage: "~devops::verify" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # CI/CD data time decay ## Summary GitLab CI/CD is one of the most data and compute intensive components of GitLab. -Since its [initial release in November 2012](https://about.gitlab.com/blog/2012/11/13/continuous-integration-server-from-gitlab/), +Since its initial release in 2012, the CI/CD subsystem has evolved significantly. It was [integrated into GitLab in September 2015](https://about.gitlab.com/releases/2015/09/22/gitlab-8-0-released/) and has become [one of the most beloved CI/CD solutions](https://about.gitlab.com/blog/2017/09/27/gitlab-leader-continuous-integration-forrester-wave/). @@ -231,7 +233,7 @@ In progress. - 2022-02-08: Pipeline partitioning PoC [merge request](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/80186) started. - 2022-02-23: Pipeline partitioning PoC [successful](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/80186#note_852704724) - 2022-03-07: A way to attach an existing table as a partition [found and proven](https://gitlab.com/gitlab-org/gitlab/-/issues/353380#note_865237214). -- 2022-03-23: Pipeline partitioning design [Google Doc](https://docs.google.com/document/d/1ARdoTZDy4qLGf6Z1GIHh83-stG_ZLpqsibjKr_OXMgc) started. +- 2022-03-23: Pipeline partitioning design Google Doc (GitLab internal) started: `https://docs.google.com/document/d/1ARdoTZDy4qLGf6Z1GIHh83-stG_ZLpqsibjKr_OXMgc`. - 2022-03-29: Pipeline partitioning PoC [concluded](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/80186#note_892674358). - 2022-04-15: Partitioned pipeline data associations PoC [shipped](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/84071). - 2022-04-30: Additional [benchmarking started](https://gitlab.com/gitlab-org/gitlab/-/issues/361019) to evaluate impact. diff --git a/doc/architecture/blueprints/ci_data_decay/pipeline_partitioning.md b/doc/architecture/blueprints/ci_data_decay/pipeline_partitioning.md index ebe3c72adfc..5dea1090507 100644 --- a/doc/architecture/blueprints/ci_data_decay/pipeline_partitioning.md +++ b/doc/architecture/blueprints/ci_data_decay/pipeline_partitioning.md @@ -1,10 +1,15 @@ --- -stage: none -group: unassigned -comments: false +status: ongoing +creation-date: "2022-05-31" +authors: [ "@grzesiek" ] +coach: [ "@ayufan", "@grzesiek" ] +approvers: [ "@jreporter", "@cheryl.li" ] +owning-stage: "~devops::verify" description: 'Pipeline data partitioning design' --- +<!-- vale gitlab.FutureTense = NO --> + # Pipeline data partitioning design ## What problem are we trying to solve? @@ -803,9 +808,11 @@ DRIs: | Role | Who | |---------------------|------------------------------------------------| | Author | Grzegorz Bizon, Principal Engineer | -| Recommender | Kamil Trzciński, Senior Distingiushed Engineer | -| Product Manager | James Heimbuck, Senior Product Manager | -| Engineering Manager | Scott Hampton, Engineering Manager | +| Recommender | Kamil Trzciński, Senior Distinguished Engineer | +| Product Leadership | Jackie Porter, Director of Product Management | +| Engineering Leadership | Caroline Simpson, Engineering Manager / Cheryl Li, Senior Engineering Manager | | Lead Engineer | Marius Bobin, Senior Backend Engineer | +| Senior Engineer | Maxime Orefice, Senior Backend Engineer | +| Senior Engineer | Tianwen Chen, Senior Backend Engineer | <!-- vale gitlab.Spelling = YES --> diff --git a/doc/architecture/blueprints/ci_pipeline_components/dev_workflow.md b/doc/architecture/blueprints/ci_pipeline_components/dev_workflow.md new file mode 100644 index 00000000000..fd897781cf5 --- /dev/null +++ b/doc/architecture/blueprints/ci_pipeline_components/dev_workflow.md @@ -0,0 +1,154 @@ +--- +stage: verify +group: pipeline authoring +description: 'Development workflow for a components repository' +--- + +# Development workflow for a components repository + +## Summary + +This page describes the process of creating a components repository. +It describes all the necessary steps, from the creation of the project to having new releases displayed in the +catalog page. + +## 1. Create a new project + +First, create a new project and add a `README.md` file, which is a planned future +requirement for a repository to become a catalog resource. + +## 2. Create a component inside the repository + +If you intend to have only one component in the repository, you can define it in the root directory. +Otherwise, create a directory for the component. +For more information, see the [directory structure of a components repository](index.md#structure-of-a-components-repository). + +This example defines a single component in the root directory. + +Create a `template.yml` file that contains the configuration we want to provide as a component: + +```yaml +spec: + inputs: + stage: + default: test +--- +.component-default-job: + image: busybox + stage: $[[ inputs.stage ]] + +component-job-1: + extends: .component-default-job + script: echo job 1 + +component-job-2: + extends: .component-default-job + script: echo job 2 +``` + +The example component configuration above adds two jobs, `component-job-1` and `component-job-2`, to a pipeline. + +## 3. Test changes in CI + +To test any changes pushed to our component, we create a `.gitlab-ci.yml` in the root directory: + +```yaml +## +# This configuration expects an access token with read-only access to the API +# to be saved as in a masked CI/CD variable named 'API_TOKEN' + +include: + # Leverage predefined variables to refer to the current project and SHA + - component: gitlab.com/$CI_PROJECT_PATH@$CI_COMMIT_SHA + +stages: [test, release] + +# Expect all `component-job-*` jobs are added +ensure-jobs-added: + image: badouralix/curl-jq + script: + - | + route="https://gitlab.com/api/v4/projects/$CI_PROJECT_ID/pipelines/$CI_PIPELINE_ID/jobs" + count=`curl --silent --header "PRIVATE-TOKEN: $API_TOKEN" $route | jq 'map(select(.name | contains("component-job-"))) | length'` + if [ "$count" != "2" ]; then + exit 1 + fi + +# Ensure that a project description exists, because it will be important to display +# the resource in the catalog. +check-description: + image: badouralix/curl-jq + script: + - | + route="https://gitlab.com/api/v4/projects/$CI_PROJECT_ID" + desc=`curl --silent --header "PRIVATE-TOKEN: $API_TOKEN" $route | jq '.description'` + if [ "$desc" = "null" ]; then + echo "Description not set. Please set a projet description" + exit 1 + else + echo "Description set" + fi + +# Ensure that a `README.md` exists in the root directory as it represents the +# documentation for the whole components repository. +check-readme: + image: busybox + script: ls README.md || (echo "Please add a README.md file" && exit 1) + +# If we are tagging a release with a specific convention ("v" + number) and all +# previous checks succeeded, we proceed with creating a release automatically. +create-release: + stage: release + image: registry.gitlab.com/gitlab-org/release-cli:latest + rules: + - if: $CI_COMMIT_TAG =~ /^v\d+/ + script: echo "Creating release $CI_COMMIT_TAG" + release: + tag_name: $CI_COMMIT_TAG + description: "Release $CI_COMMIT_TAG of components repository $CI_PROJECT_PATH" +``` + +This pipeline contains examples of several tasks: + +- Use the component to ensure that the final configuration uses valid syntax. + This also ensures that the minimal requirements for the component to work are in place, + like inputs and secrets. +- Test that the created pipeline has the expected characteristics. + For example, ensure the `component-job-*` jobs are added to the pipeline. + - We call the [pipeline API endpoint](../../../api/pipelines.md#get-a-single-pipeline) with `curl` + and parse the data via `jq`. + - With this technique users could check things like ensuring certain jobs were included, + the job has the right properties set, or the log contains the expected output. +- Ensure that the project description is set. +- Ensure that the repository contains a `README.md` file. +- Create a [release automatically](../../../ci/yaml/index.md#release). When a tag is created and follows specific regex, create a release + after all previous checks pass. + +## 4. Run a pipeline + +Now run a new pipeline for the `main` branch, by pushing a change or manually running a pipeline: + + + +## 5. Create a tag + +As the pipeline for `main` is green, we can now [create our first tag](../../../user/project/repository/tags/index.md#create-a-tag): `v1.0`. + +As soon as the `v1.0` tag is created, we see a tag pipeline start. +This time the pipeline also has a `create-release` job in the `release` stage: + + + +When the `create-release` job finishes we should see the new release available in the **Releases** menu: + + + +## 6. Publish the repository to the catalog + +To ensure that both the components repository and the new release is visible in the CI Catalog, +we need to publish it. + +Publishing a components repository makes it a catalog resource. + +The API endpoint for this action is under development. +For more details read the [issue](https://gitlab.com/gitlab-org/gitlab/-/issues/387065). diff --git a/doc/architecture/blueprints/ci_pipeline_components/img/new_release.png b/doc/architecture/blueprints/ci_pipeline_components/img/new_release.png Binary files differnew file mode 100644 index 00000000000..eed5c55d5e3 --- /dev/null +++ b/doc/architecture/blueprints/ci_pipeline_components/img/new_release.png diff --git a/doc/architecture/blueprints/ci_pipeline_components/img/pipeline_main.png b/doc/architecture/blueprints/ci_pipeline_components/img/pipeline_main.png Binary files differnew file mode 100644 index 00000000000..8b03b96ba7e --- /dev/null +++ b/doc/architecture/blueprints/ci_pipeline_components/img/pipeline_main.png diff --git a/doc/architecture/blueprints/ci_pipeline_components/img/pipeline_tag.png b/doc/architecture/blueprints/ci_pipeline_components/img/pipeline_tag.png Binary files differnew file mode 100644 index 00000000000..d0814a479ae --- /dev/null +++ b/doc/architecture/blueprints/ci_pipeline_components/img/pipeline_tag.png diff --git a/doc/architecture/blueprints/ci_pipeline_components/index.md b/doc/architecture/blueprints/ci_pipeline_components/index.md index b1aee7c4217..ff4604b61bf 100644 --- a/doc/architecture/blueprints/ci_pipeline_components/index.md +++ b/doc/architecture/blueprints/ci_pipeline_components/index.md @@ -8,6 +8,8 @@ owning-stage: "~devops::verify" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # CI/CD Catalog ## Summary @@ -92,9 +94,13 @@ This section defines some terms that are used throughout this document. With the identifying abstract concepts and are subject to changes as we refine the design by discovering new insights. - **Component** Is the reusable unit of pipeline configuration. -- **Project** Is the GitLab project attached to a repository. A project can contain multiple components. -- **Catalog** is the collection of projects that are set to contain components. -- **Version** is the release name of a tag in the project, which allows components to be pinned to a specific revision. +- **Components repository** represents a collection of CI components stored in the same project. +- **Project** is the GitLab project attached to a single components repository. +- **Catalog** is a collection of resources like components repositories. +- **Catalog resource** is the single item displayed in the catalog. A components repository is a catalog resource. +- **Version** is a specific revision of catalog resource. It maps to the released tag in the project, + which allows components to be pinned to a specific revision. +- **Steps** is a collection of instructions for how jobs can be executed. ## Definition of pipeline component @@ -128,7 +134,7 @@ Eventually, we want to make CI Catalog Components predictable. Including a component by its path, using a fixed `@` version, should always return the same configuration, regardless of a context from which it is getting included from. The resulting configuration should be the same for a given component version -and the set of inputs passed using `with:` keyword, hence it should be +and the set of inputs passed using `include:inputs` keyword, therefore it should be [deterministic](https://en.wikipedia.org/wiki/Deterministic_algorithm). A component should not produce side effects by being included and should be @@ -202,7 +208,6 @@ A component YAML file: - Should be **validated statically** (for example: using JSON schema validators). ```yaml ---- spec: inputs: website: @@ -217,18 +222,14 @@ spec: # content of the component ``` -Components that are released in the catalog must have a `README.md` file at the root directory of the repository. -The `README.md` represents the documentation for the specific component, hence it's recommended -even when not releasing versions in the catalog. - ### The component version The version of the component can be (in order of highest priority first): 1. A commit SHA - For example: `gitlab.com/gitlab-org/dast@e3262fdd0914fa823210cdb79a8c421e2cef79d8` -1. A released tag - For example: `gitlab.com/gitlab-org/dast@1.0` -1. A special moving target version that points to the most recent released tag - For example: `gitlab.com/gitlab-org/dast@~latest` -1. An unreleased tag - For example: `gitlab.com/gitlab-org/dast@rc-1.0` +1. A tag - For example: `gitlab.com/gitlab-org/dast@1.0` +1. A special moving target version that points to the most recent released tag. The target project must be +explicitly marked as a [catalog resource](#catalog-resource) - For example: `gitlab.com/gitlab-org/dast@~latest` 1. A branch name - For example: `gitlab.com/gitlab-org/dast@master` If a tag and branch exist with the same name, the tag takes precedence over the branch. @@ -237,26 +238,31 @@ takes precedence over the tag. As we want to be able to reference any revisions (even those not released), a component must be defined in a Git repository. -NOTE: When referencing a component by local path (for example `./path/to/component`), its version is implicit and matches the commit SHA of the current pipeline context. -## Components project +## Components repository -A components project is a GitLab project/repository that exclusively hosts one or more pipeline components. +A components repository is a GitLab project/repository that exclusively hosts one or more pipeline components. -For components projects it's highly recommended to set an appropriate avatar and project description -to improve discoverability in the catalog. +A components repository can be a catalog resource. For a components repository it's highly recommended to set +an appropriate avatar and project description to improve discoverability in the catalog. -### Structure of a components project +Components repositories that are released in the catalog must have a `README.md` file at the root directory of the repository. +The `README.md` represents the documentation of the components repository, hence it's recommended +even when not listing the repository in the catalog. -A project can host one or more components depending on whether the author wants to define a single component -per project or include multiple cohesive components under the same project. +### Structure of a components repository -Let's imagine we are developing a component that runs RSpec tests for a Rails app. We create a component project +A components repository can host one or more components. The author can decide whether to define a single component +per repository or include multiple cohesive components in the same repository. + +A components repository is identified by the project full path. + +Let's imagine we are developing a component that runs RSpec tests for a Rails app. We create a project called `myorg/rails-rspec`. -The following directory structure would support 1 component per project: +The following directory structure would support 1 component per repository: ```plaintext . @@ -267,10 +273,10 @@ The following directory structure would support 1 component per project: The `.gitlab-ci.yml` is recommended for the project to ensure changes are verified accordingly. -The component is now identified by the path `gitlab.com/myorg/rails-rspec` and we expect a `template.yml` file -and `README.md` located in the root directory of the repository. +The component is now identified by the path `gitlab.com/myorg/rails-rspec` which also maps to the +project path. We expect a `template.yml` file and `README.md` to be located in the root directory of the repository. -The following directory structure would support multiple components per project: +The following directory structure would support multiple components per repository: ```plaintext . @@ -319,7 +325,6 @@ This limitation encourages cohesion at project level and keeps complexity low. If the component takes any input parameters they must be specified according to the following schema: ```yaml ---- spec: inputs: website: # by default all declared inputs are mandatory. @@ -346,13 +351,13 @@ When using the component we pass the input parameters as follows: ```yaml include: - component: gitlab.com/org/my-component@1.0 - with: + inputs: website: ${MY_WEBSITE} # variables expansion test_run: system environment: $[[ inputs.environment ]] # interpolation of upstream inputs ``` -Variables expansion must be supported for `with:` syntax as well as interpolation of +Variables expansion must be supported for `include:inputs` syntax as well as interpolation of possible [inputs provided upstream](#input-parameters-for-pipelines). Input parameters are validated as soon as possible: @@ -363,7 +368,6 @@ Input parameters are validated as soon as possible: 1. Interpolate input parameters inside the component's content. ```yaml ---- spec: inputs: environment: @@ -383,8 +387,8 @@ With `$[[ inputs.XXX ]]` inputs are interpolated immediately after parsing the c ### CI configuration interpolation perspectives and limitations -With `spec:` users will be able to define input arguments for CI configuration. -With `with:` keywords, they will pass these arguments to CI components. +With `spec:inputs` users will be able to define input arguments for CI configuration. +With `include:inputs`, they will pass these arguments to CI components. `inputs` in `$[[ inputs.something ]]` is going to be an initial "object" or "container" that we will provide, to allow users to access their arguments in @@ -427,32 +431,31 @@ enforce contracts. ### Input parameters for existing `include:` syntax Because we are adding input parameters to components used via `include:component` we have an opportunity to -extend it to other `include:` types support inputs via `with:` syntax: +extend it to other `include:` types support inputs through `inputs:` syntax: ```yaml include: - component: gitlab.com/org/my-component@1.0 - with: + inputs: foo: bar - local: path/to/file.yml - with: + inputs: foo: bar - project: org/another file: .gitlab-ci.yml - with: + inputs: foo: bar - remote: http://example.com/ci/config - with: + inputs: foo: bar - template: Auto-DevOps.gitlab-ci.yml - with: + inputs: foo: bar ``` Then the configuration being included must specify the inputs by defining a specification section in the YAML: ```yaml ---- spec: inputs: foo: @@ -460,15 +463,15 @@ spec: # rest of the configuration ``` -If a YAML includes content using `with:` but the including YAML doesn't define `inputs:` in the specifications, +If a YAML includes content using `include:inputs` but the including YAML doesn't define `spec:inputs` in the specifications, an error should be raised. -|`with:`| `inputs:` | result | -| --- | --- | --- | -| specified | | raise error | -| specified | specified | validate inputs | -| | specified | use defaults | -| | | legacy `include:` without input passing | +| `include:inputs` | `spec:inputs` | result | +|------------------|---------------|-----------------------------------------| +| specified | | raise error | +| specified | specified | validate inputs | +| | specified | use defaults | +| | | legacy `include:` without input passing | ### Input parameters for pipelines @@ -488,7 +491,7 @@ Today we have different use cases where using explicit input parameters would be deploy-app: trigger: project: org/deployer - with: + inputs: provider: aws deploy_environment: staging ``` @@ -496,7 +499,6 @@ deploy-app: To solve the problem of `Run Pipeline` UI form we could fully leverage the `inputs` specifications: ```yaml ---- spec: inputs: concurrency: @@ -516,35 +518,114 @@ spec: # rest of the pipeline config ``` -### Limits +## CI Catalog -Any MVC that exposes a feature should be added with limitations from the beginning. -It's safer to add new features with restrictions than trying to limit a feature after it's being used. -We can always soften the restrictions later depending on user demand. +The CI Catalog is an index of resources that users can leverage in CI/CD. It initially +contains a list of components repositories that users can discover and use in their pipelines. -Some limits we could consider adding: +In the future, the Catalog could contain also other types of resources (for example: +integrations, project templates, etc.). -- number of components that a single project can contain/export -- number of imports that a `.gitlab-ci.yml` file can use -- number of imports that a component can declare/use -- max level of nested imports -- max length of the exported component name +To list a components repository in the Catalog we need to mark the project as being a +catalog resource. We do that initially with an API endpoint, similar to changing a project setting. + +Once a project is marked as a "catalog resource" it can be displayed in the Catalog. + +We could create a database record when the API endpoint is used and remove the record when +the same is disabled/removed. + +## Catalog resource + +Upon publishing, a catalog resource should have at least following attributes: + +- `path`: to be uniquely identified. +- `name`: for components repository this could be the project name. +- `documentation`: we would use the `README.md` file which would be mandatory. +- `versions`: one or more releases of the resource. + +Other properties of a catalog resource: + +- `description`: for components repository this could be the project description. +- `avatar image`: we could use the project avatar. +- indicators of popularity (stars, forks). +- categorization: user should select a category and or define search tags + +As soon as a components repository is marked as being a "catalog resource" +we should be seeing the resource listed in the Catalog. + +Initially for the resource, the project may not have any released tags. +Users would be able to use the components repository by specifying a branch name or +commit SHA for the version. However, these types of version qualifiers should not +be listed in the catalog resource's page for various reasons: + +- The list of branches and tags can get very large. +- Branches and tags may not be meaningful for the end-user. +- Branches and tags don't communicate versioning thoroughly. -## Publishing components +## Releasing new resource versions to the Catalog -Users will be able to publish CI Components into a CI Catalog. This can happen -in a CI pipeline job, similarly to how software is being deployed following -Continuous Delivery principles. This will allow us to guardrail the quality of -components being deployed. To ensure that the CI Components meet quality -standards users will be able to test them before publishing new versions in the +The versions that should be displayed for the resource should be the project [releases](../../../user/project/releases/index.md). +Creating project releases is an official act of versioning a resource. + +A resource page would have: + +- The latest release in evidence (for example: the default version). +- The ability to inspect and use past releases of the resource. +- The documentation represented by the `README.md`. + +Users should be able to release new versions of the resource in a CI pipeline job, +similar to how software is being deployed following Continuous Delivery principles. + +To ensure that the components repository and the including components +meet quality standards, users can test them before releasing new versions in the CI Catalog. -Once a project containing components gets published we will index components' +Some examples of checks we can run during the release of a new resource version: + +- Ensure the project contains a `README.md` in the root directory. +- Ensure the project description exists. +- If an index of available components is present for a components repository, ensure each + component has valid YAML. + +Once a new release for the project gets created we index the resource's metadata. We want to initially index as much metadata as possible, to gain more flexibility in how we design CI Catalog's main page. We don't want to be -constrained by the lack of data available to properly visualize CI Components -in CI Catalog. In order to do that, we may need to find all components that are -being published, read their `spec` metadata and index what we find there. +constrained by the lack of data available to properly visualize resources in +the CI Catalog. To do that, we may need to find all resources that are +being released and index their data and metadata. +For example: index the content of `spec:` section for CI components. + +See an [example of development workflow](dev_workflow.md) for a components repository. + +## Note about future resource types + +In the future, to support multiple types of resources in the Catalog we could +require a file `catalog-resource.yml` to be defined in the root directory of the project: + +```yaml +name: DAST +description: Scan a web endpoint to find vulnerabilities +category: security +tags: [dynamic analysis, security scanner] +type: components_repository +``` + +This file could also be used for indexing metadata about the content of the resource. +For example, users could list the components in the repository and we can index +further data for search purpose: + +```yaml +name: DAST +description: Scan a web endpoint to find vulnerabilities +category: security +tags: [dynamic analysis, security scanner] +type: components_repository +metadata: + components: + - all-scans + - scan-x + - scan-y +``` ## Implementation guidelines @@ -585,6 +666,20 @@ being published, read their `spec` metadata and index what we find there. components from GitLab.com or from repository exports. - Iterate on feedback. +## Limits + +Any MVC that exposes a feature should be added with limitations from the beginning. +It's safer to add new features with restrictions than trying to limit a feature after it's being used. +We can always soften the restrictions later depending on user demand. + +Some limits we could consider adding: + +- number of components that a single project can contain/export +- number of imports that a `.gitlab-ci.yml` file can use +- number of imports that a component can declare/use +- max level of nested imports +- max length of the exported component name + ## Who Proposal: @@ -612,6 +707,6 @@ Domain experts: | Area | Who |------------------------------|------------------------| | Verify / Pipeline authoring | Avielle Wolfe | -| Verify / Pipeline authoring | Laura Montemayor-Rodriguez | +| Verify / Pipeline authoring | Laura Montemayor | <!-- vale gitlab.Spelling = YES --> diff --git a/doc/architecture/blueprints/ci_scale/index.md b/doc/architecture/blueprints/ci_scale/index.md index cf7065f7c07..3a6ed4ae9b1 100644 --- a/doc/architecture/blueprints/ci_scale/index.md +++ b/doc/architecture/blueprints/ci_scale/index.md @@ -7,12 +7,14 @@ approvers: [ "@cheryl.li", "@jreporter" ] owning-stage: "~devops::verify" --- +<!-- vale gitlab.FutureTense = NO --> + # CI/CD Scaling ## Summary GitLab CI/CD is one of the most data and compute intensive components of GitLab. -Since its [initial release in November 2012](https://about.gitlab.com/blog/2012/11/13/continuous-integration-server-from-gitlab/), +Since its initial release in 2012, the CI/CD subsystem has evolved significantly. It was [integrated into GitLab in September 2015](https://about.gitlab.com/releases/2015/09/22/gitlab-8-0-released/) and has become [one of the most beloved CI/CD solutions](https://about.gitlab.com/blog/2017/09/27/gitlab-leader-continuous-integration-forrester-wave/). diff --git a/doc/architecture/blueprints/clickhouse_ingestion_pipeline/clickhouse_dbwriter.png b/doc/architecture/blueprints/clickhouse_ingestion_pipeline/clickhouse_dbwriter.png Binary files differnew file mode 100644 index 00000000000..fc65830d3ee --- /dev/null +++ b/doc/architecture/blueprints/clickhouse_ingestion_pipeline/clickhouse_dbwriter.png diff --git a/doc/architecture/blueprints/clickhouse_ingestion_pipeline/index.md b/doc/architecture/blueprints/clickhouse_ingestion_pipeline/index.md new file mode 100644 index 00000000000..94714e7b245 --- /dev/null +++ b/doc/architecture/blueprints/clickhouse_ingestion_pipeline/index.md @@ -0,0 +1,289 @@ +--- +status: proposed +creation-date: "2023-01-10" +authors: [ "@ankitbhatnagar", "@ahegyi", "@mikolaj_wawrzyniak" ] +coach: "@grzesiek" +approvers: [ "@nhxnguyen", "@stkerr" ] +owning-stage: "~workinggroup::clickhouse" +participating-stages: [ "~section::ops", "~section::dev" ] +--- + +# Scalable data ingestion abstraction for ClickHouse + +## Table of Contents + +- [Summary](#summary) + - [Why](#why) + - [How](#how) +- [Motivation](#motivation) +- [Case Studies](#case-studies) + - [Replicating existing data into ClickHouse](#1-replicating-existing-data-into-clickhouse) + - [Ingesting large volumes of data into ClickHouse](#2-ingesting-large-volumes-of-data-into-clickhouse) +- [Goals](#goals) +- [Non-goals](#non-goals) +- [General considerations](#general-considerations) +- [Challenges building this](#major-challenges-around-building-such-a-capability) +- [Proposed solution](#proposed-solution) +- [Design & Implementation](#design--implementation) +- [References](#references) + +## Summary + +Develop a scalable & reliable data ingestion abstraction to help efficiently ingest large volumes of data from high throughput systems into ClickHouse. + +### Why + +To enable any application at GitLab to write necessary data into ClickHouse regardless of the scale at which they generate data today, or in the future. Refer to [Motivation](#motivation) for why ClickHouse in the first place. + +### How + +By building a write abstraction (API/Library) that allows a user to write data into ClickHouse and has all necessary configurations, conventions and best-practices around instrumentation, service-discovery, etc, built into it out of the box. + +## Motivation + +ClickHouse is an online, analytical processing (OLAP) database that powers use-cases that require fetching real-time, aggregated data that does not mutate a lot. ClickHouse is highly performant and can scale to large volumes of data as compared to traditional transactional relational databases (OLTP) such as Postgres, MySQL. For further reading around ClickHouse's capabilities, see [[1]](https://about.gitlab.com/blog/2022/04/29/two-sizes-fit-most-postgresql-and-clickhouse/), [[2]](https://clickhouse.com/blog/migrating-data-between-clickhouse-postgres) and [[3]](https://posthog.com/blog/clickhouse-vs-postgres). + +At GitLab, [our current and future ClickHouse uses/capabilities](https://gitlab.com/groups/gitlab-com/-/epics/2075) reference & describe multiple use-cases that could be facilitated by using ClickHouse as a backing datastore. A majority of these talk about the following two major areas of concern: + +1. Being able to leverage [ClickHouse's OLAP capabilities](https://clickhouse.com/docs/en/faq/general/olap/) enabling underlying systems to perform an aggregated analysis of data, both over short and long periods of time. +1. The fact that executing these operations with our currently existing datasets primarily in Postgres, is starting to become challenging and non-performant. + +Looking forward, assuming a larger volume of data being produced by our application(s) and the rate at which it gets produced, the ability to ingest it into a *more* capable system, both effectively and efficiently helps us scale our applications and prepare for business growth. + +## Case studies + +From an initial assessment of all (reported) use-cases that intend to utilise ClickHouse, the following broad patterns of usage can be observed: + +1. Efficiently replicating existing data from other databases into ClickHouse, most prominently Postgres. +1. Directly ingesting large volumes of data into ClickHouse for asynchronous processing, data aggregation & analysis. + +The following section(s) explain details of each problem-domain: + +### 1. Replicating existing data into ClickHouse + +With due reference to our prior work around this, it has been established that logical replication from Postgres is too slow. Instead, we'll need to be able to emit data change events within database transactions which can then get processed asynchronously to write or update corresponding data in ClickHouse. + +The following case-studies describe how these groups intend to solve the underlying problem: + +- ~group::optimize has been working towards a scalable PostgreSQL data replication strategy which can be implemented on the application layer. + + - [Proposal: Scalable data sync/replication strategy](https://gitlab.com/gitlab-org/gitlab/-/issues/382172) talks about such a strategy and the additional challenges with using Sidekiq for queueing/batching needs. + + - It has been observed that pumping data from `PostgreSQL` into `ClickHouse` directly might not be the right way to approach the problem at hand. + + - In addition to the problems described above, another class of problems when replicating data across systems is also the handling of data backfill and/or data migrations that happen upstream. + +- [group::data](https://about.gitlab.com/handbook/business-technology/data-team/) has been working around syncing data from some of our Postgres databases into a Snowflake-based data warehouse. See this issue for optioned considered: [List down all possible options for postgres to snowflake pipeline](https://gitlab.com/gitlab-data/gitlab.com-saas-data-pipeline/-/issues/13) before designing the current system in place. + + - With the work done around our [Next Gen GitLab SaaS Data Pipeline](https://docs.google.com/presentation/d/1hVaCY42YhaO5UvgLzp3mbuMYJIFuTFYFJjdhixFTxPE/edit#slide=id.g143a48de8a3_0_0), the data team owns a "custom" pipeline that does incremental data extractions based on an `updated_at` timestamp column. This helps import a significant subset of operational database relations into Snowflake data-warehouse. + + - As the volume of data grows, we can foresee this (ETL) pipeline warranting more time and resources to execute resulting in delays across the time between data being produced and being available in Snowflake data-warehouse. + + - We might also see data inconsistency/incompleteness issues emanating from the current setup since row deletions are not transferred into Snowflake, inflating data volume and skewing analysis. Any information about multiple updates happening between import interval period are also lost. + + - Having a scalable ingestion pipeline that can help replicate data from our databases into an intermediate system and/or ClickHouse in near real-time would help improve the operational characteristics around this system. + +### 2. Ingesting large volumes of data into ClickHouse + +We need to be able to ingest large volumes of potentially unaggregated data into ClickHouse which may result into a large number of small writes as well. This can have an adverse effect on how ClickHouse processes and stores incoming data. To mitigate this problem, we need to queue & batch smaller writes into larger ones to keep the ingestion pipeline efficient at all times. + +The following case-studies describe how each group intends to solve the underlying problem: + +- ~group::observability explains their need of ingesting large amounts of data into ClickHouse, with the following two issues: + + - [Proposal: GitLab Observability Platform - Data Ingestion](https://gitlab.com/gitlab-org/opstrace/opstrace/-/issues/1878) talks about using an external events store, such as Kafka, to first ingest data as received from users, then writing it into ClickHouse in larger batches thereby eliminating the need to write a large number of small writes without hampering write performance from how ClickHouse `MergeTree` processes ingested data. + + - In addition, [ClickHouse: Investigate client-side buffering to batch writes into ClickHouse](https://gitlab.com/gitlab-org/opstrace/opstrace/-/issues/2044) talks about their experimentation with using application-local queueing/batching to work around the problems mentioned above. + +- ~"group::product intelligence" has been working on building our analytics offering and recently looking at building and/or improving parts of the system. + + - [Product Analytics Collector Component](https://gitlab.com/groups/gitlab-org/-/epics/9346) talks about replacing Jitsu with Snowplow for collecting and processing tracking events. For more details of the proposal, see [Jitsu replacement](https://gitlab.com/gitlab-org/analytics-section/product-intelligence/proposals/-/blob/62d332baf5701810d9e7a0b2c00df18431e82f22/doc/jitsu_replacement.md). + + - The initial design was prototyped with [Snowplow as Jitsu Replacement PoC](https://gitlab.com/gitlab-org/analytics-section/product-analytics/devkit/-/merge_requests/37). + + - From the design, it is easy to observe how large amounts of data will be ingested into ClickHouse and could potentially benefit from the use of a scalable ingestion pipeline. + +## Goals + +### Well-defined, established client abstractions + +We want to define and establish a fully-functional application-side abstraction that can help ingest data into ClickHouse without getting in the way of how an application itself is designed while keeping the underlying code backend-agnostic. The proposed abstraction should become the default choice for any applications, core or satellite, at GitLab. + +### Support for high throughput in volume of writes + +A solution here should enable an application to write any amount of inserts (order of upto 1000-5000 writes per second) to the underlying database efficiently while also allowing for growth as the application scales out. Considering how ClickHouse processes incoming writes, a proposed solution should be able to batch a number of very small writes into larger batches. + +### Reliable, consistent delivery of data + +A solution here should also ensure reliable & consistent delivery of ingested data into the underlying database minimising undue loss of data before being eventually persisted into ClickHouse. + +## Non-goals + +### Addressing data types, schemas or formats + +At this stage of this proposal, we're not optimizing for addressing which data types, schemas or formats we receive ingested data in. It should be delegated to the backend-specific implementations themselves and not handled within the write abstraction. + +### Addressing where our data sources exist today + +We're also not addressing any client-side specific details into the design at this point. The write abstraction should only remain a tool for the language in which it is written. As long as an application can use it to write data as any other third-party library, we should be good to build on top of it. + +## General Considerations + +Having addressed the details of the two aformentioned problem-domains, we can model a proposed solution with the following logical structure: + +- Ingestion + - APIs/SDKs + - HTTP2/gRPC Sidecar +- Transport & Routing + - Multi-destination +- Digestion/Compute + - Enrichment + - Processing + - Persisting + +## Major challenges around building such a capability + +### Self-managed environments + +The single, biggest challenge around introducing ClickHouse and related systems would be the ability to make it avaiable to our users running GitLab in self-managed environments. The intended goals of this proposal are intentionally kept within those constraints. It is also prudent to establish that what we're *proposing* here be applicable to applications consuming ClickHouse from inside self-managed environments. + +There are ongoing efforts to streamline distribution and deployment of ClickHouse instances for managed environment within the larger scope of [ClickHouse Usage at GitLab](../clickhouse_usage/index.md). A few other issues tackling parts of the aforementioned problem are: + +- [Research and understand component costs and maintenance requirements of running a ClickHouse instance with GitLab](https://gitlab.com/gitlab-com/www-gitlab-com/-/issues/14384) +- [ClickHouse maintenance and cost research](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/116669) + +### Wide variety of data sources, their structures & usage patterns + +The data that we intend to ingest into ClickHouse can come from a wide variety of data sources and be structured in different schemas or formats. With that considered, it's non-trivial effort to draft a solution that suffices all use-cases efficiently. + +Should we decide to build an intermediate ingestion system, any solution should help provide a source/schema/format-agnostic data transport layer with an established, matured client-abstraction to maximise the number of applications that can use it. + +### Building on top of our current database infrastructure + +Our current database infrastructure operates at a fairly large scale and adding more applications that continuously read/write against it adds to the pressure on the existing resources. It's important we move away any workloads and/or datasets that can be safely processed in a different context altogether. + +### Service Discovery + +We're still normalising the details around distribution and deployment of ClickHouse clusters and/or instances for our applications. Subject to how we end up doing it, for a client to be able to discover which ClickHouse cluster, shard or table would need to become a part any such solution. + +## Proposed Solution + +In light of the problems discussed earlier, it'd be in our better interests to allow the usage of an external, intermediate system subject to what one's needs might be especially around the volume & scale of data being writen from an application into ClickHouse. + +Therefore, we intend to develop an abstraction that can enable an application to store data into ClickHouse regardless of the scale that they (currently) operate at. It also: + +- Facilitates an application to switch from one *technology* to another should their performance and/or scale requirements change over time. +- Allows for backend-specific conventions, configurations & best practices such as instrumentation, service-discovery, etc. to be encoded in one place for all applications to leverage consistently. + +## Design & Implementation + +### Core assumptions + +- We're only going to focus on writing data into ClickHouse as mentioned in aforementioned non-goals. With details of how our data lands into ClickHouse, this document does not (intentionally) address where this data comes from. Some of those details are delegated to the applications generating this data i.e as long as they can consume this abstraction, they should be able to write data into ClickHouse. + +- We're going to delegate the choice of different storage backends to a following blueprint or epic since that's outside the scope of this design. With ClickHouse as the eventual destination for our data, this document only talks about writing data into it - either directly or indirectly via a queueing/batching system. + +### Architecture + + + +Having an abstraction around writing data help client-side instrumentation to stay backend-agnostic allowing them to switch code paths depending on where it runs. + +An example setup should look like: + +```ruby +Gitlab::Database::Writer.config do |config| + # + # when using sync mode, data gets written directly into ClickHouse, + # therefore, it's also assumed the backend here is ClickHouse + config.mode = :sync OR :async + config.backend = :clickhouse # optional + # OR + # + # when using async mode, data is written to an intermediate system + # first, then written into ClickHouse asynchronously + config.mode = :async + config.backend = :pubsub OR :kafka OR :otherbackend + # + # then backend-specific configurations hereafter + # + config.url = 'tcp://user:pwd@localhost:9000/database' + # e.g. a serializer helps define how data travels over the wire + config.json_serializer = ClickHouse::Serializer::JsonSerializer + # ... +end +# do application-specific processing +# eventually, write data using the object you just built +Gitlab::Database::Writer.write( + Gitlab::Database::Model::MyTable, + [{ id: 1, foo: 'bar' }], +) +``` + +We intend to keep `Gitlab::Database::Writer.backend` to be as close to the backend-specific client implementation as possible. Having a wrapper around a vanilla client helps us address peripheral concerns such as service-discovery for the backends while still allowing the user to leverage features of a given client. + +### Iterations + +Considering the large scope of this undertaking and the need for feedback around actual usage, we intend to build the proposed abstraction(s) across multiple iterations which can be described as follows: + +#### Iteration 1 - Develop write abstraction with sync mode enabled + +First, research and develop a simple write abstraction that our users can begin to use to write data into ClickHouse. This ensures our choice of the underlying client is well-researched and suffices to fulfill needs of as many reported use-cases as possible. Being able to see this running would help gather user-feedback and improve the write APIs/interfaces accordingly. + +Given this feedback and more development with how we aim to deploy ClickHouse across our environments, it'd then be prudent to build into this abstraction necessary conventions, best practices and abstract away details around connection-pooling, service-discovery, etc. + +#### Iteration 2 - Add support for schemas & data validation + +In the next iteration, we plan to add support for schema usage and validation. This helps keep model definitions sane and allows for validating data to be inserted. + +#### Iteration 3 - Add support for async mode, PoC with one backend + +With the above two iterations well-executed, we can start to scale up our write abstractions adding the support for writing data into intermediate data stores before writing it into ClickHouse asynchronously. We aim to prototype such an implementation with atleast one such backend. + +#### Further iterations + +With a backend-agnostic abstraction becoming the ingestion interface a client interacts with, there's various other use-cases that can be solved from within this abstraction. Some of them are: + +- Zero-configuration data ingestion from multiple sources +- Dynamically enriching data from multiple sources +- Offloading data to long-term retention data stores + +### Possible backend implementations + +- Applications writing directly to ClickHouse + - Application-local in-memory queueing/batching of data + - Application-local persistent queueing/batching of data +- Non-local queueing/batching of data before eventually writing into ClickHouse + - Managed cloud backends: + - [Google PubSub](https://cloud.google.com/pubsub) + - [AWS Kinesis](https://aws.amazon.com/kinesis/) + - Self-managed backends: + - [CHProxy](https://www.chproxy.org/) + - [Kafka](https://kafka.apache.org/) + - [RedPanda](https://redpanda.com/) + - [Vector](https://vector.dev/) + - [RabbitMQ](https://www.rabbitmq.com/) + +### Additional complexity when using a non-local backend + +- The need for running an additional process/sub-system that reads data from the concerned backend and writes it into ClickHouse efficiently and reliably. +- The additional hop across the backend also means that there might be potential delays in how soon this data lands into ClickHouse. + +Though the points above describe additional complexity for an application, they can be treated as valid trade-off(s) assuming their need for data ingestion at scale. + +### Comparing backends across multiple dimensions + +| Dimension | CHProxy | Redis | Google PubSub | Apache Kafka | +|---|---|---|---|---| +| Operations | Trivial | Trivial | Managed | Non-trivial, complex | +| Data Retention | Non-durable | Non-durable | Durable | Durable | +| Performance | Good | Good | High | High | +| Data Streaming | None | Minimal | Good | Best | +| Suitable for self-managed environments | Trivial | Trivial | - | Complex | + +## References + +- [ClickHouse use-cases within Manage](https://gitlab.com/groups/gitlab-org/-/epics/7964) +- [List down all possible options for postgres to snowflake pipeline](https://gitlab.com/gitlab-data/gitlab.com-saas-data-pipeline/-/issues/13) +- [Design Spike for Snowplow For Data Event capture](https://gitlab.com/gitlab-data/analytics/-/issues/12397) +- [Audit Events Performance Limits](https://gitlab.com/gitlab-org/gitlab/-/issues/375545) diff --git a/doc/architecture/blueprints/clickhouse_read_abstraction_layer/index.md b/doc/architecture/blueprints/clickhouse_read_abstraction_layer/index.md new file mode 100644 index 00000000000..8290641b7a4 --- /dev/null +++ b/doc/architecture/blueprints/clickhouse_read_abstraction_layer/index.md @@ -0,0 +1,318 @@ +--- +status: proposed +creation-date: "2023-02-23" +authors: [ "@mikolaj_wawrzyniak", "@jdrpereira", "@pskorupa" ] +coach: "@DylanGriffith" +approvers: [ "@nhxnguyen" ] +owning-stage: "~workinggroup::clickhouse" +participating-stages: [] +--- + +# Consider an abstraction layer to interact with ClickHouse or alternatives + +## Table of Contents + +- [Summary](#summary) +- [Motivation](#motivation) +- [Goals](#goals) +- [Non-goals](#non-goals) +- [Possible solutions](#possible-solutions) + - [Recommended approach](#recommended-approach) + - [Overview of open source tools](#overview-of-open-source-tools) +- [Open Questions](#open-questions) + +## Summary + +Provide a solution standardizing read access to ClickHouse or its alternatives for GitLab installations that will not opt-in to install ClickHouse. After analyzing different [open-source tools](#overview-of-open-source-tools) and weighing them against an option to [build a solution internally](#recommended-approach). The current recommended approach proposes to use dedicated database-level drivers to connect to each data source. Additionally, it proposes the usage of [repository pattern](https://martinfowler.com/eaaCatalog/repository.html) to confine optionally database availability complexity to a single application layer. + +## Motivation + +ClickHouse requires significant resources to be run, and smaller installations of GitLab might not get a return from investment with provided performance improvement. That creates a risk that ClickHouse might not be globally available for all installations and features might need to alternate between different data stores available. Out of all [present & future ClickHouse use cases](https://gitlab.com/groups/gitlab-com/-/epics/2075) that have been already proposed as part of the working group 7 out of 10 uses data stores different than ClickHouse. Considering that context it is important to +support those use cases in their effort to adopt ClickHouse by providing them with tools and guidelines that will standardize interactions with available data stores. + +The proposed solution can take different forms from stand-alone tooling +offering a unified interface for interactions with underlying data stores, to a set of libraries supporting each of the data stored individually backed by implementation guidelines that will describe rules and limitations placed around data stores interactions, and drawing borders of encapsulation. + +## Goals + +- Limit the impact of optionally available data stores on the overall GitLab application codebase to [single abstraction layer](../../../development/reusing_abstractions.md#abstractions) +- Support all data store specific features +- Support communication for satellite services of the main GitLab application + +## Non-goals + +- This proposal does not directly consider write communication with database, as this is a subject of [complementary effort](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/111148) +- This proposal does not directly consider schema changes and data migration challenges + +Despite above points being non goals, it is acknowledge that they might impose some alterations to final solution which is expressed at the end of this document in the [Open questions](#open-questions) section. + +## Possible Solutions + +High-level goals described in the previous paragraph can be achieved by both in-house-built solutions as well as by adopting open-source tools. +The following sections will take a closer look into both of those avenues + +### Recommended approach + +In the spirit of MVC and iteration, it is proposed to start with a solution that would rely on drivers that directly interact +with corresponding data stores, like ActiveRecord for Ruby. For this solution to be able to achieve goals set for +this exit criteria and help mitigate the issue listed in the _Motivation_ section of this document, such drivers need to be supported +by a set of development guidelines enforced with static code analysis. + +Such a solution was selected as preferred upon receiving feedback from different members of the working group concerned +about the risk of limitations that might be imposed by open-source tools, preventing groups from taking advantage of ClickHouse +features to their fullest. Members collaborating around working group criteria presented in this document, agree that +concerns around limitations could be mitigated by building a comprehensive set of prototypes, however time and effort +required to achieve that surpass the limits of this working group. It is also important to notice that ClickHouse adoption +is in an exploratory stage, and groups might not being even able to state what are their requirements just yet. + +#### Proposed drivers + +Following ClickHouse documentation there are the following drivers for Ruby and Go + +##### Ruby + +1. [ClickHouse Ruby driver](https://github.com/shlima/click_house) - Previously selected for use in GitLab as part of the Observability grup's research (see: [issue](https://gitlab.com/gitlab-org/gitlab/-/issues/358158)) +1. [Clickhouse::Activerecord](https://github.com/PNixx/clickhouse-activerecord) + +##### Go + +1. [ClickHouse/clickhouse-go](https://github.com/ClickHouse/clickhouse-go) - Official SQL database client. +1. [uptrace/go-clickhouse](https://clickhouse.uptrace.dev/) - Alternative client. + +##### Proposed client architecture + +To keep the codebase well organized and limit coupling to any specific database engine it is important to encapsulate +interactions, including querying data to a single application layer, that would present its interface to layers above in +similar vain to [ActiveRecord interface propagation through abstraction layers](../../../development/reusing_abstractions.md) + +Keeping underlying database engines encapsulated makes the recommended solution a good two-way door decision that +keeps the opportunity to introduce other tools later on, while giving groups time to explore and understand their use cases. + +At the lowest abstraction layer, it can be expected that there will be a family of classes directly interacting with the ClickHouse driver, those classes +following MVC pattern implemented by Rails should be classified as _Models_. + +Models-level abstraction builds well into existing patterns and guidelines but unfortunately does not solve the challenge of the optional availability of the ClickHouse database engine for self-managed instances. It is required to design a dedicated entity that will house responsibility of selecting best database to serve business logic request. +From the already mentioned existing abstraction [guidelines](../../../development/reusing_abstractions.md) `Finders` seems to be the closest to the given requirements, due to the fact that `Finders` encapsulate database specific interaction behind their own public API, hiding database vendors detail from all layers above them. + +However, they are closely coupled to `ActiveRecord` ORM framework, and are bound by existing GitLab convention to return `ActiveRecord::Relation` objects, that might be used to compose even more complex queries. That coupling makes `Finders` unfit to deal with the optional availability of ClickHouse because returned data might come from two different databases, and might not be compatible with each other. + +With all that above in mind it might be worth considering adding a new entity into the codebase that would exist on a similar level of abstraction as `Finders` yet it would be required to return an `Array` of data objects instead. + +Required level of isolation can be achieved with usage of a [repository pattern](https://martinfowler.com/eaaCatalog/repository.html). The repository pattern is designed to separates business / domain logic from data access concerns, which is exactly what this proposal is looking for. +What is more the repository pattern does not limits operations performed on underlying databases allowing for full utilization of their features. + +To implement the repository pattern following things needs to be created: + +1. A **strategy** for each of supported databases, for example: `MyAwesomeFeature::Repository::Strategies::ClickHouseStrategy` and `MyAwesomeFeature::Repository::Strategies::PostgreSQLStrategy`. Strategies are responsible for implementing communication with underlying database ie: composing queries +1. A **repository** that is responsible for exposing high level interface to interact with database using one of available strategies selected with some predefined criteria ie: database availability. Strategies used by single repository must share the same public interface so they can be used interchangeable +1. A **Plain Old Ruby Object(PORO) Model** that represents data in business logic implemented by application layers using repository. It have to be database agnostic + +It is important to notice that the repository pattern based solution has already been implemented by Observability group (kudos to: @ahegyi, @splattael and @brodock). [`ErrorTracking::ErrorRepository`](https://gitlab.com/gitlab-org/gitlab/-/blob/1070c008b9e72626e25296480f82f2ee2b93f847/lib/gitlab/error_tracking/error_repository.rb) is being used to support migration of error tracking features from PostgreSQL to ClickHouse (integrated via API), and uses feature flag toggle as database selection criteria, that is great example of optional availability of database. + +`ErrorRepository` is using two strategies: + +1. [`OpenApiStrategy`](https://gitlab.com/gitlab-org/gitlab/-/blob/d0bdc8370ef17891fd718a4578e41fef97cf065d/lib/gitlab/error_tracking/error_repository/open_api_strategy.rb) to interact with ClickHouse using API proxy entity +1. [`ActiveRecordStrategy`](https://gitlab.com/gitlab-org/gitlab/-/blob/d0bdc8370ef17891fd718a4578e41fef97cf065d/lib/gitlab/error_tracking/error_repository/active_record_strategy.rb) to interact with PostgreSQL using `ActiveRecord` framework + +Each of those strategies return data back to abstraction layers above using following PORO Models: + +1. [`Gitlab::ErrorTracking::Error`](https://gitlab.com/gitlab-org/gitlab/-/blob/a8ea29d51ff23cd8f5b467de9063b64716c81879/lib/gitlab/error_tracking/error.rb) +1. [`Gitlab::ErrorTracking::DetailedError`](https://gitlab.com/gitlab-org/gitlab/-/blob/a8ea29d51ff23cd8f5b467de9063b64716c81879/lib/gitlab/error_tracking/detailed_error.rb) + +Additionally `ErrorRepository` is great example of remarkable flexibility offered by the repository pattern in terms of supported types of data stores, allowing to integrate solutions as different as a library and external service API under single unified interface. That example presents opportunity that the repository pattern in the future might be expanded beyond needs of ClickHouse and PostgreSQL when some use case would call for it. + +Following [merge request](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/85907/diffs) documents changes done by observability group in order to migrate from using current GitLab architecture based on ActiveRecord Models, Services and Finders to the repository pattern. + +##### Possible ways to enforce client architecture + +It is not enough to propose a client-side architecture for it to fully be established as common practice it needs +to be automatically enforced, reducing the risk of developers unconsciously going against it. There are multiple ways to +introduce automated verification of repository pattern implementation including: + +1. Utilize `ActiveRecord` query subscribers in a similar way to[Database::PreventCrossJoins](https://gitlab.com/gitlab-org/gitlab/-/blob/master/spec/support/database/prevent_cross_joins.rb) in order to detect queries to ClickHouse executed outside of _Strategies_ +1. Expanding [`CodeReuse`](https://gitlab.com/gitlab-org/gitlab/-/tree/master/rubocop/cop/code_reuse) rubocop rules to flag all usage of ClickHouse driver outside of _Strategies_ +1. Create rubocop rule that detects calls to utility method that checks the presence of ClickHouse instance (ie: `CurrentSettings.click_house_enabled?`) that are being made outside of _Repositories_ + +At this development stage, authors see all of the listed options as viable and promising, therefore a decision about which ones to use would be deferred to the moment when the first repository pattern implementation for ClickHouse will emerge. + +### Overview of open-source tools + +In this section authors provide an overview of existing 3rd party open-source solutions that were considered as alternative approaches to achieve stated goal, but was not selected as recommended approach. + +#### Evaluation criteria + +##### 1. License (MUST HAVE) + +1. Solutions must be open source under an [acceptable license](https://about.gitlab.com/handbook/engineering/open-source/#acceptable-licenses). + +##### 2. Support for different data stores (MUST HAVE) + +1. It focuses on the fact whether the proposed abstraction layer can support both ClickHouse and PostgreSQL (must have) +1. Additional consideration might be if more than the two must-have storages are supported +1. The solution must support the [minimum required versions](../../../install/requirements.md#postgresql-requirements) for PostgreSQL + +##### 3. Protocol compatibility + +Every abstraction layer comes at the cost of limited API compared to direct access to the tool. This exit criterion is trying to bring understanding to the degree of trade-off being made on limiting tools API for the sake of a common abstraction. + +1. List what read operations can be done via PostgreSQL and ClickHouse (`selects`, `joins`, `group by`, `order by`, `union` etc) +1. List what operations can be done with the proposed abstraction layer, how complicated it is to do such operations, and whether are there any performance concerns when compared to running operations natively +1. Does it still allow for direct access to a data source in case the required operation is not supported by the abstraction layer, eg: `ActiveRecord` allows for raw SQL strings to be run with `#execute` + +##### 4. Operational effort + +1. Deployment process: how complex is it? Is the proposed tool a library tool that is being added into the stack, or does it require additional services to be deployed independently along the GitLab system. What deployment types does the tool support (Kubernetes/VMs, SaaS/self-managed, supported OS, cloud providers). Does it support offline installation. +1. How many hardware resources does it need to operate +1. Does it require complex monitoring and operations to assure stable and performant services +1. Matured maintenance process and documentation around it: upgrades, backup and restore, scaling +1. High-availability support. Does the tool have documentation how to build HA cluster and perform failovers for self-managed? Does the tool support zero-downtime upgrade? +1. FIPS and FedRAMP compliance +1. Replication process and how the new tool would fit in GitLab Geo. + +##### 5. Developer experience + +1. Solutions must have well-structured, clear, and thoroughly documented APIs to ease adoption and reduce the learning curve. + +##### 6. Maturity (nice to have) + +1. How long does the solution exist? Is it used often? Does it have a stable community? If the license permits forking tool is also a considerable option + +##### 7. Tech fit + +1. Is the solution written in one of the programming languages we use at GitLab so that we can more easily contribute with bug fixes and new features? + +##### 8. Interoperability (Must have) + +1. Can the solution support both the main GitLab application written in Ruby on Rails also satellite services like container registry that might be written in Go + +#### Open - Source solutions + +##### 1. [Cube.dev](https://cube.dev/) + +**Evaluation** + +1. License + Apache 2.0 + MIT ✅ +1. Support for different data stores + Yes ✅ +1. Protocol compatibility + It uses OLAP theory concepts to aggregate data. This might be useful in some use cases like aggregating usage metrics, but not in others. It has APIs for both SQL queries and their own query format. +1. Operational effort + Separate service to be deployed using Docker or k8s. Uses Redis as a cache and data structure store. +1. Developer experience + Good [documentation](https://cube.dev/docs) +1. Maturity + Headless BI tools themselves are a fairly new idea, but Cube.js seems to be the leading open-source solution in this space. + The Analytics section uses it internally for our Product Analytics stack. +1. Tech fit + Uses REST and GraphQL APIs. It has its own query and data schema formats, but they are well-documented. Data definitions in either YAML or JavaScript. + +**Comment** + +The solution is already being used as a read interface for ClickHouse by ~"group::product analytics", +to gather first hand experience there was a conversation held with @mwoolf with key conclusions being: + +1. ClickHouse driver for cube.dev is community-sourced, and it does not have a maintainer as of now, which means there is no active development. It is a small and rather simple repository that should work at least until a new major version of ClickHouse will arrive with some breaking changes +1. Cube.dev is written in Type Script and JavaScript which are part of GitLab technical stack, and there are engineers here with expertise in them, however Cube.dev is expected to be mostly used by backend developers, which does not have that much experience in mentioned technologies +1. Abstraction layer for simple SQL works, based on JSON will build correct query depending on the backend +1. Data store-specific functions (like window funnel ClickHouse) are not being translated to other engines, which requires additional cube schemas to be built to represent the same data. +1. Performance so far was not an issue both on local dev and on AWS VPS millions of rows import load testing +1. It expose postgres SQL like interface for most engines, but not for ClickHouse unfortunately so for sake of working group use case JSON API might be more feasible +1. Cube.dev can automatically generate schemas on the fly, which can be used conditionally in the runtime handling optional components like ClickHouse + +There is also a [recording](https://youtu.be/iBPTCrvOBBs) of that conversation available. + +##### 2. [ClickHouse FDW](https://github.com/ildus/clickhouse_fdw) + +**Evaluation** + +A ClickHouse Foreign Data Wrapper for PostgreSQL. It allows ClickHouse tables to be queried as if they were stored in PostgreSQL. +Could be a viable option to easily introduce ClickHouse as a drop-in replacement when Postgres stops scaling. + +1. License + Apache 2.0 ✅ +1. Support for different data stores + Yes, by calling ClickHouse through a PostgreSQL instance. ✅ +1. Protocol compatibility + Supports SELECT, INSERT statements at a first glance. Not sure about joins. Allows for raw SQL by definition. +1. Operational effort + 1. A PostgreSQL extension. Requires some mapping between the two DBs. + 1. Might have adversary impact on PostgreSQL performance, when execution would wait for response from ClickHouse waisting CPU cycles on waiting + 1. Require exposing and managing connection between deployments of PostgreSQL and ClickHouse +1. Developer experience + TBD +1. Maturity + It's been around for a few years and is listed in ClickHouse docs, but doesn't seem to be widely used. +1. Tech fit + Raw SQL statements. + +**Comment** + +##### 3. [Clickhouse::Activerecord](https://github.com/PNixx/clickhouse-activerecord) + +**Evaluation** + +1. License + MIT License ✅ +1. Support for different data stores + Yes, in the sense that it provides a Clickhouse adapter for ActiveRecord in the application layer so that it can be used to query along PostgreSQL. ✅ +1. Protocol compatibility + Not sure about joins - no examples. +1. Operational effort + Ruby on Rails library tool - ORM interface in a form of an ActiveRecord adapter. +1. Developer experience + Easy to work with for developers familiar with Rails. +1. Maturity + Has been around for a few years, but repo activity is scarce (not a bad thing by itself, however). +1. Tech fit + Rails library, so yes. + +**Comment** + +##### 4. [Metriql](https://metriql.com/) + +**Evaluation** + +A headless BI solution using DBT to source data. Similar to Cube.dev in terms of defining metrics from data and transforming them with aggregations. +The authors explain the differences between Metriql and other BI tools like Cube.js in this FAQ entry. + +1. License + Apache 2.0 ✅ +1. Support for different data stores + Uses DBT to read from data sources, so CH and PostgreSQL are possible. +1. Protocol compatibility + It uses OLAP theory concepts to aggregate data. It does allow for impromptu SQL queries through a REST API. +1. Operational effort + It's a separate service to deploy and requires DBT. +1. Developer experience + I assume it requires DBT knowledge to set up and use. It has a fairly simple REST API documented here. +1. Maturity + First release May 2021, but repo activity is scarce (not a bad thing by itself). +1. Tech fit + Connects with BI tools through a REST API or JDBC Adapter. Allows querying using SQL or MQL (which is a SQL flavor/subset). + +**Comment** + +##### 5. Notable rejected 3rd party solutions + +ETL only solutions like Airflow and Meltano, as well as visualization tools like Tableau and Apache Superset, were excluded from the prospect list as they are usually clearly outside our criteria. + +**[pg2ch](https://github.com/mkabilov/pg2ch)** +PostgreSQL to ClickHouse mirroring using logical replication. +Repo archived; explicitly labeled not for production use. Logical replication might not be performant enough at our scale - we don't use it in our PostgreSQL DBs because of performance concerns. + +**Looker** +BI tooling. +Closed-source; proprietary. + +**[Hasura](https://github.com/hasura/graphql-engine)** +GraphQL interface for database sources. +No ClickHouse support yet. + +**[dbt Server](https://github.com/dbt-labs/dbt-server)** +HTTP API for dbt. MariaDB Business Source License (BSL) ❌ + +### Open questions + +1. This proposal main focus is read interface, however depending on outcome of [complementary effort](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/111148) that focus on write interface similar concerns around optional availability might be applicable to write interaction. In case if ingestion pipeline would not resolve optional availability challenges for write interface it might be considerable to include write interactions into repository pattern implementation proposed in this document. +1. Concerns around ClickHouse schema changes and data migrations is not covered by any existing working group criteria, even though solving this challenges as a whole is outside of the scope of this document it is prudent to raise awareness that some alterations to proposed repository pattern based implementation might be required in order to support schema changes. diff --git a/doc/architecture/blueprints/clickhouse_usage/index.md b/doc/architecture/blueprints/clickhouse_usage/index.md new file mode 100644 index 00000000000..8a5530313e5 --- /dev/null +++ b/doc/architecture/blueprints/clickhouse_usage/index.md @@ -0,0 +1,58 @@ +--- +status: proposed +creation-date: "2023-02-02" +authors: [ "@nhxnguyen" ] +coach: "@grzesiek" +approvers: [ "@dorrino", "@nhxnguyen" ] +owning-stage: "~devops::data_stores" +participating-stages: ["~section::ops", "~section::dev"] +--- + +<!-- vale gitlab.FutureTense = NO --> + +# ClickHouse Usage at GitLab + +## Summary + +[ClickHouse](https://clickhouse.com/) is an open-source column-oriented database management system. It can efficiently filter, aggregate, and sum across large numbers of rows. In FY23, GitLab selected ClickHouse as its standard data store for features with big data and insert-heavy requirements such as Observability and Analytics. This blueprint is a product of the [ClickHouse working group](https://about.gitlab.com/company/team/structure/working-groups/clickhouse-datastore/). It serves as a high-level blueprint to ClickHouse adoption at GitLab and references other blueprints addressing specific ClickHouse-related technical challenges. + +## Motivation + +In FY23-Q2, the Monitor:Observability team developed and shipped a [ClickHouse data platform](https://gitlab.com/groups/gitlab-org/-/epics/7772) to store and query data for Error Tracking and other observability features. Other teams have also begun to incorporate ClickHouse into their current or planned architectures. Given the growing interest in ClickHouse across product development teams, it is important to have a cohesive strategy for developing features using ClickHouse. This will allow teams to more efficiently leverage ClickHouse and ensure that we can maintain and support this functionality effectively for SaaS and self-managed customers. + +### Goals + +As ClickHouse has already been selected for use at GitLab, our main goal now is to ensure successful adoption of ClickHouse across GitLab. It is helpful to break down this goal according to the different phases of the product development workflow. + +1. Plan: Make it easy for development teams to understand if ClickHouse is the right fit for their feature. +1. Develop and Test: Give teams the best practices and frameworks to develop ClickHouse-backed features. +1. Launch: Support ClickHouse-backed features for SaaS and self-managed. +1. Improve: Successfully scale our usage of ClickHouse. + +### Non-Goals + +## Proposals + +The following are links to proposals in the form of blueprints that address technical challenges to using ClickHouse across a wide variety of features. + +1. Scalable data ingestion pipeline. + - How do we ingest large volumes of data from GitLab into ClickHouse either directly or by replicating existing data? +1. Supporting ClickHouse for self-managed installations. + - For which use-cases and scales does it make sense to run ClickHouse for self-managed and what are the associated costs? + - How can we best support self-managed installation of ClickHouse for different types/sizes of environments? + - Consider using the [Opstrace ClickHouse operator](https://gitlab.com/gitlab-org/opstrace/opstrace/-/tree/main/clickhouse-operator) as the basis for a canonical distribution. + - Consider exposing Clickhouse backend as [GitLab Plus](https://gitlab.com/groups/gitlab-org/-/epics/308) to combine benefits of using self-managed instance and GitLab-managed database. + - Should we develop abstractions for querying and data ingestion to avoid requiring ClickHouse for small-scale installations? +1. Abstraction layer for features to leverage both ClickHouse or PostreSQL. + - What are the benefits and tradeoffs? For example, how would this impact our automated migration and query testing? +1. Security recommendations and secure defaults for ClickHouse usage. + +Note that we are still formulating proposals and will update the blueprint accordingly. + +## Best Practices + +Best practices and guidelines for developing performant and scalable features using ClickHouse are located in the [ClickHouse developer documentation](../../../development/database/clickhouse/index.md). + +## Cost and maintenance analysis + +ClickHouse components cost and maintenance analysis is located in the [ClickHouse Self-Managed component costs and maintenance requirements](self_managed_costs_and_requirements/index.md). diff --git a/doc/architecture/blueprints/clickhouse_usage/self_managed_costs_and_requirements/index.md b/doc/architecture/blueprints/clickhouse_usage/self_managed_costs_and_requirements/index.md new file mode 100644 index 00000000000..d8c9c0b25d5 --- /dev/null +++ b/doc/architecture/blueprints/clickhouse_usage/self_managed_costs_and_requirements/index.md @@ -0,0 +1,65 @@ +--- +status: proposed +creation-date: "2023-04-04" +authors: [ "@niskhakova", "@dmakovey" ] +coach: "@grzesiek" +approvers: [ "@dorrino", "@nhxnguyen" ] +owning-stage: "~workinggroup::clickhouse" +participating-stages: ["~section::enablement"] +--- + +# ClickHouse Self-Managed component costs and maintenance requirements + +## Summary + +[ClickHouse](https://clickhouse.com/) requires additional cost and maintenance for self-managed customers: + +- **Resource allocation cost**: ClickHouse requires a considerable amount of resources to run optimally. + - [Minimum cost estimation](#minimum-self-managed-component-costs) shows that setting up ClickHouse can be applicable only for very large Reference Architectures: 25k and up. +- **High availability**: ClickHouse SaaS supports HA. No documented HA configuration for self-managed at the moment. +- **Geo setups**: Sync and replication complexity for GitLab Geo setups. +- **Upgrades**: An additional database to maintain and upgrade along with existing Postgres database. This also includes compatibility issues of mapping GitLab version to ClickHouse version and keeping them up-to-date. +- **Backup and restore:** Self-managed customers need to have an engineer who is familiar with backup strategies and disaster recovery process in ClickHouse or switch to ClickHouse SaaS. +- **Monitoring**: ClickHouse can use Prometheus, additional component to monitor and troubleshoot. +- **Limitations**: Azure object storage is not supported. GitLab does not have the documentation or support expertise to assist customers with deployment and operation of self-managed ClickHouse. +- **ClickHouse SaaS**: Customers using a self-managed GitLab instance with regulatory or compliance requirements, or latency concerns likely cannot use ClickHouse SaaS. + +### Minimum self-managed component costs + +Based on [ClickHouse spec requirements](https://gitlab.com/gitlab-com/www-gitlab-com/-/issues/14384#note_1307456092) analysis +and collaborating with ClickHouse team, we identified the following minimal configurations for ClickHouse self-managed: + +1. ClickHouse High Availability (HA) + - ClickHouse - 2 machines with >=16-cores, >=64 GB RAM, SSD, 10 GB Internet. Each machine also runs Keeper. + - [Keeper](https://clickhouse.com/docs/en/guides/sre/keeper/clickhouse-keeper) - 1 machine with 2 CPU, 4 GB of RAM, SSD with high IOPS +1. ClickHouse non-HA + - ClickHouse - 1 machine with >=16-cores, >=64 GB RAM, SSD, 10 GB Internet. + +The following [cost table](https://gitlab.com/gitlab-com/www-gitlab-com/-/issues/14384#note_1324085466) was compiled using the machine CPU and memory requirements for ClickHouse, and comparing them to the +GitLab Reference Architecture sizes and [costs](../../../../administration/reference_architectures/index.md#cost-to-run) from the GCP calculator. + +| Reference Architecture | ClickHouse type | ClickHouse cost / (GitLab cost + ClickHouse cost) | +|-------------|-----------------|-----------------------------------| +| [1k - non HA](https://cloud.google.com/products/calculator#id=a6d6a94a-c7dc-4c22-85c4-7c5747f272ed) | [non-HA](https://cloud.google.com/products/calculator#id=9af5359e-b155-451c-b090-5f0879bb591e) | 78.01% | +| [2k - non HA](https://cloud.google.com/products/calculator#id=0d3aff1f-ea3d-43f9-aa59-df49d27c35ca) | [non-HA](https://cloud.google.com/products/calculator#id=9af5359e-b155-451c-b090-5f0879bb591e) | 44.50% | +| [3k - HA](https://cloud.google.com/products/calculator/#id=15fc2bd9-5b1c-479d-bc46-d5ce096b8107) | [HA](https://cloud.google.com/products/calculator#id=9909f5af-d41a-4da2-b8cc-a0347702a823) | 37.87% | +| [5k - HA](https://cloud.google.com/products/calculator/#id=9a798136-53f2-4c35-be43-8e1e975a6663) | [HA](https://cloud.google.com/products/calculator#id=9909f5af-d41a-4da2-b8cc-a0347702a823) | 30.92% | +| [10k - HA](https://cloud.google.com/products/calculator#id=cbe61840-31a1-487f-88fa-631251c2fde5) | [HA](https://cloud.google.com/products/calculator#id=9909f5af-d41a-4da2-b8cc-a0347702a823) | 20.47% | +| [25k - HA](https://cloud.google.com/products/calculator#id=b4b8b587-508a-4433-adc8-dc506bbe924f) | [HA](https://cloud.google.com/products/calculator#id=9909f5af-d41a-4da2-b8cc-a0347702a823) | 14.30% | +| [50k - HA](https://cloud.google.com/products/calculator/#id=48b4d817-d6cd-44b8-b069-0ba9a5d123ea) | [HA](https://cloud.google.com/products/calculator#id=9909f5af-d41a-4da2-b8cc-a0347702a823) | 8.16% | + +NOTE: +The ClickHouse Self-Managed component evaluation is the minimum estimation for the costs +with a simplified architecture. + +The following components increase the cost, and were not considered in the minimum calculation: + +- Disk size - depends on data size, hard to estimate. +- Disk types - ClickHouse recommends [fast SSDs](https://clickhouse.com/docs/ru/operations/tips#storage-subsystem). +- Network usage - ClickHouse recommends using [10 GB network, if possible](https://clickhouse.com/docs/en/operations/tips#network). +- For HA we sum minimum cost across all reference architectures from 3k to 50k users, but HA specs tend to increase with user count. + +### Resources + +- [Research and understand component costs and maintenance requirements of running a ClickHouse instance with GitLab](https://gitlab.com/gitlab-com/www-gitlab-com/-/issues/14384) +- [ClickHouse for Error Tracking on GitLab.com](https://gitlab.com/gitlab-com/gl-infra/readiness/-/blob/master/library/database/clickhouse/index.md) diff --git a/doc/architecture/blueprints/search/code_search_with_zoekt.md b/doc/architecture/blueprints/code_search_with_zoekt/index.md index d0d347f1ff4..db608b763b8 100644 --- a/doc/architecture/blueprints/search/code_search_with_zoekt.md +++ b/doc/architecture/blueprints/code_search_with_zoekt/index.md @@ -8,6 +8,8 @@ owning-stage: "~devops::enablement" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # Use Zoekt For code search ## Summary @@ -57,7 +59,7 @@ customers that wish to participate in the trial. The main goals of this integration will be to implement the following highly requested improvements to code search: -1. [Exact match (substring match) code searches in Advanced Search](https://gitlab.com/gitlab-org/gitlab/-/issues/325234) +1. [Exact match (substring match) code searches in advanced search](https://gitlab.com/gitlab-org/gitlab/-/issues/325234) 1. [Support regular expressions with Advanced Global Search](https://gitlab.com/gitlab-org/gitlab/-/issues/4175) 1. [Support multiple line matches in the same file](https://gitlab.com/gitlab-org/gitlab/-/issues/668) diff --git a/doc/architecture/blueprints/composable_codebase_using_rails_engines/index.md b/doc/architecture/blueprints/composable_codebase_using_rails_engines/index.md index 7fecbd1de71..5b82716cb21 100644 --- a/doc/architecture/blueprints/composable_codebase_using_rails_engines/index.md +++ b/doc/architecture/blueprints/composable_codebase_using_rails_engines/index.md @@ -8,6 +8,8 @@ owning-stage: "~devops::non_devops" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # Composable GitLab Codebase NOTE: @@ -340,7 +342,7 @@ What was done? spec.add_dependency 'graphql-docs' spec.add_dependency 'grape' end - ``` + ``` 1. Move routes to the `engines/web_engine/config/routes.rb` file @@ -380,59 +382,59 @@ What was done? 1. Configure GitLab when to load the engine. - In GitLab `config/engines.rb`, we can configure when do we want to load our engines by relying on our `Gitlab::Runtime` + In GitLab `config/engines.rb`, we can configure when do we want to load our engines by relying on our `Gitlab::Runtime` - ```ruby - # config/engines.rb - # Load only in case we are running web_server or rails console - if Gitlab::Runtime.puma? || Gitlab::Runtime.console? - require 'web_engine' - end - ``` + ```ruby + # config/engines.rb + # Load only in case we are running web_server or rails console + if Gitlab::Runtime.puma? || Gitlab::Runtime.console? + require 'web_engine' + end + ``` 1. Configure Engine - Our Engine inherits from the `Rails::Engine` class. This way this gem notifies Rails that - there's an engine at the specified path so it will correctly mount the engine inside - the application, performing tasks such as adding the app directory of the engine to - the load path for models, mailers, controllers, and views. - A file at `lib/web_engine/engine.rb`, is identical in function to a standard Rails - application's `config/application.rb` file. This way engines can access a configuration - object which contains configuration shared by all railties and the application. - Additionally, each engine can access `autoload_paths`, `eager_load_paths`, and `autoload_once_paths` - settings which are scoped to that engine. - - ```ruby - module WebEngine - class Engine < ::Rails::Engine - config.eager_load_paths.push(*%W[#{config.root}/lib - #{config.root}/app/graphql/resolvers/concerns - #{config.root}/app/graphql/mutations/concerns - #{config.root}/app/graphql/types/concerns]) - - if Gitlab.ee? - ee_paths = config.eager_load_paths.each_with_object([]) do |path, memo| - ee_path = config.root - .join('ee', Pathname.new(path).relative_path_from(config.root)) - memo << ee_path.to_s - end - # Eager load should load CE first - config.eager_load_paths.push(*ee_paths) - end - end - end - ``` + Our Engine inherits from the `Rails::Engine` class. This way this gem notifies Rails that + there's an engine at the specified path so it will correctly mount the engine inside + the application, performing tasks such as adding the app directory of the engine to + the load path for models, mailers, controllers, and views. + A file at `lib/web_engine/engine.rb`, is identical in function to a standard Rails + application's `config/application.rb` file. This way engines can access a configuration + object which contains configuration shared by all railties and the application. + Additionally, each engine can access `autoload_paths`, `eager_load_paths`, and `autoload_once_paths` + settings which are scoped to that engine. + + ```ruby + module WebEngine + class Engine < ::Rails::Engine + config.eager_load_paths.push(*%W[#{config.root}/lib + #{config.root}/app/graphql/resolvers/concerns + #{config.root}/app/graphql/mutations/concerns + #{config.root}/app/graphql/types/concerns]) + + if Gitlab.ee? + ee_paths = config.eager_load_paths.each_with_object([]) do |path, memo| + ee_path = config.root + .join('ee', Pathname.new(path).relative_path_from(config.root)) + memo << ee_path.to_s + end + # Eager load should load CE first + config.eager_load_paths.push(*ee_paths) + end + end + end + ``` 1. Testing - We adapted CI to test `engines/web_engine/` as a self-sufficient component of stack. + We adapted CI to test `engines/web_engine/` as a self-sufficient component of stack. - - We moved `spec` as-is files to the `engines/web_engine/spec` folder - - We moved `ee/spec` as-is files to the `engines/web_engine/ee/spec` folder - - We control specs from main application using environment variable `TEST_WEB_ENGINE` - - We added new CI job that will run `engines/web_engine/spec` tests separately using `TEST_WEB_ENGINE` environment variable. - - We added new CI job that will run `engines/web_engine/ee/spec` tests separately using `TEST_WEB_ENGINE` environment variable. - - We are running all white box frontend tests with `TEST_WEB_ENGINE=true` + - We moved `spec` as-is files to the `engines/web_engine/spec` folder + - We moved `ee/spec` as-is files to the `engines/web_engine/ee/spec` folder + - We control specs from main application using environment variable `TEST_WEB_ENGINE` + - We added new CI job that will run `engines/web_engine/spec` tests separately using `TEST_WEB_ENGINE` environment variable. + - We added new CI job that will run `engines/web_engine/ee/spec` tests separately using `TEST_WEB_ENGINE` environment variable. + - We are running all white box frontend tests with `TEST_WEB_ENGINE=true` #### Results diff --git a/doc/architecture/blueprints/consolidating_groups_and_projects/index.md b/doc/architecture/blueprints/consolidating_groups_and_projects/index.md index 97853075607..f5bd53627cb 100644 --- a/doc/architecture/blueprints/consolidating_groups_and_projects/index.md +++ b/doc/architecture/blueprints/consolidating_groups_and_projects/index.md @@ -4,16 +4,18 @@ creation-date: "2021-02-07" authors: [ "@alexpooley", "@ifarkas" ] coach: "@grzesiek" approvers: [ "@m_gill", "@mushakov" ] -owning-stage: "~devops::plan" +author-stage: "~devops::plan" +owning-stage: "~devops::data_stores" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # Consolidating Groups and Projects -There are numerous features that exist exclusively within groups or -projects. The boundary between group and project features used to be clear. -However, there is growing demand to have group features within projects, and -project features within groups. For example, having issues in groups, and epics +Numerous features exist exclusively within groups or projects. The boundary between group and project features used to be clear. +However, there is growing demand to have group features in projects, and +project features in groups. For example, having issues in groups, and epics in projects. The [Simplify Groups & Projects Working Group](https://about.gitlab.com/company/team/structure/working-groups/simplify-groups-and-projects/) @@ -31,12 +33,12 @@ no established process in place. This results in the reimplementation of the same feature. Those implementations diverge from each other over time as they all live on their own. A few more problems with this approach: -- Features are coupled to their container. In practice it is not straight +- Features are coupled to their container. In practice, it is not straight forward to decouple a feature from its container. The degree of coupling varies across features. - Naive duplication of features will result in a more complex and fragile codebase. - Generalizing solutions across groups and projects may degrade system performance. -- The range of features span across many teams, and these changes will need to +- The range of features spans across many teams, and these changes will need to manage development interference. - The group/project hierarchy creates a natural feature hierarchy. When features exist across containers the feature hierarchy becomes ambiguous. @@ -48,33 +50,33 @@ remains consistent. ### Performance -Resources can only be queried in elaborate / complicated ways. This caused +Resources can only be queried in elaborate/complicated ways. This caused performance issues with authorization, epics, and many other places. As an example, to query the projects a user has access to, the following sources need to be considered: -- personal projects -- direct group membership -- direct project membership -- inherited group membership -- inherited project membership -- group sharing -- inherited membership via group sharing -- project sharing +- Personal projects +- Direct group membership +- Direct project membership +- Inherited group membership +- Inherited project membership +- Group sharing +- Inherited membership via group sharing +- Project sharing -Group / project membership, group / project sharing are also examples of +Group/project membership, group/project sharing are also examples of duplicated features. ## Goals -For now this blueprint strictly relates to the engineering challenges. +For now, this blueprint strictly relates to the engineering challenges. - Consolidate the group and project container architecture. - Develop a set of solutions to decouple features from their container. - Decouple engineering changes from product changes. - Develop a strategy to make architectural changes without adversely affecting other teams. -- Provide a solution for requests asking for features availability of other levels. +- Provide a solution for requests asking for features to be made available at other levels. ## Proposal @@ -102,9 +104,9 @@ New features should be implemented on `Namespace`. Similarly, when a feature need to be reimplemented on a different level, moving it to `Namespace` essentially makes it available on all levels: -- personal namespaces -- groups -- projects +- Personal namespaces +- Groups +- Projects Various traversal queries are already available on `Namespaces` to query the group hierarchy. `Projects` represent the leaf nodes in the hierarchy, but with @@ -113,14 +115,14 @@ retrieve projects as well. This also enables further simplification of some of our core features: -- routes should be generated based on the `Namespace` hierarchy, instead of - mixing project with the group hierarchy. -- there is no need to differentiate between `GroupMembers` and `ProjectMembers`. +- Routes should be generated based on the `Namespace` hierarchy, instead of + mixing the project with the group hierarchy. +- There is no need to differentiate between `GroupMembers` and `ProjectMembers`. All `Members` should be related to a `Namespace`. This can lead to simplified querying, and potentially deduplicating policies. -As more and more features will be migrated to `Namespace`, the role of `Project` -model will diminish over time to essentially a container around repository +As more and more features will be migrated to `Namespace`, the role of the `Project` +model will diminish over time to essentially a container around the repository related functionality. ## Iterations @@ -129,9 +131,103 @@ The work required to establish `Namespace` as a container for our features is tracked under [Consolidate Groups and Projects](https://gitlab.com/groups/gitlab-org/-/epics/6473) epic. +### Phase 1 (complete) + +- [Phase 1 epic](https://gitlab.com/groups/gitlab-org/-/epics/6697). +- **Goals**: + 1. Ensure every project receives a corresponding record in the `namespaces` + table with `type='Project'`. + 1. For user namespaces, the type changes from `NULL` to `User`. + +We should make sure that projects, and the project namespace, are equivalent: + +- **Create project:** Use Rails callbacks to ensure a new project namespace is + created for each project. Project namespace records should contain `created_at` and + `updated_at` attributes equal to the project's `created_at`/`updated_at` attributes. +- **Update project:** Use the `after_save` callback in Rails to ensure some + attributes are kept in sync between project and project namespaces. + Read [`project#after_save`](https://gitlab.com/gitlab-org/gitlab/blob/6d26634e864d7b748dda0e283eb2477362263bc3/app/models/project.rb#L101-L101) + for more information. +- **Delete project:** Use FKs cascade delete or Rails callbacks to ensure when a `Project` + or its `ProjectNamespace` is removed, its corresponding `ProjectNamespace` or `Project` + is also removed. +- **Transfer project to a different group:** Make sure that when a project is transferred, + its corresponding project namespace is transferred to the same group. +- **Transfer group:** Make sure when transferring a group that all of its sub-projects, + either direct or through descendant groups, have their corresponding project + namespaces transferred correctly as well. +- **Export or import project** + - **Export project** continues to export only the project, and not its project namespace, + in this phase. The project namespace does not contain any specific information + to export at this point. Eventually, we want the project namespace to be exported as well. + - **Import project** creates a new project, so the project namespace is created through + Rails `after_save` callback on the project model. +- **Export or import group:** When importing or exporting a `Group`, projects are not + included in the operation. If that feature is changed to include `Project` when its group is + imported or exported, the logic must include their corresponding project namespaces + in the import or export. + +After ensuring these points, run a database migration to create a `ProjectNamespace` +record for every `Project`. Project namespace records created during the migration +should have `created_at` and `updated_at` attributes set to the migration runtime. +The project namespaces' `created_at` and `updated_at` attributes would not match +their corresponding project's `created_at` and `updated_at` attributes. We want +the different dates to help audit any of the created project namespaces, in case we need it. +After this work completes, we must migrate data as described in +[Backfill `ProjectNamespace` for every Project](https://gitlab.com/gitlab-org/gitlab/-/issues/337100). + +### Phase 2 (complete) + +- [Phase 2 epic](https://gitlab.com/groups/gitlab-org/-/epics/6768). +- **Goal**: Link `ProjectNamespace` to other entities on the database level. + +In this phase: + +- Communicate the changes company-wide at the engineering level. We want to make + engineers aware of the upcoming changes, even though teams are not expected to + collaborate actively until phase 3. +- Raise awareness to avoid regressions and conflicting or duplicate work that + can be dealt with before phase 3. + +### Phase 3 (ongoing) + +- [Phase 3 epic](https://gitlab.com/groups/gitlab-org/-/epics/6585). + +In this phase we are migrating basic, high-priority project functionality from `Project` to `ProjectNamespace`, or directly to `Namespace`. Problems to solve as part of this phase: + +- [Unify members/members actions](https://gitlab.com/groups/gitlab-org/-/epics/8010) - on UI and API level. +- Starring: Right now only projects can be starred. We want to bring this to the group level. +- Common actions: Destroying, transferring, restoring. This can be unified on the controller level and then propagated lower. +- Archiving currently only works on the project level. This can be brought to the group level, similar to the mechanism for “pending deletion”. +- Avatar's serving and actions. + +### Phase 4 + +- [Phase 4 epic](https://gitlab.com/groups/gitlab-org/-/epics/8687) + +In this phase we are migrating additional functionality from `Project` to `ProjectNamespace`/`Namespace`: + +- Replace usages of `Project` with `ProjectNamespace` in the code. +- API changes to expose namespaces and namespace features. + - Investigate if we extend API for `groups` or we introduce a `namespaces` endpoint and slowly deprecate `groups` and `projects` endpoints. +- Break down each feature that needs to be migrated from `Project` to `ProjectNamespace` or `Namespace`. + - Investigate if we can move a feature from `Project -> Namespace` directly vs `Project -> ProjectNamespace -> Namespace`. This can be decided on a feature by feature case. +- [Migrate Project#namespace to reference ProjectNamespace](https://gitlab.com/groups/gitlab-org/-/epics/6581). +- [Routes consolidation between Project & ProjectNamespace](https://gitlab.com/gitlab-org/gitlab/-/issues/337103). +- [Policies consolidation](https://gitlab.com/groups/gitlab-org/-/epics/6689). + +### Phase 5 + +- [Phase 5 epic](https://gitlab.com/groups/gitlab-org/-/epics/6944) + +We should strive to do the code clean up as we move through the phases. However, not everything can be cleaned up while something is still being developed. For example, dropping database columns can be done as the last task when we are sure everything is working. This phase will focus on: + +- Code cleanup +- Database cleanup + ## Migrating features to Namespaces -The initial iteration will provide a framework to house features under `Namespaces`. Stage groups will eventually need to migrate their own features and functionality over to `Namespaces`. This may impact these features in unexpected ways. Therefore, to minimize UX debt and maintain product consistency, stage groups will have to consider a number of factors when migrating their features over to `Namespaces`: +The initial iteration will provide a framework to house features under `Namespaces`. Stage groups will eventually need to migrate their own features and functionality over to `Namespaces`. This may impact these features in unexpected ways. Therefore, to minimize UX debt and maintain product consistency, stage groups will have to consider several factors when migrating their features over to `Namespaces`: 1. **Conceptual model**: What are the current and future state conceptual models of these features ([see object modeling for designers](https://hpadkisson.medium.com/object-modeling-for-designers-an-introduction-7871bdcf8baf))? These should be documented in Pajamas (example: [merge requests](https://design.gitlab.com/objects/merge-request/)). 1. **Merge conflicts**: What inconsistencies are there across project, group, and administrator levels? How might these be addressed? For an example of how we rationalized this for labels, please see [this issue](https://gitlab.com/gitlab-org/gitlab/-/issues/338820). @@ -147,4 +243,5 @@ The initial iteration will provide a framework to house features under `Namespac ## Related topics -- [Workspace developer documentation](../../../development/workspace/index.md) +- [Organization developer documentation](../../../development/organization/index.md) +- [Organization user documentation](../../../user/organization/index.md) diff --git a/doc/architecture/blueprints/container_registry_metadata_database/index.md b/doc/architecture/blueprints/container_registry_metadata_database/index.md index f3bcf1e4e59..b77aaf598e6 100644 --- a/doc/architecture/blueprints/container_registry_metadata_database/index.md +++ b/doc/architecture/blueprints/container_registry_metadata_database/index.md @@ -8,6 +8,8 @@ owning-stage: "~devops::package" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # Container Registry Metadata Database ## Usage of the GitLab Container Registry diff --git a/doc/architecture/blueprints/database/scalability/patterns/index.md b/doc/architecture/blueprints/database/scalability/patterns/index.md index ec00d757377..d28734ce511 100644 --- a/doc/architecture/blueprints/database/scalability/patterns/index.md +++ b/doc/architecture/blueprints/database/scalability/patterns/index.md @@ -2,7 +2,6 @@ stage: Data Stores group: Database info: To determine the technical writer assigned to the Stage/Group associated with this page, see https://about.gitlab.com/handbook/product/ux/technical-writing/#assignments -comments: false description: 'Learn how to scale the database through the use of best-of-class database scalability patterns' --- diff --git a/doc/architecture/blueprints/database/scalability/patterns/read_mostly.md b/doc/architecture/blueprints/database/scalability/patterns/read_mostly.md index ec236c9bfe3..3a3fd2f33c2 100644 --- a/doc/architecture/blueprints/database/scalability/patterns/read_mostly.md +++ b/doc/architecture/blueprints/database/scalability/patterns/read_mostly.md @@ -2,7 +2,6 @@ stage: Data Stores group: Database info: To determine the technical writer assigned to the Stage/Group associated with this page, see https://about.gitlab.com/handbook/product/ux/technical-writing/#assignments -comments: false description: 'Learn how to scale operating on read-mostly data at scale' --- diff --git a/doc/architecture/blueprints/database/scalability/patterns/time_decay.md b/doc/architecture/blueprints/database/scalability/patterns/time_decay.md index 2b36a43a6db..24fc3f45717 100644 --- a/doc/architecture/blueprints/database/scalability/patterns/time_decay.md +++ b/doc/architecture/blueprints/database/scalability/patterns/time_decay.md @@ -2,7 +2,6 @@ stage: Data Stores group: Database info: To determine the technical writer assigned to the Stage/Group associated with this page, see https://about.gitlab.com/handbook/product/ux/technical-writing/#assignments -comments: false description: 'Learn how to operate on large time-decay data' --- diff --git a/doc/architecture/blueprints/database_scaling/size-limits.md b/doc/architecture/blueprints/database_scaling/size-limits.md index e530bd6eff0..b6b9cda8827 100644 --- a/doc/architecture/blueprints/database_scaling/size-limits.md +++ b/doc/architecture/blueprints/database_scaling/size-limits.md @@ -1,7 +1,6 @@ --- stage: Data Stores group: Database -comments: false description: 'Database Scalability / Limit table sizes' --- diff --git a/doc/architecture/blueprints/database_testing/index.md b/doc/architecture/blueprints/database_testing/index.md index fe6dcf1723d..79560dd3959 100644 --- a/doc/architecture/blueprints/database_testing/index.md +++ b/doc/architecture/blueprints/database_testing/index.md @@ -1,5 +1,5 @@ --- -status: accepted +status: implemented creation-date: "2021-02-08" authors: [ "@abrandl" ] coach: "@glopezfernandez" @@ -8,8 +8,15 @@ owning-stage: "~devops::data_stores" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # Database Testing +**Notice:** This blueprint has been partially implemented. We still plan to +iterate on the tooling. The content below is a historical version of the +blueprint, written prior to incorporating database testing into our development +workflow. + We have identified [common themes of reverted migrations](https://gitlab.com/gitlab-org/gitlab/-/issues/233391) and discovered failed migrations breaking in both production and staging even when successfully tested in a developer environment. We have also experienced production incidents even with successful testing in staging. These failures are quite expensive: they can have a significant effect on availability, block deployments, and generate incident escalations. These escalations must be triaged and either reverted or fixed forward. Often, this can take place without the original author's involvement due to time zones and/or the criticality of the escalation. With our increased deployment speeds and stricter uptime requirements, the need for improving database testing is critical, particularly earlier in the development process (shift left). From a developer's perspective, it is hard, if not unfeasible, to validate a migration on a large enough dataset before it goes into production. @@ -86,13 +93,13 @@ The short-term focus is on testing regular migrations (typically schema changes) In order to secure this process and meet compliance goals, the runner environment is treated as a *production* environment and similarly locked down, monitored and audited. Only Database Maintainers have access to the CI pipeline and its job output. Everyone else can only see the results and statistics posted back on the merge request. -We implement a secured CI pipeline on <https://ops.gitlab.net> that adds the execution steps outlined above. The goal is to secure this pipeline to solve the following problem: +We implement a secured CI pipeline on [Internal GitLab for Operations](https://ops.gitlab.net/users/sign_in) that adds the execution steps outlined above. The goal is to secure this pipeline to solve the following problem: Make sure we strongly protect production data, even though we allow everyone (GitLab team/developers) to execute arbitrary code on the thin-clone which contains production data. This is in principle achieved by locking down the GitLab Runner instance executing the code and its containers on a network level, such that no data can escape over the network. We make sure no communication can happen to the outside world from within the container executing the GitLab Rails code (and its database migrations). -Furthermore, we limit the ability to view the results of the jobs (including the output printed from code) to Maintainer and Owner level on the <https://ops.gitlab.net> pipeline and provide only a high level summary back to the original MR. If there are issues or errors in one of the jobs run, the database Maintainer assigned to review the MR can check the original job for more details. +Furthermore, we limit the ability to view the results of the jobs (including the output printed from code) to Maintainer and Owner level on the [Internal GitLab for Operations](https://ops.gitlab.net/users/sign_in) pipeline and provide only a high level summary back to the original MR. If there are issues or errors in one of the jobs run, the database Maintainer assigned to review the MR can check the original job for more details. With this step implemented, we already have the ability to execute database migrations on the thin-cloned GitLab.com database automatically from GitLab CI and provide feedback back to the merge request and the developer. The content of that feedback is expected to evolve over time and we can continuously add to this. diff --git a/doc/architecture/blueprints/gitlab_agent_deployments/index.md b/doc/architecture/blueprints/gitlab_agent_deployments/index.md index 96e361d7531..d8d26389d7d 100644 --- a/doc/architecture/blueprints/gitlab_agent_deployments/index.md +++ b/doc/architecture/blueprints/gitlab_agent_deployments/index.md @@ -8,6 +8,8 @@ owning-stage: "~devops::release" participating-stages: [Configure, Release] --- +<!-- vale gitlab.FutureTense = NO --> + # View and manage resources deployed by GitLab Agent For Kuberenetes ## Summary @@ -374,6 +376,8 @@ Here is an example of GraphQL query: lastDeployment(status: SUCCESS) { agent { id + name + project kubernetesNamespace } } diff --git a/doc/architecture/blueprints/gitlab_ci_events/index.md b/doc/architecture/blueprints/gitlab_ci_events/index.md new file mode 100644 index 00000000000..7ce8fea9410 --- /dev/null +++ b/doc/architecture/blueprints/gitlab_ci_events/index.md @@ -0,0 +1,63 @@ +--- +status: proposed +creation-date: "2023-03-15" +authors: [ "@furkanayhan" ] +coach: "@grzesiek" +approvers: [ "@jreporter", "@cheryl.li" ] +owning-stage: "~devops::verify" +participating-stages: [ "~devops::package", "~devops::deploy" ] +--- + +# GitLab CI Events + +## Summary + +In order to unlock innovation and build more value, GitLab is expected to be +the center of automation related to DevSecOps processes. We want to transform +GitLab into a programming environment, that will make it possible for engineers +to model various workflows on top of CI/CD pipelines. Today, users must create +custom automation around webhooks or scheduled pipelines to build required +workflows. + +In order to make this automation easier for our users, we want to build a +powerful CI/CD eventing system, that will make it possible to run pipelines +whenever something happens inside or outside of GitLab. + +A typical use-case is to run a CI/CD job whenever someone creates an issue, +posts a comment, changes a merge request status from "draft" to "ready for +review" or adds a new member to a group. + +To build that new technology, we should: + +1. Emit many hierarchical events from within GitLab in a more advanced way than we do it today. +1. Make it affordable to run this automation, that will react to GitLab events, at scale. +1. Provide a set of conventions and libraries to make writing the automation easier. + +## Goals + +While ["GitLab Events Platform"](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/113700) +aims to build new abstractions around emitting events in GitLab, "GitLab CI +Events" blueprint is about making it possible to: + +1. Define a way in which users will configure when an event emitted will result in a CI pipeline being run. +1. Describe technology required to match subscriptions with events at GitLab.com scale and beyond. +1. Describe technology we could use to reduce the cost of running automation jobs significantly. + +## Proposals + +For now, we have technical 4 proposals; + +1. [Proposal 1: Using the `.gitlab-ci.yml` file](proposal-1-using-the-gitlab-ci-file.md) + Based on; + - [GitLab CI Workflows PoC](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/91244) + - [PoC NPM CI events](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/111693) +1. [Proposal 2: Using the `rules` keyword](proposal-2-using-the-rules-keyword.md) + Highly inefficient way. +1. [Proposal 3: Using the `.gitlab/ci/events` folder](proposal-3-using-the-gitlab-ci-events-folder.md) + Involves file reading for every event. +1. [Proposal 4: Creating events via CI files](proposal-4-creating-events-via-ci-files.md) + Combination of some proposals. + +Each of them has its pros and cons. There could be many more proposals and we +would like to discuss them all. We can combine the best part of those proposals +and create a new one. diff --git a/doc/architecture/blueprints/gitlab_ci_events/proposal-1-using-the-gitlab-ci-file.md b/doc/architecture/blueprints/gitlab_ci_events/proposal-1-using-the-gitlab-ci-file.md new file mode 100644 index 00000000000..7dfc3873ada --- /dev/null +++ b/doc/architecture/blueprints/gitlab_ci_events/proposal-1-using-the-gitlab-ci-file.md @@ -0,0 +1,60 @@ +--- +owning-stage: "~devops::verify" +description: 'GitLab CI Events Proposal 1: Using the .gitlab-ci.yml file' +--- + +# GitLab CI Events Proposal 1: Using the `.gitlab-ci.yml` file + +Currently, we have two proof-of-concept (POC) implementations: + +- [GitLab CI Workflows PoC](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/91244) +- [PoC NPM CI events](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/111693) + +They both have similar ideas; + +1. Find a new CI Config syntax to define the pipeline events. + + Example 1: + + ```yaml + workflow: + events: + - events/package/published + + # or + + workflow: + on: + - events/package/published + ``` + + Example 2: + + ```yaml + spec: + on: + - events/package/published + - events/package/removed + # on: + # package: [published, removed] + --- + do_something: + script: echo "Hello World" + ``` + +1. Upsert an event to the database when creating a pipeline. +1. Create [EventStore subscriptions](../../../development/event_store.md) to handle the events. + +## Problems & Questions + +1. The CI config of a project can be anything; + - `.gitlab-ci.yml` by default + - another file in the project + - another file in another project + - completely a remote/external file + + How do we handle these cases? +1. Since we have these problems above, should we keep the events in its own file? (`.gitlab-ci-events.yml`) +1. Do we only accept the changes in the main branch? +1. We try to create event subscriptions every time a pipeline is created. +1. Can we move the existing workflows into the new CI events, for example, `merge_request_event`? diff --git a/doc/architecture/blueprints/gitlab_ci_events/proposal-2-using-the-rules-keyword.md b/doc/architecture/blueprints/gitlab_ci_events/proposal-2-using-the-rules-keyword.md new file mode 100644 index 00000000000..6f69a0f11f0 --- /dev/null +++ b/doc/architecture/blueprints/gitlab_ci_events/proposal-2-using-the-rules-keyword.md @@ -0,0 +1,38 @@ +--- +owning-stage: "~devops::verify" +description: 'GitLab CI Events Proposal 2: Using the rules keyword' +--- + +# GitLab CI Events Proposal 2: Using the `rules` keyword + +Can we do it with our current [`rules`](../../../ci/yaml/index.md#rules) system? + +```yaml +workflow: + rules: + - events: ["package/*"] + +test_package_published: + script: echo testing published package + rules: + - events: ["package/published"] + +test_package_removed: + script: echo testing removed package + rules: + - events: ["package/removed"] +``` + +1. We don't upsert anything to the database. +1. We'll have a single worker which subcribes to events +like `store.subscribe ::Ci::CreatePipelineFromEventWorker, to: ::Issues::CreatedEvent`. +1. The worker just runs `Ci::CreatePipelineService` with the correct parameters, the rest +will be handled by the `rules` system. Of course, we'll need modifications to the `rules` system to support `events`. + +## Problems & Questions + +1. For every defined event run, we need to enqueue a new `Ci::CreatePipelineFromEventWorker` job. +1. The worker will need to run `Ci::CreatePipelineService` for every event run. +This may be costly because we go through every cycle of `Ci::CreatePipelineService`. +1. This would be highly inefficient. +1. Can we move the existing workflows into the new CI events, for example, `merge_request_event`? diff --git a/doc/architecture/blueprints/gitlab_ci_events/proposal-3-using-the-gitlab-ci-events-folder.md b/doc/architecture/blueprints/gitlab_ci_events/proposal-3-using-the-gitlab-ci-events-folder.md new file mode 100644 index 00000000000..ad76b7f8dd4 --- /dev/null +++ b/doc/architecture/blueprints/gitlab_ci_events/proposal-3-using-the-gitlab-ci-events-folder.md @@ -0,0 +1,64 @@ +--- +owning-stage: "~devops::verify" +description: 'GitLab CI Events Proposal 3: Using the .gitlab/ci/events folder' +--- + +# GitLab CI Events Proposal 3: Using the `.gitlab/ci/events` folder + +We can also approach this problem by creating separate files for events. + +Let's say we'll have the `.gitlab/ci/events` folder (or `.gitlab/workflows/ci`). + +We can define events in the following format: + +```yaml +# .gitlab/ci/events/package-published.yml + +spec: + events: + - name: package/published + +--- + +include: + - local: .gitlab-ci.yml + with: + event: $[[ gitlab.event.name ]] +``` + +And in the `.gitlab-ci.yml` file, we can use the input; + +```yaml +# .gitlab-ci.yml + +spec: + inputs: + event: + default: push + +--- + +job1: + script: echo "Hello World" + +job2: + script: echo "Hello World" + +job-for-package-published: + script: echo "Hello World" + rules: + - if: $[[ inputs.event ]] == "package/published" +``` + +When an event happens; + +1. We'll enqueue a new job for the event. +1. The job will search for the event file in the `.gitlab/ci/events` folder. +1. The job will run `Ci::CreatePipelineService` for the event file. + +## Problems & Questions + +1. For every defined event run, we need to enqueue a new job. +1. Every event-job will need to search for files. +1. This would be only for the project-scope events. +1. This can be inefficient because of searching for files for the project for every event. diff --git a/doc/architecture/blueprints/gitlab_ci_events/proposal-4-creating-events-via-ci-files.md b/doc/architecture/blueprints/gitlab_ci_events/proposal-4-creating-events-via-ci-files.md new file mode 100644 index 00000000000..5f10ba1fbb2 --- /dev/null +++ b/doc/architecture/blueprints/gitlab_ci_events/proposal-4-creating-events-via-ci-files.md @@ -0,0 +1,73 @@ +--- +owning-stage: "~devops::verify" +description: 'GitLab CI Events Proposal 4: Creating events via CI files' +--- + +# GitLab CI Events Proposal 4: Creating events via CI files + +Each project can have its own event configuration file. Let's call it `.gitlab-ci-event.yml` for now. +In this file, we can define events in the following format: + +```yaml +events: + - package/published + - issue/created +``` + +When this file is changed in the project repository, it is parsed and the events are created, updated, or deleted. +This is highly similar to [Proposal 1](proposal-1-using-the-gitlab-ci-file.md) except that we don't need to +track pipeline creations every time. + +1. Upsert events to the database when `.gitlab-ci-event.yml` is updated. +1. Create [EventStore subscriptions](../../../development/event_store.md) to handle the events. + +## Filtering jobs + +We can filter jobs by using the `rules` keyword. For example: + +```yaml +test_package_published: + script: echo testing published package + rules: + - events: ["package/published"] + +test_package_removed: + script: echo testing removed package + rules: + - events: ["package/removed"] +``` + +Otherwise, we can make it work either a CI variable; + +```yaml +test_package_published: + script: echo testing published package + rules: + - if: $CI_EVENT == "package/published" + +test_package_removed: + script: echo testing removed package + rules: + - if: $CI_EVENT == "package/removed" +``` + +or an input like in the [Proposal 3](proposal-3-using-the-gitlab-ci-events-folder.md); + +```yaml +spec: + inputs: + event: + default: push + +--- + +test_package_published: + script: echo testing published package + rules: + - if: $[[ inputs.event ]] == "package/published" + +test_package_removed: + script: echo testing removed package + rules: + - if: $[[ inputs.event ]] == "package/removed" +``` diff --git a/doc/architecture/blueprints/gitlab_ml_experiments/index.md b/doc/architecture/blueprints/gitlab_ml_experiments/index.md new file mode 100644 index 00000000000..90adfc41257 --- /dev/null +++ b/doc/architecture/blueprints/gitlab_ml_experiments/index.md @@ -0,0 +1,170 @@ +--- +status: proposed +creation-date: "2023-04-13" +authors: [ "@andrewn" ] +coach: "@grzesiek" +--- + +# GitLab Service-Integration: AI and Beyond + +This document is an abbreviated proposal for Service-Integration to allow teams within GitLab to rapidly build new application features that leverage AI, ML, and data technologies. + +## Executive Summary + +This document proposes a service-integration approach to setting up infrastructure to allow teams within GitLab to build new application features that leverage AI, ML, and data technologies at a rapid pace. The scope of the document is limited specifically to internally hosted features, not third-party APIs. The current application architecture runs most GitLab application features in Ruby. However, many ML/AI experiments require different resources and tools, implemented in different languages, with huge libraries that do not always play nicely together, and have different hardware requirements. Adding all these features to the existing infrastructure will increase the size of the GitLab application container rapidly, resulting in slower startup times, increased number of dependencies, security risks, negatively impacting development velocity, and increasing complexity due to different hardware requirements. As an alternative, the proposal suggests adding services to avoid overloading GitLabs main workloads. These services will run independently with isolated resources and dependencies. By adding services, GitLab can maintain the availability and security of GitLab.com, and enable engineers to rapidly iterate on new ML/AI experiments. + +## Scope + +The infrastructure, platform, and other changes related to ML/AI experiments is broad. This blueprint is limited specifically to the following scope: + +1. Production workloads, running (directly or indirectly) as a result of requests into the GitLab application (`gitlab.com`), or an associated subdomains (for example, `codesuggestions.gitlab.com`). +1. Excludes requests from the GitLab application, made to third-party APIs outside of our infrastructure. From an Infrastructure point-of-view, external AI/ML API requests are no different from other API (non ML/AI) requests and generally follow the existing guidelines that are in place for calling external APIs. +1. Excludes training and tuning workloads not _directly_ connected to our production workloads. Training and tuning workloads are distinct from production workloads and will be covered by their own blueprint(s). + +## Running Production ML/AI experiment workloads + +### Why Not Simply Continue To Use The Existing Application Architecture? + +Let's start with some background on how the application is deployed: + +1. Most GitLab application features are implemented in Ruby and run in one of two types of Ruby deployments: broadly Rails and Sidekiq (although we do partition this traffic further for different workloads). +1. These Ruby workloads have two main container images `gitlab-webservice-ee` and `gitlab-sidekiq-ee`. All the code, libraries, binaries, and other resources that we use to support the main Ruby part of the codebase are embedded within these images. +1. There are thousands of pods running these containers in production for GitLab.com at any moment in time. They are started up and shut down at a high rate throughout the day as traffic demands on the site fluctuate. +1. For _most_ new features developed, any new supporting resources need to be added to either one, or both of these containers. + +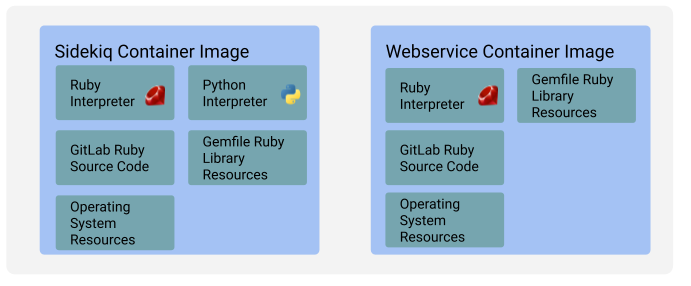\ +[source](https://docs.google.com/drawings/d/1RiTUnsDSkTGaMqK_RfUlCd_rQ6CgSInhfQJNewIKf1M/edit) + +Many of the initial discussions focus on adding supporting resources to these existing containers ([example](https://gitlab.com/gitlab-org/gitlab/-/issues/403630#note_1345192671)). Choosing this approach would have many downsides, in terms of both the velocity at which new features can be iterated on, and in terms of the availability of GitLab.com. + +Many of the AI experiments that GitLab is considering integrating into the application are substantially different from other libraries and tools that have been integrated in the past. + +1. ML toolkits are **implemented in a plethora of languages**, each requiring separate runtimes. Python, C, C++ are the most common, but there is a long tail of languages used. +1. There are a very large number of tools that we're looking to integrate with and **no single tool will support all the features that are being investigated**. Tensorflow, PyTorch, Keras, Scikit-learn, Alpaca are just a few examples. +1. **These libraries are huge**. Tensorflow's container image with GPU support is 3GB, PyTorch is 5GB, Keras is 300MB. Prophet is ~250MB. +1. Many of these **libraries do not play nicely together**: they may have dependencies that are not compatible, or require different versions of Python, or GPU driver versions. + +It's likely that in the next few months, GitLab will experiment with many different features, using many different libraries. + +Trying to deploy all of these features into the existing infrastructure would have many downsides: + +1. **The size of the GitLab application container would expand very rapidly** as each new experiment introduces a new set of supporting libraries, each library is as big, or bigger, than the existing GitLab application within the container. +1. **Startup times for new workloads would increase**, potentially impacting the availability of GitLab.com during high-traffic periods. +1. The number of dependencies within the container would increase rapidly, putting pressure on the engineering teams to **keep ahead of exploits and vulnerabilities**. +1. **The security attack surface within the container would be greatly increased** with each new dependency. These containers include secrets which, if leaked via an exploit would need costly application-wide secret rotation to be done. +1. **Development velocity will be negatively impacted** as engineers work to avoid dependency conflicts between libraries. +1. Additionally there may be **extra complexity due to different hardware requirements** for different libraries with appropriate drivers etc for GPUs, TPUs, CUDA versions, etc. +1. Our Kubernetes workloads have been tuned for the existing multithreaded Ruby request (Rails) and message (Sidekiq) processes. Adding extremely resource-intensive applications into these workloads would affect unrelated requests, **starving requests of CPU and memory and requiring complex tuning to ensure fairness**. Failure to do this would impact our availability of GitLab.com. + +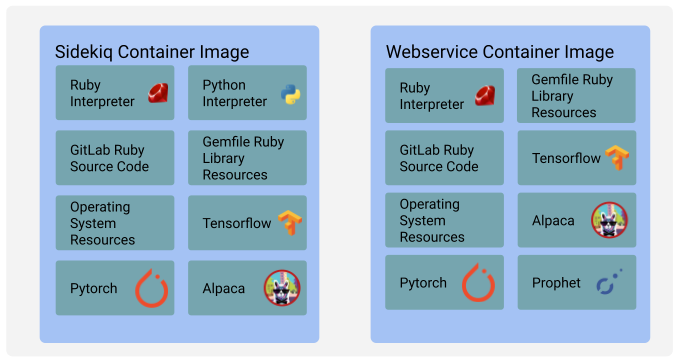 +\ +[source](https://docs.google.com/drawings/d/1aYffBzzea5QuZ-mTMteowefbV7VmsOuq2v4BqbPd6KE/edit) + +### Proposal: Avoid Overfilling GitLabs Application Containers with Service-Integration + +GitLab.com migrated to Kubernetes several years back, but for numerous good reasons, the application architecture deployed for GitLab.com remains fairly simple. + +Instead of embedding these applications directly into the Rails and/or Sidekiq containers, we run them as small, independent Kubernetes deployments, isolated from the main workload. + +\ +[source](https://docs.google.com/drawings/d/1ZPprcSYH5Oqp8T46I0p1Hhr-GD55iREDvFWcpQq9dTQ/edit) + +The service-integration approach has already been used for the [Suggested Reviewers feature](https://gitlab.com/gitlab-com/gl-infra/readiness/-/merge_requests/114) that has been deployed to GitLab.com. + +This approach would have many advantages: + +1. **Componentization and Replaceability**: some of these AI feature experiments will likely be short-lived. Being able to shut them down (possibly quickly, in an emergency, such as a security breach) is important. If they are terminated, they are less likely to leave technical debt behind in our main application workloads. +1. **Security Isolation**: experimental services can run with access to a minimal set of secrets, or possibly none. Ideally, the services would be stateless, with data being passed in, processed, and returned to the caller without access to PostgreSQL or other data sources. In the event of a remote code exploit or other security breach, the attacker would have limited access to sensitive data. + 1. In lieu of direct access to the main or CI Postgres clusters, services would be provided with access to the internal GitLab API through a predefined internal URL. The platform should provide instrumentation and monitoring on this address. + 1. In future iterations, but out of scope for the initial delivery, the platform could facilitate automatic authentication against the internal API, for example by managing and injecting short-lived API tokens into internal API calls, or OIDC etc. +1. **Resource Isolation**: resource-intensive workloads would be isolated to individual containers. OOM failures would not impact requests outside of the experiment. CPU saturation would not slow down unrelated requests. +1. **Dependency Isolation**: different AI libraries will have conflicting dependencies. This will not be an issue if they're run as separate services in Kubernetes. +1. **Container Size**: the size of the main application containers is not drastically increased, placing a burden on the application. +1. **Distribution Team Bottleneck**: The Distribution team avoids becoming a bottleneck as demands for many different libraries to be included in the main application containers increase. +1. **Stronger Ownership of Workloads**: teams can better understand how their workloads are running as they run in isolation. + +However, there are several outstanding questions: + +1. **Availability Requirements**: would experimental services have the same availability requirements (and alerting requirements) as the main application? +1. **Oncall**: would teams be responsible for handling pager alerts for their services? +1. **Support for non-SAAS GitLab instances**: initially all experiments would target GitLab.com, but eventually we may need to consider how to support other instances. + 1. There are three possible modes for services: + 1. `M1`: GitLab.com only: only GitLab.com supports the service. + 1. `M2`: SAAS-hosted for use with self-managed instance and instance-hosted: a singular SAAS-hosted service supports self-managed instances and GitLab.com. This is similar to the [GitLab Plus proposal](https://gitlab.com/groups/gitlab-org/-/epics/308). + 1. `M3`: Instance-hosted: each instance has a copy of the service. GitLab.com has a copy for GitLab.com. Self-managed instances host their copy of the service. This is similar to the container registry or Gitaly today. + 1. Initially, most experiments will probably be option 1 but may be promoted to 2 or 3 as they mature. +1. **Promotion Process**: ML/AI experimental features will need to be promoted to non-experimental status as they mature. A process for this will need to be established. + +#### Proposed Guidelines for Building ML/AI Services + +1. Avoid adding any large ML/AI libraries needed to support experimentation to the main application. +1. Create an platform to support individual ML/AI experiments. +1. Encourage supporting services to be stateless (excluding deployed models and other resources generated during ML training). +1. ML/AI experiment support services must not access main application datastores, including but not limited to main PostgreSQL, CI PostgreSQL, and main application Redis instances. +1. In the main application, client code for services should reside behind a feature-flag toggle, for fine-grained control of the feature. + +#### Technical Details + +Some points, in greater detail: + +##### Traffic Access + +1. Ideally these services should not be exposed externally to Internet traffic: only internally to our existing Rails and Sidekiq workloads should be routed. + 1. For services intended to run at `M2`: "SAAS-hosted for use with self-managed instance and instance-hosted", we would expect to migrate the service to a public endpoint once sufficient security review has been performed. + +##### Platform Requirements + +In order to quickly deploy and manage experiments, an minimally viable platform will need to be provided to stage-group teams. The technical implementation details of this platform are out of scope for this blueprint and will require their own blueprint (to follow). + +However, Service-Integration will establish certain necessary and optional requirements that the platform will need to satisfy. + +###### Ease of Use, Ownership Requirements + +1. <a name="R100">`R100`</a>: Required: the platform should be easy to use: imagine Heroku with [GitLab Production Readiness-approved](https://about.gitlab.com/handbook/engineering/infrastructure/production/readiness/) defaults. +1. <a name="R110">`R110`</a>: Required: with the exception of an Infrastructure-led onboarding process, services are owned, deployed and managed by stage-group teams. In other words,services follow a "You Build It, You Run It" model of ownership. +1. <a name="R120">`R120`</a>: Required: programming-language agnostic: no requirements for services. Services should be packaged as container images. +1. <a name="R130">`R130`</a>: Recommended: Each service should be evaluated against the GitLab.com [Service Maturity Model](https://about.gitlab.com/handbook/engineering/infrastructure/service-maturity-model/). +1. <a name="R140">`R140`</a>: Recommended: services using the platform have expedited production-readiness processes. + 1. Production-readiness requirements graded by service maturity: low-traffic, low-maturity experimental services will have lower requirement thresholds than more mature services. + 1. By default, the platform should provide services with defaults that would pass production-readiness review for the lowest service maturity-level. + 1. At introduction, lowest maturity services can be deployed without production readiness, provided the meet certain automatically validated requirements. This removes Infrastructure gate-keeping from being a blocker to experimental service delivery. + +###### Observability Requirements + +1. <a name="R200">`R200`</a>: Required: the platform must provide SLIs for services out-of-the-box. + 1. While it is recommended that services expose internal metrics, it is not mandatory. The platform will provide monitoring from the load-balancer. This is to speed up deployment by removing barriers to experimentation. + 1. For services that provide internal metrics scrape endpoints, the platform must be configurable to collect these. + 1. The platform must provide generic load-balancer level SLIs for all services. Service owners must be able to select from constructing SLIs from internal application metrics, the platform-provided external SLIs, or a combination of both. +1. <a name="R210">`R210`</a>: Required: Observability dashboards, rules, alerts (with per-term routing) must be generated from a manifest. +1. <a name="R220">`R220`</a>:Required: standardized logging infrastructure. + 1. Mandate that all logging emitted from services must be Structured JSON. Text logs are permitted but not recommended. + 1. See [Common Service Libraries](#common-service-libraries) for more details of building common SDKs for observability. + +###### Deployment Requirements + +1. <a name="R300">`R300`</a>: Required: No secrets stored in CI/CD. + 1. Authentication with Cloud Provider Resources should be exclusively via OIDC, managed as part of the platform. + 1. Secrets should be stored in the Infrastructure-provided Hashicorp Vault for the environment and passed to applications through files or environment variables. + 1. Generation and management of service account tokens should be done declaratively, without manual interaction. +1. <a name="R310">`R310`</a>: Required: multiple environment should be supported, eg Staging and Production. +1. <a name="R320">`R320`</a>: Required: the platform should be cost-effective. Kubernetes clusters should support multiple services and teams. +1. <a name="R330">`R330`</a>: Recommended: gradual rollouts, rollbacks, blue-green deployments. +1. <a name="R340">`R340`</a>: Required: services should be isolated from one another. +1. <a name="R350">`R350`</a>: Recommended: services should have the ability to specify node characteristic requirements (eg, GPU). +1. <a name="R360">`R360`</a>: Required: Developers should not need knowledge of Helm, Kubernetes, Prometheus in order to deploy. All required values are configured and validated in project-hosted manifest before generating Kubernetes manifests, Prometheus rules, etc. +1. <a name="R370">`R370`</a>: Initially services should be synchronous only - using REST or GRPC requests. + 1. This does not however preclude long-running HTTP(s) requests, for example long-polling or Websocket requests. +1. <a name="R390">`R390`</a>: Each service hosted in its own GitLab repository with deployment manifest stored in the repository. + 1. Continuous deployments that are initiated from the CI pipeline of the corresponding GitLab repository. + +##### Security Requirements + +1. <a name="R400">`R400`</a>: stateful services deployed on the platform that utilize their own stateful storage (for example, custom deployed Postgres instance), must not store application security tokens, cloud-provider service keys or other long-lived security tokens in their stateful stores. +1. <a name="R410">`R410`</a>: long-lived shared secrets are discouraged, and should be referenced in the service manifest as such, to allow for accounting and monitoring. +1. <a name="R420">`R420`</a>: services using long-lived shared secrets should ensure that secret rotation can take place without downtime. + 1. During a rotation, old and new generations of secrets should pass authentication, allowing gradual roll-out of new secrets. + +##### Common Service Libraries + +1. <a name="R500">`R500`</a>: Experimental services would be strongly encouraged to adopt and use [LabKit](https://gitlab.com/gitlab-org/labkit) (for Go services), or [LabKit-Ruby](https://gitlab.com/gitlab-org/ruby/gems/labkit-ruby) for observability, context, correlation, FIPs verification, etc. + 1. At present, there is no LabKit-Python library, but some experiments will run in Python, so building a library to providing observability, context, correlation services in Python will be required. diff --git a/doc/architecture/blueprints/gitlab_observability_backend/metrics/index.md b/doc/architecture/blueprints/gitlab_observability_backend/metrics/index.md index c5bd2440b0c..3edb01d9140 100644 --- a/doc/architecture/blueprints/gitlab_observability_backend/metrics/index.md +++ b/doc/architecture/blueprints/gitlab_observability_backend/metrics/index.md @@ -8,6 +8,8 @@ owning-stage: "~monitor::observability" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # GitLab Observability Backend - Metrics ## Summary @@ -93,9 +95,9 @@ Additionally, since we intend to ingest data via Prometheus `remote_write` API, We also need to make sure to avoid writing a lot of small writes into Clickhouse, therefore it’d be prudent to batch data before writing it into Clickhouse. -We must also make sure ingestion remains decoupled with `Storage` so as to reduce undue dependence on a given storage implementation. While we do intend to use Clickhouse as our backing storage for any foreseeable future, this ensures we do not tie ourselves in into Clickhouse too much should future business requirements warrant the usage of a different backend/technology. A good way to implement this in Golang would be our implementations adhering to a standard interface, the following for example: +We must also make sure ingestion remains decoupled with `Storage` so as to reduce undue dependence on a given storage implementation. While we do intend to use Clickhouse as our backing storage for any foreseeable future, this ensures we do not tie ourselves in into Clickhouse too much should future business requirements warrant the usage of a different backend/technology. A good way to implement this in Go would be our implementations adhering to a standard interface, the following for example: -```golang +```go type Storage interface { Read( ctx context.Context, diff --git a/doc/architecture/blueprints/graphql_api/index.md b/doc/architecture/blueprints/graphql_api/index.md index 95ff834cd27..2c277049434 100644 --- a/doc/architecture/blueprints/graphql_api/index.md +++ b/doc/architecture/blueprints/graphql_api/index.md @@ -8,6 +8,8 @@ owning-stage: "~devops::manage" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # GraphQL API [GraphQL](https://graphql.org/) is a data query and manipulation language for diff --git a/doc/architecture/blueprints/object_pools/index.md b/doc/architecture/blueprints/object_pools/index.md new file mode 100644 index 00000000000..3f3a0341e4a --- /dev/null +++ b/doc/architecture/blueprints/object_pools/index.md @@ -0,0 +1,495 @@ +--- +status: proposed +creation-date: "2023-03-30" +authors: [ "@pks-gitlab" ] +coach: [ ] +approvers: [ ] +owning-stage: "~devops::systems" +participating-stages: [ "~devops::create" ] +--- + +# Iterate on the design of object pools + +## Summary + +Forking repositories is at the heart of many modern workflows for projects +hosted in GitLab. As most of the objects between a fork and its upstream project +will typically be the same, this opens up potential for optimizations: + +- Creating forks can theoretically be lightning fast if we reuse much of the + parts of the upstream repository. + +- We can save on storage space by deduplicating objects which are shared. + +This architecture is currently implemented with object pools which hold objects +of the primary repository. But the design of object pools has organically grown +and is nowadays showing its limits. + +This blueprint explores how we can iterate on the design of object pools to fix +long standing issues with it. Furthermore, the intent is to arrive at a design +that lets us iterate more readily on the exact implementation details of object +pools. + +## Motivation + +The current design of object pools is showing problems with scalability in +various different ways. For a large part the problems come from the fact that +object pools have organically grown and that we learned as we went by. + +It is proving hard to fix the overall design of object pools because there is no +clear ownership. While Gitaly provides the low-level building blocks to make +them work, it does not have enough control over them to be able to iterate on +their implementation details. + +There are thus two major goals: taking ownership of object pools so that it +becomes easier to iterate on the design, and fixing scalability issues once we +can iterate. + +### Lifecycle ownership + +While Gitaly provides the interfaces to manage object pools, the actual life +cycle of them is controlled by the client. A typical lifecycle of an object pool +looks as following: + +1. An object pool is created via `CreateObjectPool()`. The caller provides the + path where the object pool shall be created as well as the origin repository + from which the repository shall be created. + +1. The origin repository needs to be linked to the object pool explicitly by + calling `LinkRepositoryToObjectPool()`. + +1. The object pool needs to be regularly updated via `FetchIntoObjectPool()` + that fetches all changes from the primary pool member into the object pool. + +1. To create forks, the client needs to call `CreateFork()` followed by + `LinkRepositoryToObjectPool()`. + +1. Repositories of forks are unlinked by calling `DisconnectGitAlternates()`. + This will reduplicate objects. + +1. The object pool is deleted via `DeleteObjectPool()`. + +This lifecycle is complex and leaks a lot of implementation details to the +caller. This was originally done in part to give the Rails side control and +management over Git object visibility. GitLab project visibility rules are +complex and not a Gitaly concern. By exposing these details Rails can control +when pool membership links are created and broken. It is not clear at the +current point in time how the complete system works and its limits are not +explicitly documented. + +In addition to the complexity of the lifecycle we also have multiple sources of +truth for pool membership. Gitaly never tracks the set of members of a pool +repository but can only tell for a specific repository that it is part of said +pool. Consequently, Rails is forced to maintain this information in a database, +but it is hard to maintain that information without becoming stale. + +### Repository maintenance + +Related to the lifecycle ownership issues is the issue of repository +maintenance. As mentioned, keeping an object pool up to date requires regular +calls to `FetchIntoObjectPool()`. This is leaking implementation details to the +client, but was done to give the client control over syncing the primary +repository with its object pool. With this control, private repositories can be +prevented from syncing and consquently leaking objects to other repositories in +the fork network. + +We have had good success with moving repository maintenance into Gitaly so that +clients do not need to know about on-disk details. Ideally, we would do the same +for repositories that are the primary member of an object pool: if we optimize +its on-disk state, we will also automatically update the object pool. + +There are two issues that keep us from doing so: + +- Gitaly does not know about the relationship between an object pool and its + members. + +- Updating object pools is expensive. + +By making Gitaly the single source of truth for object pool memberships we would +be in a position to fix both issues. + +### Fast forking + +In the current implementation, Rails first invokes `CreateFork()` which results +in a complete `git-clone(1)` being performed to generate the fork repository. +This is followed by `LinkRepositoryToObjectPool()` to link the fork with the +object pool. It is not until housekeeping is performed on the fork repository +that objects are deduplicated. This is not only leaking implementation details +to clients, but it also keeps us from reaping the full potential benefit of +object pools. + +In particular, creating forks is a lot slower than it could be since a clone is +always performed before linking. If the steps of creating the fork and linking +the fork to the pool repository were unified, the initial clone could be +avoided. + +### Clustered object pools + +Gitaly Cluster and object pools development overlapped. Consequently they are +known to not work well together. Praefect does neither ensure that repositories +with object pools have their object pools present on all nodes, nor does it +ensure that object pools are in a known state. If at all, object pools only work +by chance. + +The current state has led to cases where object pools were missing or had +different contents per node. This can result in inconsistently observed state in +object pool members and writes that depend on the object pool's contents to +fail. + +One way object pools might be handled for clustered Gitaly could be to have the +pool repositories duplicated on nodes that contain repositories dependent on +them. This would allow members of a fork network to exist of different nodes. To +make this work, repository replciation would have to be aware of object pools +and know when it needs to duplicate them onto a particular node. + +## Requirements + +There are a set of requirements and invariants that must be given for any +particular solution. + +### Private upstream repositories should not leak objects to forks + +When a project has a visibility setting that is not public, the objects in the +repository should not be fetched into an object pool. An object pool should only +ever contain objects from the upstream repository that were at one point public. +This prevents private upstream repositories from having objects leaked to forks +through a shared object pool. + +### Forks cannot sneak objects into upstream projects + +It should not be possible to make objects uploaded in a fork repository +accessible in the upstream repository via a shared object pool. Otherwise +potentially unauthorized users would be able to "sneak in" objects into +repositories by simply forking them. + +Despite leading to confusion, this could also serve as a mechanism to corrupt +upstream repositories by introducing objects that are known to be broken. + +### Object pool lifetime exceeds upstream repository lifetime + +If the upstream repository gets deleted, its object pool should remain in place +to provide continued deduplication of shared objects between the other +repositories in the fork network. Thus it can be said that the lifetime of the +object pool is longer than the lifetime of the upstream repository. An object +pool should only be deleted if there are no longer any repositories referencing +it. + +### Object lifetime + +By deduplicating objects in a fork network, repositories become dependent on the +object pool. Missing objects in the pooled repository could lead to corruption +of repositories in the fork network. Therefore, objects in the pooled repository +must continue to exist as long as there are repositories referencing them. + +Without a mechanism to accurately determine if a pooled object is referenenced +by one of more repositories, all objects in the pooled repository must remain. +Only when there are no repositories referencing the object pool can the pooled +repository, and therfore all its objects, be removed. + +### Object sharing + +An object that is deduplicated will become accessible from all forks of a +particular repository, even if it has never been reachable in any of the forks. +The consequence is that any write to an object pool immediately influences all +of its members. + +We need to be mindful of this property when repositories connected to an object +pool are replicated. As the user-observable state should be the same on all +replicas, we need to ensure that both the repository and its object pool are +consistent across the different nodes. + +## Proposal + +In the current design, management of object pools mostly happens on the client +side as they need to manage their complete lifecyclethem. This requires Rails to +store the object pool relationships in the Rails database, perform fine-grained +management of every single step of an object pool's life, and perform periodic +Sidekiq jobs to enforce state by calling idempotent Gitaly RPCs. This design +significantly increases complexity of an already-complex mechanism. + +Instead of handling the full lifecycle of object pools on the client-side, this +document proposes to instead encapsulate the object pool lifecycle management +inside of Gitaly. Instead of performing low-level actions to maintain object +pools, clients would only need to tell Gitaly about updated relationships +between a repository and its object pool. + +This brings us multiple advantages: + +- The inherent complexity of the lifecycle management is encapsulated in a + single place, namely Gitaly. + +- Gitaly is in a better position to iterate on the low-level technical design of + object pools in case we find a better solution compared to "alternates" in the + future. + +- We can ensure better interplay between Gitaly Cluster, object pools and + repository housekeeping. + +- Gitaly becomes the single source of truth for object pool relationships and + can thus start to manage it better. + +Overall, the goal is to raise the abstraction level so that clients need to +worry less about the technical details while Gitaly is in a better position to +iterate on them. + +### Move lifecycle management of pools into Gitaly + +The lifecycle management of object pools is leaking too many details to the +client, and by doing so makes parts things both hard to understand and +inefficient. + +The current solution relies on a set of fine-grained RPCs that manage the +relationship between repositories and their object pools. Instead, we are aiming +for a simplified approach that only exposes the high-level concept of forks to +the client. This will happen in the form of three RPCs: + +- `ForkRepository()` will create a fork of a given repository. If the upstream + repository does not yet have an object pool, Gitaly will create it. It will + then create the new repository and automatically link it to the object pool. + The upstream repository will be recorded as primary member of the object pool, + the fork will be recorded as a secondary member of the object pool. + +- `UnforkRepository()` will remove a repository from the object pool it is + connected to. This will stop deduplication of objects. For the primary object + pool member this also means that Gitaly will stop pulling new objects into the + object pool. + +- `GetObjectPool()` returns the object pool for a given repository. The pool + description will contain information about the pool's primary object pool + member as well as all secondary object pool members. + +Furthermore, the following changes will be implemented: + +- `RemoveRepository()` will remove the repository from its object pool. If it + was the last object pool member, the pool will be removed. + +- `OptimizeRepository()`, when executed on the primary object pool member, will + also update and optimize the object pool. + +- `ReplicateRepository()` needs to be aware of object pools and replicate them + correctly. Repositories shall be linked to and unlink from object pools as + required. While this is a step towards fixing the Praefect world, which may + seem redundant given that we plan to deprecate Praefect anyway, this RPC call + is also used for other use cases like repository rebalancing. + +With these changes, Gitaly will have much tighter control over the lifecycle of +object pools. Furthermore, as it starts to track the membership of repositories +in object pools it can become the single source of truth for fork networks. + +### Fix inefficient maintenance of object pools + +In order to update object pools, Gitaly performs a fetch of new objects from the +primary object pool member into the object pool. This fetch is inefficient as it +needs to needlessly negotiate objects that are new in the primary object pool +member. But given that objects are deduplicated already in the primary object +pool member it means that it should only have objects in its object database +that do not yet exist in the object pool. Consequently, we should be able to +skip the negotiation completely and instead link all objects into the object +pool that exist in the source repository. + +In the current design, these objects are kept alive by creating references to +the just-fetched objects. If the fetch deleted references or force-updated any +references, then it may happen that previously-referenced objects become +unreferenced. Gitaly thus creates keep-around references so that they cannot +ever be deleted. Furthermore, those references are required in order to properly +replicate object pools as the replication is reference-based. + +These two things can be solved in different ways: + +- We can set the `preciousObjects` repository extension. This will instruct all + versions of Git which understand this extension to never delete any objects + even if `git-prune(1)` or similar commands were executed. Versions of Git that + do not understand this extension would refuse to work in this repository. + +- Instead of replicating object pools via `git-fetch(1)`, we can instead + replicate them by sending over all objects part of the object database. + +Taken together this means that we can stop writing references in object pools +altogether. This leads to efficient updates of object pools by simply linking +all new objects into place, and it fixes issues we have seen with unbounded +growth of references in object pools. + +## Design and implementation details + +<!-- + +This section intentionally left blank. I first want to reach consensus on the +bigger picture I'm proposing in this blueprint before I iterate and fill in the +lower-level design and implementation details. + +--> + +## Problems with the design + +As mentioned before, object pools are not a perfect solution. This section goes +over the most important issues. + +### Complexity of lifecycle management + +Even though the lifecycle of object pools becomes easier to handle once it is +fully owned by Gitaly, it is still complex and needs to be considered in many +ways. Handling object pools in combination with their repositories is not an +atomic operation as any action by necessity spans over at least two different +resources. + +### Performance issues + +As object pools deduplicate objects, the end result is that object pool members +never have the full closure of objects in a single packfile. This is not +typically an issue for the primary object pool member, which by definition +cannot diverge from the object pool's contents. But secondary object pool +members can and often will diverge from the original contents of the upstream +repository. + +This leads to two different sets of reachable objects in secondary object pool +members. Unfortunately, due to limitations in Git itself, this precludes the use +of a subset of optimizations: + +- Packfiles cannot be reused as efficiently when serving fetches to serve + already-deltified objects. This requires Git to recompute deltas on the fly + for object pool members which have diverged from object pools. + +- Packfile bitmaps can only exist in object pools as it is not possible nor + easily feasible for these bitmaps to cover multiple object databases. This + requires Git to traverse larger parts of the object graph for many operations + and especially when serving fetches. + +### Dependent writes across repositories + +The design of object pools introduces significant complexity into the Raft world +where we use a write-ahead log for all changes to repositories. In the ideal +case, a Raft-based design would only need to care about the write-ahead log of a +single repository when considering requests. But with object pools, we are +forced to consider both reads and writes for a pooled repository to be dependent +on all writes in its object pool having been applied. + +## Alternative Solutions + +The proposed solution is not obviously the best choice as it has issues both +with complexity (management of the lifecycle) and performance (inefficiently +served fetches for pool members). + +This section explores alternatives to object pools and why they have not been +chosen as the new target architecture. + +### Stop using object pools altogether + +An obvious way to avoid all of the complexity is to stop using object pools +altogether. While it is charming from an engineering point of view as we can +significantly simplify the architecture, it is not a viable approach from the +product perspective as it would mean that we cannot support efficient forking +workflows. + +### Primary repository as object pool + +Instead of creating an explicit object pool repository, we could just use the +upstream repository as an alternate object database of all forks. This avoids a +lot of complexity around managing the lifetime of the object pool, at least +superficially. Furthermore, it circumvents the issue of how to update object +pools as it will always match the contents of the upstream repository. + +It has a number of downsides though: + +- Normal repositories can now have different states, where some of the + repositories are allowed to prune objects and others aren't. This introduces a + source of uncertainty and makes it easy to accidentally delete objects in a + normal repository and thus corrupt its forks. + +- When upstream repositories go private we must stop updating objects which are + supposed to be deduplicated across members of the fork network. This means + that we would ultimately still be forced to create object pools once this + happens in order to freeze the set of deduplicated objects at the point in + time where the repository goes private. + +- Deleting repositories becomes more complex as we need to take into account + whether a repository is linked to by forks. + +### Reference namespaces + +With `gitnamespaces(7)`, Git provides a mechanism to partition references into +different sets of namespaces. This allows us to serve all forks from a single +repository that contains all objects. + +One neat property is that we have the global view of objects referenced by all +forks together in a single object database. We can thus easily perform shared +housekeeping across all forks at once, including deletion of objects that are +not used by any of the forks anymore. Regarding objects, this is likely to be +the most efficient solution we could potentially aim for. + +There are again some downsides though: + +- Calculating usage quotas must by necessity use actual reachability of objects + into account, which is expensive to compute. This is not a showstopper, but + something to keep in mind. + +- One stated requirement is that it must not be possible to make objects + reachable in other repositories from forks. This property could theoretically + be enforced by only allowing access to reachable objects. That way an object + can only be accessed through virtual repository if the object is reachable from + its references. Reachability checks are too compute heavy for this to be practical. + +- Even though references are partitioned, large fork networks would still easily + end up with multiple millions of references. It is unclear what the impact on + performance would be. + +- The blast radius for any repository-level attacks significantly increases as + you would not only impact your own repository, but also all forks. + +- Custom hooks would have to be isolated for each of the virtual repositories. + Since the execution of Git hooks is controled it should be possible to handle + this for each of the namespaces. + +### Filesystem-based deduplication + +The idea of deduplicating objects on the filesystem level was floating around at +several points in time. While it would be nice if we could shift the burden of +this to another component, it is likely not easy to implement due to the nature +of how Git works. + +The most important contributing factor to repository sizes are Git objects. +While it would be possible to store the objects in their loose representation +and thus deduplicate on that level, this is infeasible: + +- Git would not be able to deltify objects, which is an extremely important + mechanism to reduce on-disk size. It is unlikely that the size reduction + caused by deduplication would outweigh the size reduction gained from the + deltification mechanism. + +- Loose objects are significantly less efficient when accessing the repository. + +- Serving fetches requires us to send a packfile to the client. Usually, Git is + able to reuse large parts of already-existing packfiles, which significantly + reduces the computational overhead. + +Deduplicating on the loose-object level is thus infeasible. + +The other unit that one could try to deduplicate is packfiles. But packfiles are +not deterministically generated by Git and will furthermore be different once +repositories start to diverge from each other. So packfiles are not a natural +fit for filesystem-level deduplication either. + +An alternative could be to use hard links of packfiles across repositories. This +would cause us to duplicate storage space whenever any repository decides to +perform a repack of objects and would thus be unpredictable and hard to manage. + +### Custom object backend + +In theory, it would be possible to implement a custom object backend that allows +us to store objects in such a way that we can deduplicate them across forks. +There are several technical hurdles though that keep us from doing so without +significant upstream investments: + +- Git is not currently designed to have different backends for objects. Accesses + to files part of the object database are littered across the code base with no + abstraction level. This is in contrast to the reference database, which has at + least some level of abstraction. + +- Implementing a custom object backend would likely necessitate a fork of the + Git project. Even if we had the resources to do so, it would introduce a major + risk factor due to potential incompatibilities with upstream changes. It would + become impossible to use vanilla Git, which is often a requirement that exists + in the context of Linux distributions that package GitLab. + +Both the initial and the operational risk of ongoing maintenance are too high to +really justify this approach for now. We might revisit this approach in the +future. diff --git a/doc/architecture/blueprints/object_storage/index.md b/doc/architecture/blueprints/object_storage/index.md index 4a8eeaf86a9..3f649960554 100644 --- a/doc/architecture/blueprints/object_storage/index.md +++ b/doc/architecture/blueprints/object_storage/index.md @@ -8,6 +8,8 @@ owning-stage: "~devops::data_stores" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # Object storage: `direct_upload` consolidation ## Abstract @@ -53,7 +55,7 @@ This has led to increased complexity across the board, from development [we no longer recommend](../../../administration/nfs.md) to our users and is no longer in use on GitLab.com. - Understanding all the moving parts and the flow is extremely - complicated: we have CarrierWave, Fog, Golang S3/Azure SDKs, all + complicated: we have CarrierWave, Fog, Go S3/Azure SDKs, all being used, and that complicates testing as well. - Fog and CarrierWave are not maintained to the level of the native SDKs (for example, AWS S3 SDK), so we have to maintain or monkey @@ -124,7 +126,7 @@ infrastructure. It also makes the initial installation more complex feature after feature. Implementing a direct upload by default, with a -[consolidated object storage configuration](../../../administration/object_storage.md#consolidated-object-storage-configuration) +[consolidated object storage configuration](../../../administration/object_storage.md#configure-a-single-storage-connection-for-all-object-types-consolidated-form) will reduce the number of merge requests needed to ship a new feature from four to only one. It will also remove the need for SRE intervention as the bucket will always be the same. diff --git a/doc/architecture/blueprints/organization/index.md b/doc/architecture/blueprints/organization/index.md new file mode 100644 index 00000000000..bd8d085413c --- /dev/null +++ b/doc/architecture/blueprints/organization/index.md @@ -0,0 +1,175 @@ +--- +status: ongoing +creation-date: "2023-04-05" +authors: [ "@lohrc" ] +coach: "@ayufan" +approvers: [ "@lohrc" ] +owning-stage: "~devops::data stores" +participating-stages: [] +--- + +<!-- vale gitlab.FutureTense = NO --> + +# Organization + +This document is a work in progress and represents the current state of the Organization design. + +## Glossary + +- Organization: An Organization is the umbrella for one or multiple top-level groups. Organizations are isolated from each other by default meaning that cross-namespace features will only work for namespaces that exist in a single Organization. +- Top-level group: Top-level group is the name given to the topmost group of all other groups. Groups and projects are nested underneath the top-level group. +- Cell: A Cell is a set of infrastructure components that contains multiple Organizations. The infrastructure components provided in a Cell are shared among Organizations, but not shared with other Cells. This isolation of infrastructure components means that Cells are independent from each other. +- User: An Organization has many users. Joining an Organization makes someone a user of that Organization. +- Member: Adding a user to a group or project within an Organization makes them a member. Members are always users, but users are not necessarily members of a group or project within an Organization. For instance, a user could just have accepted the invitation to join an Organization, but not be a member of any group or project it contains. +- Non-user: A non-user of an Organization means a user is not part of that specific Organization. + +## Summary + +Organizations solve the following problems: + +1. Enables grouping of top-level groups. For example, the following top-level groups would belong to the Organization `GitLab`: + 1. `https://gitlab.com/gitlab-org/` + 1. `https://gitlab.com/gitlab-com/` +1. Allows different Organizations to be isolated. Top-level groups of the same Organization can interact with each other but not with groups in other Organizations, providing clear boundaries for an Organization, similar to a self-managed instance. Isolation should have a positive impact on performance and availability as things like user dashboards can be scoped to Organizations. +1. Allows integration with Cells. Isolating Organizations makes it possible to allocate and distribute them across different Cells. +1. Removes the need to define hierarchies. An Organization is a container that could be filled with whatever hierarchy/entity set makes sense (Organization, top-level groups, etc.) +1. Enables centralized control of user profiles. With an Organization-specific user profile, administrators can control the user's role in a company, enforce user emails, or show a graphical indicator that a user as part of the Organization. An example could be adding a "GitLab employee" stamp on comments. +1. Organizations bring an on-premise-like experience to SaaS (GitLab.com). The Organization admin will have access to instance-equivalent Admin Area settings with most of the configuration controlled on Organization level. + +## Motivation + +### Goals + +The Organization focuses on creating a better experience for Organizations to manage their GitLab experience. By introducing Organizations and [Cells](../cells/index.md) we can improve the reliability, performance and availability of our SaaS Platforms. + +- Wider audience: Many instance-level features are admin only. We do not want to lock out users of GitLab.com in that way. We want to make administrative capabilities that previously only existed for self-managed users available to our SaaS users as well. This also means we would give users of GitLab.com more independence from GitLab.com admins in the long run. Today, there are actions that self-managed admins can perform that GitLab.com users have to request from GitLab.com admins. +- Improved UX: Inconsistencies between the features available at the project and group levels create navigation and usability issues. Moreover, there isn't a dedicated place for Organization-level features. +- Aggregation: Data from all groups and projects in an Organization can be aggregated. +- An Organization includes settings, data, and features from all groups and projects under the same owner (including personal namespaces). +- Cascading behavior: Organization cascades behavior to all the projects and groups that are owned by the same Organization. It can be decided at the Organization level whether a setting can be overridden or not on the levels beneath. + +### Non-Goals + +Due to urgency of delivering Organizations as a prerequisite for Cells, it is currently not a goal to build Organization functionality on the namespace framework. + +## Proposal + +We create Organizations as a new lightweight entity, with just the features and workflows which it requires. We already have much of the functionality present in groups and projects, and groups themselves are essentially already the top-level entity. It is unlikely that we need to add significant features to Organizations outside of some key settings, as top-level groups can continue to serve this purpose at least on SaaS. + +```mermaid +graph TD + o[Organization] -. has many .- g + ns[Namespace] --> g[Group] + ns[Namespace] --> pns[ProjectNamespace] -. has one .- p[Project] + ns --> un[UserNamespace] + g -. has many .- p + un -. has many .- p + ns[Namespace] -. has many .- ns[Namespace] +``` + +Self-managed instances would set a default Organization. + +### Benefits + +- No changes to URL's for groups moving under an Organization, which makes moving around top-level groups very easy. +- Low risk rollout strategy, as there is no conversion process for existing top-level groups. +- Organization becomes the key for identifying what is part of an Organization, which is likely on its own table for performance and clarity. + +### Drawbacks + +- It is unclear right now how we would avoid continuing to spend effort to build instance (or not Organization) features, in particular much of the reporting. This is not an issue on SaaS as top-level groups already have this capability, however it is a challenge on self-managed. If we introduce a built-in Organization (or just none at all) for self-managed, it seems like we would need to continue to build instance/Organization level reporting features as we would not get that for free along with the work to add to groups. +- Billing may need to be moved from top-level groups to Organization level. + +## Design and Implementation Details + +### Organization MVC + +The Organization MVC will contain the following functionality: + +- Instance setting to allow the creation of multiple Organizations. This will be enabled by default on GitLab.com, and disabled for self-managed GitLab. +- Every instance will have a default organization. Initially, all users will be managed by this default Organization. +- Organization Owner. The creation of an Organization appoints that user as the Organization Owner. Once established, the Organization Owner can appoint other Organization Owners. +- Organization users. A user is managed by one Organization, but can be part of multiple Organizations. +- Setup settings. Containing the Organization name, ID, description, README, and avatar. Settings are editable by the Organization Owner. +- Setup flow. Users are able to build an Organization on top of an existing top-level group. New users are able to create an Organization from scratch and to start building top-level groups from there. +- Visibility. Options will be `public` and `private`. A nonuser of a specific Organization will not see private Organizations in the explore section. Visibility is editable by the Organization Owner. +- Organization settings page with the added ability to remove an Organization. Deletion of the default Organization is prevented. +- Groups. This includes the ability to create, edit, and delete groups, as well as a Groups overview that can be accessed by the Organization Owner. +- Projects. This includes the ability to create, edit, and delete projects, as well as a Projects overview that can be accessed by the Organization Owner. + +### Organization Access + +#### Organization Users + +Organization Users can get access to groups and projects as: + +- A group member: this grants access to the group and all its projects, regardless of their visibility. +- A project member: this grants access to the project, and limited access to parent groups, regardless of their visibility. +- A non-member: this grants access to public and internal groups and projects of that Organization. To access a private group or project in an Organization, a user must become a member. + +Organization Users can be managed by the Organization as: + +- Enterprise Users, managed by the Organization. This includes control over their user account and the ability to block the user. +- Non-Enterprise Users, managed by the User. Non-Enterprise Users can be removed from an Organization, but their user account remains in their control. + +Enterprise Users are only available to Organizations with a Premium or Ultimate subscription. Organizations on the free tier will only be able to host Non-Enterprise Users. + +#### Organization Non-Users + +Non-users are external to the Organization and can only access the public resources of an Organization, such as public projects. + +## Iteration Plan + +The following iteration plan outlines how we intend to arrive at the Organization MVC. We are following the guidelines for [Experiment, Beta, and Generally Available features](../../../policy/alpha-beta-support.md). + +### Iteration 1: Organization Prototype (FY24Q2) + +In iteration 1, we introduce the concept of an Organization as a way to group top-level groups together. Support for Organizations does not require any [Cells](../cells/index.md) work, but having them will make all subsequent iterations of Cells simpler. The goal of iteration 1 will be to generate a prototype that can be used by GitLab teams to test moving functionality to the Organization. It contains everything that is necessary to move an Organization to a Cell: + +- The Organization can be named, has an ID and an avatar. +- Only non-enterprise user can be part of an Organization. +- A user can be part of multiple Organizations. +- A single Organization Owner can be assigned. +- Groups can be created in an Organization. Groups are listed in the Groups overview. +- Projects can be created in a Group. Projects are listed in the Projects overview. + +### Iteration 2: Organization MVC Experiment (FY24Q3) + +In iteration 2, an Organization MVC Experiment will be released. We will test the functionality with a select set of customers and improve the MVC based on these learnings. Users will be able to build an Organization on top of their existing top-level group. + +- The Organization has a description and a README. + +### Iteration 3: Organization MVC Beta (FY24Q4) + +In iteration 3, the Organization MVC Beta will be released. + +- Multiple Organization Owners can be assigned. +- Enterprise users can be added to an Organization. + +### Iteration 4: Organization MVC GA (FY25Q1) + +### Post-MVC Iterations + +After the initial rollout of Organizations, the following functionality will be added to address customer needs relating to their implementation of GitLab: + +1. Internal visibility will be made available on Organizations that are part of GitLab.com. +1. Move billing from top-level group to Organization. +1. Audit events at the Organization level. +1. Set merge request approval rules at the Organization level and cascade to all groups and projects. +1. Security policies at the Organization level. +1. Vulnerability reports at the Organization level. +1. Cascading Organization setting to enforce security scans. +1. Scan result policies at the Organization level. +1. Compliance frameworks. + +## Alternative Solutions + +An alternative approach to building Organizations is to convert top-level groups into Organizations. The main advantage of this approach is that features could be built on top of the namespace framework and therewith leverage functionality that is already available at the group level. We would avoid building the same feature multiple times. However, Organizations have been identified as a critical driver of Cells. Due to the urgency of delivering Cells, we decided to opt for the quickest and most straightforward solution to deliver an Organization, which is the lightweight design described above. More details on comparing the two Organization proposals can be found [here](https://gitlab.com/gitlab-org/tenant-scale-group/group-tasks/-/issues/56). + +## Decision Log + +- 2023-05-10: [Billing is not part of the Organization MVC](https://gitlab.com/gitlab-org/gitlab/-/issues/406614#note_1384055365) + +## Links + +- [Organization epic](https://gitlab.com/groups/gitlab-org/-/epics/9265) diff --git a/doc/architecture/blueprints/pods/images/iteration0-organizations-introduction.png b/doc/architecture/blueprints/pods/images/iteration0-organizations-introduction.png Binary files differdeleted file mode 100644 index 5725b0fa71f..00000000000 --- a/doc/architecture/blueprints/pods/images/iteration0-organizations-introduction.png +++ /dev/null diff --git a/doc/architecture/blueprints/pods/images/term-cluster.png b/doc/architecture/blueprints/pods/images/term-cluster.png Binary files differdeleted file mode 100644 index 87e4d631551..00000000000 --- a/doc/architecture/blueprints/pods/images/term-cluster.png +++ /dev/null diff --git a/doc/architecture/blueprints/pods/images/term-organization.png b/doc/architecture/blueprints/pods/images/term-organization.png Binary files differdeleted file mode 100644 index 4c82c62b8f4..00000000000 --- a/doc/architecture/blueprints/pods/images/term-organization.png +++ /dev/null diff --git a/doc/architecture/blueprints/pods/images/term-pod.png b/doc/architecture/blueprints/pods/images/term-pod.png Binary files differdeleted file mode 100644 index d8f79df2f29..00000000000 --- a/doc/architecture/blueprints/pods/images/term-pod.png +++ /dev/null diff --git a/doc/architecture/blueprints/pods/images/term-top-level-namespace.png b/doc/architecture/blueprints/pods/images/term-top-level-namespace.png Binary files differdeleted file mode 100644 index c1cd317d878..00000000000 --- a/doc/architecture/blueprints/pods/images/term-top-level-namespace.png +++ /dev/null diff --git a/doc/architecture/blueprints/pods/index.md b/doc/architecture/blueprints/pods/index.md index 077303be30f..5c15f880a54 100644 --- a/doc/architecture/blueprints/pods/index.md +++ b/doc/architecture/blueprints/pods/index.md @@ -1,356 +1,11 @@ --- -status: accepted -creation-date: "2022-09-07" -authors: [ "@ayufan", "@fzimmer", "@DylanGriffith" ] -coach: "@ayufan" -approvers: [ "@fzimmer" ] -owning-stage: "~devops::enablement" -participating-stages: [] +redirect_to: '../cells/index.md' +remove_date: '2023-06-13' --- -# Pods +This document was moved to [another location](../cells/index.md). -This document is a work-in-progress and represents a very early state of the Pods design. Significant aspects are not documented, though we expect to add them in the future. - -## Summary - -Pods is a new architecture for our Software as a Service platform that is horizontally-scalable, resilient, and provides a more consistent user experience. It may also provide additional features in the future, such as data residency control (regions) and federated features. - -## Terminology - -We use the following terms to describe components and properties of the Pods architecture. - -### Pod - -A Pod is a set of infrastructure components that contains multiple top-level namespaces that belong to different organizations. The components include both datastores (PostgreSQL, Redis etc.) and stateless services (web etc.). The infrastructure components provided within a Pod are shared among organizations and their top-level namespaces but not shared with other Pods. This isolation of infrastructure components means that Pods are independent from each other. - - - -#### Pod properties - -- Each pod is independent from the others -- Infrastructure components are shared by organizations and their top-level namespaces within a Pod -- More Pods can be provisioned to provide horizontal scalability -- A failing Pod does not lead to failure of other Pods -- Noisy neighbor effects are limited to within a Pod -- Pods are not visible to organizations; it is an implementation detail -- Pods may be located in different geographical regions (for example, EU, US, JP, UK) - -Discouraged synonyms: GitLab instance, cluster, shard - -### Cluster - -A cluster is a collection of Pods. - - - -#### Cluster properties - -- A cluster holds cluster-wide metadata, for example Users, Routes, Settings. - -Discouraged synonyms: whale - -### Organizations - -GitLab references [Organizations in the initial set up](../../../topics/set_up_organization.md) and users can add a (free text) organization to their profile. There is no Organization entity established in the GitLab codebase. - -As part of delivering Pods, we propose the introduction of an `organization` entity. Organizations would represent billable entities or customers. - -Organizations are a known concept, present for example in [AWS](https://docs.aws.amazon.com/whitepapers/latest/organizing-your-aws-environment/core-concepts.html) and [GCP](https://cloud.google.com/resource-manager/docs/cloud-platform-resource-hierarchy#organizations). - -Organizations work under the following assumptions: - -1. Users care about what happens within their organizations. -1. Features need to work within an organization. -1. Only few features need to work across organizations. -1. Users understand that the majority of pages they view are only scoped to a single organization at a time. -1. Organizations are located on a single pod. - - - -#### Organization properties - -- Top-level namespaces belong to organizations -- Users can be members of different organizations -- Organizations are isolated from each other by default meaning that cross-namespace features will only work for namespaces that exist within a single organization -- User namespaces must not belong to an organization - -Discouraged synonyms: Billable entities, customers - -### Top-Level namespace - -A top-level namespace is the logical object container in the code that represents all groups, subgroups and projects that belong to an organization. - -A top-level namespace is the root of nested collection namespaces and projects. The namespace and its related entities form a tree-like hierarchy: Namespaces are the nodes of the tree, projects are the leaves. - -Example: - -`https://gitlab.com/gitlab-org/gitlab/`: - -- `gitlab-org` is a `top-level namespace`; the root for all groups and projects of an organization -- `gitlab` is a `project`; a project of the organization. - -Top-level namespaces may [be replaced by workspaces](https://gitlab.com/gitlab-org/gitlab/-/issues/368237#high-level-goals). This proposal only uses the term top-level namespaces as the workspace definition is ongoing. - -Discouraged synonyms: Root-level namespace - - - -#### Top-level namespace properties - -- Top-level namespaces belonging to an organization are located on the same Pod -- Top-level namespaces can interact with other top-level namespaces that belong to the same organization - -### Users - -Users are available globally and not restricted to a single Pod. Users can be members of many different organizations with varying permissions. Inside organizations, users can create multiple top-level namespaces. User activity is not limited to a single organization but their contributions (for example TODOs) are only aggregated within an organization. This avoids the need for aggregating across pods. - -#### User properties - -- Users are shared globally across all Pods -- Users can create multiple top-level namespaces -- Users can be a member of multiple top-level namespaces -- Users can be a member of multiple organizations -- Users can administer organizations -- User activity is aggregated in an organization -- Every user has one personal namespace - -## Goals - -### Scalability - -The main goal of this new shared-infrastructure architecture is to provide additional scalability for our SaaS Platform. GitLab.com is largely monolithic and we have estimated (internal) that the current architecture has scalability limitations, even when database partitioning and decomposition are taken into account. - -Pods provide a horizontally scalable solution because additional Pods can be created based on demand. Pods can be provisioned and tuned as needed for optimal scalability. - -### Increased availability - -A major challenge for shared-infrastructure architectures is a lack of isolation between top-level namespaces. This can lead to noisy neighbor effects. A organization's behavior inside a top-level namespace can impact all other organizations. This is highly undesirable. Pods provide isolation at the pod level. A group of organizations is fully isolated from other organizations located on a different Pod. This minimizes noisy neighbor effects while still benefiting from the cost-efficiency of shared infrastructure. - -Additionally, Pods provide a way to implement disaster recovery capabilities. Entire Pods may be replicated to read-only standbys with automatic failover capabilities. - -### A consistent experience - -Organizations should have the same user experience on our SaaS platform as they do on a self-managed GitLab instance. - -### Regions - -GitLab.com is only hosted within the United States of America. Organizations located in other regions have voiced demand for local SaaS offerings. Pods provide a path towards [GitLab Regions](https://gitlab.com/groups/gitlab-org/-/epics/6037) because Pods may be deployed within different geographies. Depending on which of the organization's data is located outside a Pod, this may solve data residency and compliance problems. - -## Market segment - -Pods would provide a solution for organizations in the small to medium business (up to 100 users) and the mid-market segment (up to 2000 users). -(See [segmentation definitions](https://about.gitlab.com/handbook/sales/field-operations/gtm-resources/#segmentation).) -Larger organizations may benefit substantially from [GitLab Dedicated](../../../subscriptions/gitlab_dedicated/index.md). - -At this moment, GitLab.com has "social-network"-like capabilities that may not fit well into a more isolated organization model. Removing those features, however, possesses some challenges: - -1. How will existing `gitlab-org` contributors contribute to the namespace?? -1. How do we move existing top-level namespaces into the new model (effectively breaking their social features)? - -We should evaluate if the SMB and mid market segment is interested in these features, or if not having them is acceptable in most cases. - -### Self-managed - -For reasons of consistency, it is expected that self-managed instances will -adopt the pods architecture as well. To expand, self-managed instances can -continue with just a single Pod while supporting the option of adding additional -Pods. Organizations, and possible User decomposition will also be adopted for -self-managed instances. - -## High-level architecture problems to solve - -A number of technical issues need to be resolved to implement Pods (in no particular order). This section will be expanded. - -1. How are users of an organization routed to the correct Pod? -1. How do users authenticate? -1. How are Pods rebalanced? -1. How are Pods provisioned? -1. How can Pods implement disaster recovery capabilities? - -## Cross-section impact - -Pods is a fundamental architecture change that impacts other sections and stages. This section summarizes and links to other groups that may be impacted and highlights potential conflicts that need to be resolved. The Pods group is not responsible for achieving the goals of other groups but we want to ensure that dependencies are resolved. - -### Summary - -Based on discussions with other groups the net impact of introducing Pods and a new entity called organizations is mostly neutral. It may slow down development in some areas. We did not discover major blockers for other teams. - -1. We need to resolve naming conflicts (proposal is TBD) -1. Pods requires introducing Organizations. Organizations are a new entity **above** top-level groups. Because this is a new entity, it may impact the ability to consolidate settings for Group Workspace and influence their decision on [how to approach introducing a workspace](https://gitlab.com/gitlab-org/gitlab/-/issues/376285#approach-2-workspace-is-built-on-top-of-top-level-groups) -1. Organizations may make it slightly easier for Fulfillment to realize their billing plans. - -### Impact on Group Manage Workspace - -We synced with the Workspace PM and Designer ([recording](https://youtu.be/b5Opn9cFWFk)) and discussed the similarities and differences between the Pods and Workspace proposal ([presentation](https://docs.google.com/presentation/d/1FsUi22Up15b_tu6p2m-yLML3hCZ3rgrZrmzJAxUsNmU/edit?usp=sharing)). - -#### Goals of Group Manage Workspace - -As defined in the [workspace documentation](../../../user/workspace/index.md): - -1. Create an entity to manage everything you do as a GitLab administrator, including: - 1. Defining and applying settings to all of your groups, subgroups, and projects. - 1. Aggregating data from all your groups, subgroups, and projects. -1. Reach feature parity between SaaS and self-managed installations, with all Admin Area settings moving to groups (?). Hardware controls remain on the instance level. - -The [workspace roadmap outlines](https://gitlab.com/gitlab-org/gitlab/-/issues/368237#high-level-goals) the current goals in detail. - -#### Potential conflicts with Pods - -- Workspace and Organization are different terms for the same entity. Both define a new entity as the primary organizational object for groups and projects. This is mainly a semantic difference and **we need to decide on a name** following [user research to decide if workspace](https://gitlab.com/gitlab-org/ux-research/-/issues/2147). This is also driven by the fact that the Remote Development team is looking at better names and [are considering the term Workspace as well](https://gitlab.com/gitlab-com/Product/-/issues/4812). -- We will only introduce one entity -- Group workspace highlighted the need to further validate the key assumption that users only care about what happens within their organization. - -### Impact on Fulfillment - -We synced with Fulfillment ([recording](https://youtu.be/FkQF3uF7vTY)) to discuss how Pods would impact them. Fulfillment is supportive of an entity above top-level namespaces. Their perspective is outline in [!5639](https://gitlab.com/gitlab-org/customers-gitlab-com/-/merge_requests/5639/diffs). - -#### Goals of Fulfillment - -- Fulfillment has a longstanding plan to move billing from the top-level namespace to a level above. This would mean that a license applies for an organization and all its top-level namespaces. -- Fulfillment uses Zuora for billing and would like to have a 1-to-1 relationship between an organization and their Zuora entity called BillingAccount. They want to move away from tying a license to a single user. -- If a customer needs multiple organizations, the corresponding BillingAccounts can be rolled up into a consolidated billing account (similar to [AWS consolidated billing](https://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/consolidated-billing.html)) -- Ideally, a self-managed instance has a single Organization by default, which should be enough for most customers. -- Fulfillment prefers only one additional entity. - -A rough representation of this is: - - - -#### Potential conflicts with Pods - -- There are no known conflicts between Fulfillment's plans and Pods - -## Iteration plan - -We can't ship the entire Pods architecture in one go - it is too large. Instead, we are adopting an iteration plan that provides value along the way. - -1. Introduce organizations -1. Migrate existing top-level namespaces to organizations -1. Create new organizations on `pod_0` -1. Migrate existing organizations from `pod_0` to `pod_n` -1. Add additional Pod capabilities (DR, Regions) - -### Iteration 0: Introduce organizations - -In the first iteration, we introduce the concept of an organization -as a way to group top-level namespaces together. Support for organizations **does not require any Pods work** but having them will make all subsequent iterations of Pods simpler. This is mainly because we can group top-level namespaces for a single organization onto a Pod. Within an organization all interactions work as normal but we eliminate any cross-organizational interactions except in well defined cases (e.g. forking). - -This means that we don't have a large number of cross-pod interactions. - -Introducing organizations allows GitLab to move towards a multi-tenant system that is similar to Discord's with a single user account but many different "servers" - our organizations - that allow users to switch context. This model harmonizes the UX across self-managed and our SaaS Platforms and is a good fit for Pods. - -Organizations solve the following problems: - -1. We can group top-level namespaces by organization. It is very similar to the initial concept of "instance groups". For example these two top-level namespaces would belong to the organization `GitLab`: - 1. `https://gitlab.com/gitlab-org/` - 1. `https://gitlab.com/gitlab-com/` -1. We can isolate organizations from each other. Top-level namespaces of the same organization can interact within organizations but are not allowed to interact with other namespaces in other organizations. This is useful for customers because it means an organization provides clear boundaries - similar to a self-managed instance. This means we don't have to aggregate user dashboards across everything and can locally scope them to organizations. -1. We don't need to define hierarchies inside an organization. It is a container that could be filled with whatever hierarchy / entity set makes sense (workspaces, top-level namespaces etc.) -1. Self-managed instances would set a default organization. -1. Organizations can control user-profiles in a central way. This could be achieved by having an organization specific user-profile. Such a profile makes it possible for the organization administrators to control the user role in a company, enforce user emails, or show a graphical indicator of a user being part of the organization. An example would be a "GitLab Employee stamp" on comments. - - - -#### Why would customers opt-in to Organizations? - -By introducing organizations and Pods we can improve the reliability, performance and availability of our SaaS Platforms. - -The first iteration of organizations would also have some benefits by providing more isolation. A simple example would be that `@` mentions could be scoped to an organization. - -Future iterations would create additional value but are beyond the scope of this blueprint. - -Organizations will likely be required in the future as well. - -#### Initial user experience - -1. We create a default `GitLab.com public` organization and assign all public top-level namespaces to it. This allows existing users to access all the data on GitLab.com, exactly as it does now. -1. Any user wanting to opt-in to the benefits of organizations will need to set a single default organization. Any attempts for these users to load a global page like `/dashboard` will end up redirecting to `/-/organizations/<DEFAULT_ORGANIZATION>/dashboard`. -1. New users that opted in to organizations will only ever see data that is related to a single organization. Upon login, data is shown for the default organization. It will be clear to the user how they can switch to a different organization. Users can still navigate to the `GitLab.com` organization but they won't see TODOs from their new organizations in any such views. Instead they'd need to navigate directly to `/organizations/my-company/-/dashboard`. - -### Migrating to Organizations - -Existing customers could also opt-in to migrate their existing top-level paid namespaces to become part of an organization. In most cases this will be a 1-to-1 mapping. But in some cases it may allow a customer to move multiple top-level namespaces into one organization (for example GitLab). - -Migrating to Organizations would be optional. We could even recruit a few beta testers early on to see if this works for them. GitLab itself could dogfood organizations and we'd surface a lot of issues restricting interactions with other namespaces. - -## Iteration 1 - Introduce Pod US 0 - -### GitLab.com as Pod US0 - -GitLab.com will be treated as the first pod `Pod US 0`. It will be unique and much larger compared to newly created pods. All existing top-level namespaces and organizations will remain on `Pod US 0` in the first iteration. - -### Users are globally available - -Users are globally available and the same for all pods. This means that user data needs to be handled separately, for example via decomposition, see [!95941](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/95941). - -### Pod groundwork - -In this iteration, we'll lay all the groundwork to support a second Pod for new organizations. This will be transparent to customers. - -## Iteration 2 - Introduce Pod US 1 - -### Add new organizations to Pod US 1 - -After we are ready to support a second Pod, newly created organizations are located by default on `Pod US 1`. The user experience for organizations is already well established. - -### Migrate existing organizations from Pod US 0 to Pod US 1 - -We know that we'll have to move organizations from `Pod US 0` to other pods to reduce its size and ultimately retire the existing GitLab.com architecture. - -By introducing organizations early, we should be able to draw strong "boundaries" across organizations and support migrating existing organizations to a new Pod. - -This is likely going to be GitLab itself - if we can dogfood this, we are likely going to be successful with other organizations as well. - -## Iteration 3 - Introduce Regions - -We can now leverage the Pods architecture to introduce Regions. - -## Iteration 4 - Introduce cross-organizational interactions as needed - -Based on user research, we may want to change certain features to work across organizations. Examples include: - -- Specific features allow for cross-organization interactions, for example forking, search. - -## Technical Proposals - -The Pods architecture do have long lasting implications to data processing, location, scalability and the GitLab architecture. -This section links all different technical proposals that are being evaluated. - -- [Stateless Router That Uses a Cache to Pick Pod and Is Redirected When Wrong Pod Is Reached](proposal-stateless-router-with-buffering-requests.md) - -- [Stateless Router That Uses a Cache to Pick Pod and pre-flight `/api/v4/pods/learn`](proposal-stateless-router-with-routes-learning.md) - -## Impacted features - -The Pods architecture will impact many features requiring some of them to be rewritten, or changed significantly. -This is the list of known affected features with the proposed solutions. - -- [Pods: Git Access](pods-feature-git-access.md) -- [Pods: Data Migration](pods-feature-data-migration.md) -- [Pods: Database Sequences](pods-feature-database-sequences.md) -- [Pods: GraphQL](pods-feature-graphql.md) -- [Pods: Organizations](pods-feature-organizations.md) -- [Pods: Router Endpoints Classification](pods-feature-router-endpoints-classification.md) -- [Pods: Schema changes (Postgres and Elasticsearch migrations)](pods-feature-schema-changes.md) -- [Pods: Backups](pods-feature-backups.md) -- [Pods: Global Search](pods-feature-global-search.md) -- [Pods: CI Runners](pods-feature-ci-runners.md) -- [Pods: Admin Area](pods-feature-admin-area.md) -- [Pods: Secrets](pods-feature-secrets.md) -- [Pods: Container Registry](pods-feature-container-registry.md) -- [Pods: Contributions: Forks](pods-feature-contributions-forks.md) -- [Pods: Personal Namespaces](pods-feature-personal-namespaces.md) -- [Pods: Dashboard: Projects, Todos, Issues, Merge Requests, Activity, ...](pods-feature-dashboard.md) -- [Pods: Snippets](pods-feature-snippets.md) -- [Pods: Uploads](pods-feature-uploads.md) -- [Pods: GitLab Pages](pods-feature-gitlab-pages.md) -- [Pods: Agent for Kubernetes](pods-feature-agent-for-kubernetes.md) - -## Links - -- [Internal Pods presentation](https://docs.google.com/presentation/d/1x1uIiN8FR9fhL7pzFh9juHOVcSxEY7d2_q4uiKKGD44/edit#slide=id.ge7acbdc97a_0_155) -- [Pods Epic](https://gitlab.com/groups/gitlab-org/-/epics/7582) -- [Database Group investigation](https://about.gitlab.com/handbook/engineering/development/enablement/data_stores/database/doc/root-namespace-sharding.html) -- [Shopify Pods architecture](https://shopify.engineering/a-pods-architecture-to-allow-shopify-to-scale) -- [Opstrace architecture](https://gitlab.com/gitlab-org/opstrace/opstrace/-/blob/main/docs/architecture/overview.md) +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-admin-area.md b/doc/architecture/blueprints/pods/pods-feature-admin-area.md index 7efaa383510..0f02a4a88ba 100644 --- a/doc/architecture/blueprints/pods/pods-feature-admin-area.md +++ b/doc/architecture/blueprints/pods/pods-feature-admin-area.md @@ -1,58 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Admin Area' +redirect_to: '../cells/cells-feature-admin-area.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/cells-feature-admin-area.md). -# Pods: Admin Area - -In our Pods architecture proposal we plan to share all admin related tables in -GitLab. This allows simpler management of all Pods in one interface and reduces -the risk of settings diverging in different Pods. This introduces challenges -with admin pages that allow you to manage data that will be spread across all -Pods. - -## 1. Definition - -There are consequences for admin pages that contain data that spans "the whole -instance" as the Admin pages may be served by any Pod or possibly just 1 pod. -There are already many parts of the Admin interface that will have data that -spans many pods. For example lists of all Groups, Projects, Topics, Jobs, -Analytics, Applications and more. There are also administrative monitoring -capabilities in the Admin page that will span many pods such as the "Background -Jobs" and "Background Migrations" pages. - -## 2. Data flow - -## 3. Proposal - -We will need to decide how to handle these exceptions with a few possible -options: - -1. Move all these pages out into a dedicated per-pod Admin section. Probably - the URL will need to be routable to a single Pod like `/pods/<pod_id>/admin`, - then we can display this data per Pod. These pages will be distinct from - other Admin pages which control settings that are shared across all Pods. We - will also need to consider how this impacts self-managed customers and - whether, or not, this should be visible for single-pod instances of GitLab. -1. Build some aggregation interfaces for this data so that it can be fetched - from all Pods and presented in a single UI. This may be beneficial to an - administrator that needs to see and filter all data at a glance, especially - when they don't know which Pod the data is on. The downside, however, is - that building this kind of aggregation is very tricky when all the Pods are - designed to be totally independent, and it does also enforce more strict - requirements on compatibility between Pods. - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-agent-for-kubernetes.md b/doc/architecture/blueprints/pods/pods-feature-agent-for-kubernetes.md index f390c751b8b..f28cc447e0a 100644 --- a/doc/architecture/blueprints/pods/pods-feature-agent-for-kubernetes.md +++ b/doc/architecture/blueprints/pods/pods-feature-agent-for-kubernetes.md @@ -1,29 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Agent for Kubernetes' +redirect_to: '../cells/cells-feature-agent-for-kubernetes.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/cells-feature-agent-for-kubernetes.md). -# Pods: Agent for Kubernetes - -> TL;DR - -## 1. Definition - -## 2. Data flow - -## 3. Proposal - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-backups.md b/doc/architecture/blueprints/pods/pods-feature-backups.md index 5e4de42f473..db22317cf75 100644 --- a/doc/architecture/blueprints/pods/pods-feature-backups.md +++ b/doc/architecture/blueprints/pods/pods-feature-backups.md @@ -1,61 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Backups' +redirect_to: '../cells/cells-feature-backups.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/cells-feature-backups.md). -# Pods: Backups - -Each pods will take its own backups, and consequently have its own isolated -backup / restore procedure. - -## 1. Definition - -GitLab Backup takes a backup of the PostgreSQL database used by the application, -and also Git repository data. - -## 2. Data flow - -Each pod has a number of application databases to back up (e.g. `main`, and `ci`). - -Additionally, there may be cluster-wide metadata tables (e.g. `users` table) -which is directly accesible via PostgreSQL. - -## 3. Proposal - -### 3.1. Cluster-wide metadata - -It is currently unknown how cluster-wide metadata tables will be accessible. We -may choose to have cluster-wide metadata tables backed up separately, or have -each pod back up its copy of cluster-wide metdata tables. - -### 3.2 Consistency - -#### 3.2.1 Take backups independently - -As each pod will communicate with each other via API, and there will be no joins -to the users table, it should be acceptable for each pod to take a backup -independently of each other. - -#### 3.2.2 Enforce snapshots - -We can require that each pod take a snapshot for the PostgreSQL databases at -around the same time to allow for a consistent-enough backup. - -## 4. Evaluation - -As the number of pods increases, it will likely not be feasible to take a -snapshot at the same time for all pods. Hence taking backups independently is -the better option. - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-ci-runners.md b/doc/architecture/blueprints/pods/pods-feature-ci-runners.md index b75515a916f..1985bb21884 100644 --- a/doc/architecture/blueprints/pods/pods-feature-ci-runners.md +++ b/doc/architecture/blueprints/pods/pods-feature-ci-runners.md @@ -1,169 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: CI Runners' +redirect_to: '../cells/cells-feature-ci-runners.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/cells-feature-ci-runners.md). -# Pods: CI Runners - -GitLab in order to execute CI jobs [GitLab Runner](https://gitlab.com/gitlab-org/gitlab-runner/), -very often managed by customer in their infrastructure. - -All CI jobs created as part of CI pipeline are run in a context of project -it poses a challenge how to manage GitLab Runners. - -## 1. Definition - -There are 3 different types of runners: - -- instance-wide: runners that are registered globally with specific tags (selection criteria) -- group runners: runners that execute jobs from a given top-level group or subprojects of that group -- project runners: runners that execute jobs from projects or many projects: some runners might - have projects assigned from projects in different top-level groups. - -This alongside with existing data structure where `ci_runners` is a table describing -all types of runners poses a challenge how the `ci_runners` should be managed in a Pods environment. - -## 2. Data flow - -GitLab Runners use a set of globally scoped endpoints to: - -- registration of a new runner via registration token `https://gitlab.com/api/v4/runners` - ([subject for removal](../runner_tokens/index.md)) (`registration token`) -- requests jobs via an authenticated `https://gitlab.com/api/v4/jobs/request` endpoint (`runner token`) -- upload job status via `https://gitlab.com/api/v4/jobs/:job_id` (`build token`) -- upload trace via `https://gitlab.com/api/v4/jobs/:job_id/trace` (`build token`) -- download and upload artifacts via `https://gitlab.com/api/v4/jobs/:job_id/artifacts` (`build token`) - -Currently three types of authentication tokens are used: - -- runner registration token ([subject for removal](../runner_tokens/index.md)) -- runner token representing an registered runner in a system with specific configuration (`tags`, `locked`, etc.) -- build token representing an ephemeral token giving a limited access to updating a specific - job, uploading artifacts, downloading dependent artifacts, downloading and uploading - container registry images - -Each of those endpoints do receive an authentication token via header (`JOB-TOKEN` for `/trace`) -or body parameter (`token` all other endpoints). - -Since the CI pipeline would be created in a context of a specific Pod it would be required -that pick of a build would have to be processed by that particular Pod. This requires -that build picking depending on a solution would have to be either: - -- routed to correct Pod for a first time -- be made to be two phase: request build from global pool, claim build on a specific Pod using a Pod specific URL - -## 3. Proposal - -This section describes various proposals. Reader should consider that those -proposals do describe solutions for different problems. Many or some aspects -of those proposals might be the solution to the stated problem. - -### 3.1. Authentication tokens - -Even though the paths for CI Runners are not routable they can be made routable with -those two possible solutions: - -- The `https://gitlab.com/api/v4/jobs/request` uses a long polling mechanism with - a ticketing mechanism (based on `X-GitLab-Last-Update` header). Runner when first - starts sends a request to GitLab to which GitLab responds with either a build to pick - by runner. This value is completely controlled by GitLab. This allows GitLab - to use JWT or any other means to encode `pod` identifier that could be easily - decodable by Router. -- The majority of communication (in terms of volume) is using `build token` making it - the easiest target to change since GitLab is sole owner of the token that Runner later - uses for specific job. There were prior discussions about not storing `build token` - but rather using `JWT` token with defined scopes. Such token could encode the `pod` - to which router could easily route all requests. - -### 3.2. Request body - -- The most of used endpoints pass authentication token in request body. It might be desired - to use HTTP Headers as an easier way to access this information by Router without - a need to proxy requests. - -### 3.3. Instance-wide are Pod local - -We can pick a design where all runners are always registered and local to a given Pod: - -- Each Pod has it's own set of instance-wide runners that are updated at it's own pace -- The project runners can only be linked to projects from the same organization - creating strong isolation. -- In this model the `ci_runners` table is local to the Pod. -- In this model we would require the above endpoints to be scoped to a Pod in some way - or made routable. It might be via prefixing them, adding additional Pod parameter, - or providing much more robust way to decode runner token and match it to Pod. -- If routable token is used, we could move away from cryptographic random stored in - database to rather prefer to use JWT tokens that would encode -- The Admin Area showing registered Runners would have to be scoped to a Pod - -This model might be desired since it provides strong isolation guarantees. -This model does significantly increase maintenance overhead since each Pod is managed -separately. - -This model may require adjustments to runner tags feature so that projects have consistent runner experience across pods. - -### 3.4. Instance-wide are cluster-wide - -Contrary to proposal where all runners are Pod local, we can consider that runners -are global, or just instance-wide runners are global. - -However, this requires significant overhaul of system and to change the following aspects: - -- `ci_runners` table would likely have to be split decomposed into `ci_instance_runners`, ... -- all interfaces would have to be adopted to use correct table -- build queuing would have to be reworked to be two phase where each Pod would know of all pending - and running builds, but the actual claim of a build would happen against a Pod containing data -- likely `ci_pending_builds` and `ci_running_builds` would have to be made `cluster-wide` tables - increasing likelihood of creating hotspots in a system related to CI queueing - -This model makes it complex to implement from engineering side. Does make some data being shared -between Pods. Creates hotspots / scalability issues in a system (ex. during abuse) that -might impact experience of organizations on other Pods. - -### 3.5. GitLab CI Daemon - -Another potential solution to explore is to have a dedicated service responsible for builds queueing -owning it's database and working in a model of either sharded or podded service. There were prior -discussions about [CI/CD Daemon](https://gitlab.com/gitlab-org/gitlab/-/issues/19435). - -If the service would be sharded: - -- depending on a model if runners are cluster-wide or pod-local this service would have to fetch - data from all Pods -- if the sharded service would be used we could adapt a model of either sharing database containing - `ci_pending_builds/ci_running_builds` with the service -- if the sharded service would be used we could consider a push model where each Pod pushes to CI/CD Daemon - builds that should be picked by Runner -- the sharded service would be aware which Pod is responsible for processing the given build and could - route processing requests to designated Pod - -If the service would be podded: - -- all expectations of routable endpoints are still valid - -In general usage of CI Daemon does not help significantly with the stated problem. However, this offers -a few upsides related to more efficient processing and decoupling model: push model and it opens a way -to offer stateful communication with GitLab Runners (ex. gRPC or Websockets). - -## 4. Evaluation - -Considering all solutions it appears that solution giving the most promise is: - -- use "instance-wide are Pod local" -- refine endpoints to have routable identities (either via specific paths, or better tokens) - -Other potential upsides is to get rid of `ci_builds.token` and rather use a `JWT token` -that can much better and easier encode wider set of scopes allowed by CI runner. - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-container-registry.md b/doc/architecture/blueprints/pods/pods-feature-container-registry.md index d47913fbc2a..9d2bbb3febe 100644 --- a/doc/architecture/blueprints/pods/pods-feature-container-registry.md +++ b/doc/architecture/blueprints/pods/pods-feature-container-registry.md @@ -1,131 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Container Registry' +redirect_to: '../cells/cells-feature-container-registry.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/cells-feature-container-registry.md). -# Pods: Container Registry - -GitLab Container Registry is a feature allowing to store Docker Container Images -in GitLab. You can read about GitLab integration [here](../../../user/packages/container_registry/index.md). - -## 1. Definition - -GitLab Container Registry is a complex service requiring usage of PostgreSQL, Redis -and Object Storage dependencies. Right now there's undergoing work to introduce -[Container Registry Metadata](../container_registry_metadata_database/index.md) -to optimize data storage and image retention policies of Container Registry. - -GitLab Container Registry is serving as a container for stored data, -but on it's own does not authenticate `docker login`. The `docker login` -is executed with user credentials (can be `personal access token`) -or CI build credentials (ephemeral `ci_builds.token`). - -Container Registry uses data deduplication. It means that the same blob -(image layer) that is shared between many projects is stored only once. -Each layer is hashed by `sha256`. - -The `docker login` does request JWT time-limited authentication token that -is signed by GitLab, but validated by Container Registry service. The JWT -token does store all authorized scopes (`container repository images`) -and operation types (`push` or `pull`). A single JWT authentication token -can be have many authorized scopes. This allows container registry and client -to mount existing blobs from another scopes. GitLab responds only with -authorized scopes. Then it is up to GitLab Container Registry to validate -if the given operation can be performed. - -The GitLab.com pages are always scoped to project. Each project can have many -container registry images attached. - -Currently in case of GitLab.com the actual registry service is served -via `https://registry.gitlab.com`. - -The main identifiable problems are: - -- the authentication request (`https://gitlab.com/jwt/auth`) that is processed by GitLab.com -- the `https://registry.gitlab.com` that is run by external service and uses it's own data store -- the data deduplication, the Pods architecture with registry run in a Pod would reduce - efficiency of data storage - -## 2. Data flow - -### 2.1. Authorization request that is send by `docker login` - -```shell -curl \ - --user "username:password" \ - "https://gitlab/jwt/auth?client_id=docker&offline_token=true&service=container_registry&scope=repository:gitlab-org/gitlab-build-images:push,pull" -``` - -Result is encoded and signed JWT token. Second base64 encoded string (split by `.`) contains JSON with authorized scopes. - -```json -{"auth_type":"none","access":[{"type":"repository","name":"gitlab-org/gitlab-build-images","actions":["pull"]}],"jti":"61ca2459-091c-4496-a3cf-01bac51d4dc8","aud":"container_registry","iss":"omnibus-gitlab-issuer","iat":1669309469,"nbf":166} -``` - -### 2.2. Docker client fetching tags - -```shell -curl \ - -H "Accept: application/vnd.docker.distribution.manifest.v2+json" \ - -H "Authorization: Bearer token" \ - https://registry.gitlab.com/v2/gitlab-org/gitlab-build-images/tags/list - -curl \ - -H "Accept: application/vnd.docker.distribution.manifest.v2+json" \ - -H "Authorization: Bearer token" \ - https://registry.gitlab.com/v2/gitlab-org/gitlab-build-images/manifests/danger-ruby-2.6.6 -``` - -### 2.3. Docker client fetching blobs and manifests - -```shell -curl \ - -H "Accept: application/vnd.docker.distribution.manifest.v2+json" \ - -H "Authorization: Bearer token" \ - https://registry.gitlab.com/v2/gitlab-org/gitlab-build-images/blobs/sha256:a3f2e1afa377d20897e08a85cae089393daa0ec019feab3851d592248674b416 -``` - -## 3. Proposal - -### 3.1. Shard Container Registry separately to Pods architecture - -Due to it's architecture it extensive architecture and in general highly scalable -horizontal architecture it should be evaluated if the GitLab Container Registry -should be run not in Pod, but in a Cluster and be scaled independently. - -This might be easier, but would definitely not offer the same amount of data isolation. - -### 3.2. Run Container Registry within a Pod - -It appears that except `/jwt/auth` which would likely have to be processed by Router -(to decode `scope`) the container registry could be run as a local service of a Pod. - -The actual data at least in case of GitLab.com is not forwarded via registry, -but rather served directly from Object Storage / CDN. - -Its design encodes container repository image in a URL that is easily routable. -It appears that we could re-use the same stateless Router service in front of Container Registry -to serve manifests and blobs redirect. - -The only downside is increased complexity of managing standalone registry for each Pod, -but this might be desired approach. - -## 4. Evaluation - -There do not seem any theoretical problems with running GitLab Container Registry in a Pod. -Service seems that can be easily made routable to work well. - -The practical complexities are around managing complex service from infrastructure side. - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-contributions-forks.md b/doc/architecture/blueprints/pods/pods-feature-contributions-forks.md index 566ae50ec49..38bdef35329 100644 --- a/doc/architecture/blueprints/pods/pods-feature-contributions-forks.md +++ b/doc/architecture/blueprints/pods/pods-feature-contributions-forks.md @@ -1,120 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Contributions: Forks' +redirect_to: '../cells/cells-feature-contributions-forks.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/cells-feature-contributions-forks.md). -# Pods: Contributions: Forks - -[Forking workflow](../../../user/project/repository/forking_workflow.md) allows users -to copy existing project sources into their own namespace of choice (personal or group). - -## 1. Definition - -[Forking workflow](../../../user/project/repository/forking_workflow.md) is common workflow -with various usage patterns: - -- allows users to contribute back to upstream project -- persist repositories into their personal namespace -- copy to make changes and release as modified project - -Forks allow users not having write access to parent project to make changes. The forking workflow -is especially important for the Open Source community which is able to contribute back -to public projects. However, it is equally important in some companies which prefer the strong split -of responsibilites and tighter access control. The access to project is restricted -to designated list of developers. - -Forks enable: - -- tigther control of who can modify the upstream project -- split of the responsibilites: parent project might use CI configuration connecting to production systems -- run CI pipelines in context of fork in much more restrictive environment -- consider all forks to be unveted which reduces risks of leaking secrets, or any other information - tied with the project - -The forking model is problematic in Pods architecture for following reasons: - -- Forks are clones of existing repositories, forks could be created across different organizations, Pods and Gitaly shards. -- User can create merge request and contribute back to upstream project, this upstream project might in a different organization and Pod. -- The merge request CI pipeline is to executed in a context of source project, but presented in a context of target project. - -## 2. Data flow - -## 3. Proposals - -### 3.1. Intra-Cluster forks - -This proposal makes us to implement forks as a intra-ClusterPod forks where communication is done via API -between all trusted Pods of a cluster: - -- Forks when created, they are created always in context of user choice of group. -- Forks are isolated from Organization. -- Organization or group owner could disable forking across organizations or forking in general. -- When a Merge Request is created it is created in context of target project, referencing - external project on another Pod. -- To target project the merge reference is transfered that is used for presenting information - in context of target project. -- CI pipeline is fetched in context of source project as it-is today, the result is fetched into - Merge Request of target project. -- The Pod holding target project internally uses GraphQL to fetch status of source project - and include in context of the information for merge request. - -Upsides: - -- All existing forks continue to work as-is, as they are treated as intra-Cluster forks. - -Downsides: - -- The purpose of Organizations is to provide strong isolation between organizations - allowing to fork across does break security boundaries. -- However, this is no different to ability of users today to clone repository to local computer - and push it to any repository of choice. -- Access control of source project can be lower than those of target project. System today - requires that in order to contribute back the access level needs to be the same for fork and upstream. - -### 3.2. Forks are created in a personal namespace of the current organization - -Instead of creating projects across organizations, the forks are created in a user personal namespace -tied with the organization. Example: - -- Each user that is part of organization receives their personal namespace. For example for `GitLab Inc.` - it could be `gitlab.com/organization/gitlab-inc/@ayufan`. -- The user has to fork into it's own personal namespace of the organization. -- The user has that many personal namespaces as many organizations it belongs to. -- The personal namespace behaves similar to currently offered personal namespace. -- The user can manage and create projects within a personal namespace. -- The organization can prevent or disable usage of personal namespaces disallowing forks. -- All current forks are migrated into personal namespace of user in Organization. -- All forks are part of to the organization. -- The forks are not federated features. -- The personal namespace and forked project do not share configuration with parent project. - -### 3.3. Forks are created as internal projects under current project - -Instead of creating projects across organizations, the forks are attachments to existing projects. -Each user forking a project receives their unique project. Example: - -- For project: `gitlab.com/gitlab-org/gitlab`, forks would be created in `gitlab.com/gitlab-org/gitlab/@kamil-gitlab`. -- Forks are created in a context of current organization, they do not cross organization boundaries - and are managed by the organization. -- Tied to the user (or any other user-provided name of the fork). -- The forks are not federated features. - -Downsides: - -- Does not answer how to handle and migrate all exisiting forks. -- Might share current group / project settings - breaking some security boundaries. - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-dashboard.md b/doc/architecture/blueprints/pods/pods-feature-dashboard.md index e63d912b4c9..1d92b891aff 100644 --- a/doc/architecture/blueprints/pods/pods-feature-dashboard.md +++ b/doc/architecture/blueprints/pods/pods-feature-dashboard.md @@ -1,29 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Dashboard' +redirect_to: '../cells/cells-feature-dashboard.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/cells-feature-dashboard.md). -# Pods: Dashboard - -> TL;DR - -## 1. Definition - -## 2. Data flow - -## 3. Proposal - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-data-migration.md b/doc/architecture/blueprints/pods/pods-feature-data-migration.md index fbe97316dcc..c06006a86dc 100644 --- a/doc/architecture/blueprints/pods/pods-feature-data-migration.md +++ b/doc/architecture/blueprints/pods/pods-feature-data-migration.md @@ -1,130 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Data migration' +redirect_to: '../cells/cells-feature-data-migration.md' +remove_date: '2023-06-13' --- -DISCLAIMER: -This page may contain information related to upcoming products, features and -functionality. It is important to note that the information presented is for -informational purposes only, so please do not rely on the information for -purchasing or planning purposes. Just like with all projects, the items -mentioned on the page are subject to change or delay, and the development, -release, and timing of any products, features, or functionality remain at the -sole discretion of GitLab Inc. +This document was moved to [another location](../cells/cells-feature-data-migration.md). -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. - -# Pods: Data migration - -It is essential for Pods architecture to provide a way to migrate data out of big Pods -into smaller ones. This describes various approaches to provide this type of split. - -We also need to handle for cases where data is already violating the expected -isolation constraints of Pods (ie. references cannot span multiple -organizations). We know that existing features like linked issues allowed users -to link issues across any projects regardless of their hierarchy. There are many -similar features. All of this data will need to be migrated in some way before -it can be split across different pods. This may mean some data needs to be -deleted, or the feature changed and modelled slightly differently before we can -properly split or migrate the organizations between pods. - -Having schema deviations across different Pods, which is a necessary -consequence of different databases, will also impact our ability to migrate -data between pods. Different schemas impact our ability to reliably replicate -data across pods and especially impact our ability to validate that the data is -correctly replicated. It might force us to only be able to move data between -pods when the schemas are all in sync (slowing down deployments and the -rebalancing process) or possibly only migrate from newer to older schemas which -would be complex. - -## 1. Definition - -## 2. Data flow - -## 3. Proposal - -### 3.1. Split large Pods - -A single Pod can only be divided into many Pods. This is based on principle -that it is easier to create exact clone of an existing Pod in many replicas -out of which some will be made authoritative once migrated. Keeping those -replicas up-to date with Pod 0 is also much easier due to pre-existing -replication solutions that can replicate the whole systems: Geo, PostgreSQL -physical replication, etc. - -1. All data of an organization needs to not be divided across many Pods. -1. Split should be doable online. -1. New Pods cannot contain pre-existing data. -1. N Pods contain exact replica of Pod 0. -1. The data of Pod 0 is live replicated to as many Pods it needs to be split. -1. Once consensus is achieved between Pod 0 and N-Pods the organizations to be migrated away - are marked as read-only cluster-wide. -1. The `routes` is updated on for all organizations to be split to indicate an authoritative - Pod holding the most recent data, like `gitlab-org` on `pod-100`. -1. The data for `gitlab-org` on Pod 0, and on other non-authoritative N-Pods are dormant - and will be removed in the future. -1. All accesses to `gitlab-org` on a given Pod are validated about `pod_id` of `routes` - to ensure that given Pod is authoritative to handle the data. - -#### More challenges of this proposal - -1. There is no streaming replication capability for Elasticsearch, but you could - snapshot the whole Elasticsearch index and recreate, but this takes hours. - It could be handled by pausing Elasticsearch indexing on the initial pod during - the migration as indexing downtime is not a big issue, but this still needs - to be coordinated with the migration process -1. Syncing Redis, Gitaly, CI Postgres, Main Postgres, registry Postgres, other - new data stores snapshots in an online system would likely lead to gaps - without a long downtime. You need to choose a sync point and at the sync - point you need to stop writes to perform the migration. The more data stores - there are to migrate at the same time the longer the write downtime for the - failover. We would also need to find a reliable place in the application to - actually block updates to all these systems with a high degree of - confidence. In the past we've only been confident by shutting down all rails - services because any rails process could write directly to any of these at - any time due to async workloads or other surprising code paths. -1. How to efficiently delete all the orphaned data. Locating all `ci_builds` - associated with half the organizations would be very expensive if we have to - do joins. We haven't yet determined if we'd want to store an `organization_id` - column on every table, but this is the kind of thing it would be helpful for. - -### 3.2. Migrate organization from an existing Pod - -This is different to split, as we intend to perform logical and selective replication -of data belonging to a single organization. - -Today this type of selective replication is only implemented by Gitaly where we can migrate -Git repository from a single Gitaly node to another with minimal downtime. - -In this model we would require identifying all resources belonging to a given organization: -database rows, object storage files, Git repositories, etc. and selectively copy them over -to another (likely) existing Pod importing data into it. Ideally ensuring that we can -perform logical replication live of all changed data, but change similarly to split -which Pod is authoritative for this organization. - -1. It is hard to identify all resources belonging to organization. -1. It requires either downtime for organization or a robust system to identify - live changes made. -1. It likely will require a full database structure analysis (more robust than project import/export) - to perform selective PostgreSQL logical replication. - -#### More challenges of this proposal - -1. Logical replication is still not performant enough to keep up with our - scale. Even if we could use logical replication we still don't have an - efficient way to filter data related to a single organization without - joining all the way to the `organizations` table which will slow down - logical replication dramatically. - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-database-sequences.md b/doc/architecture/blueprints/pods/pods-feature-database-sequences.md index 0a8bb4d250e..9c4d6c5e290 100644 --- a/doc/architecture/blueprints/pods/pods-feature-database-sequences.md +++ b/doc/architecture/blueprints/pods/pods-feature-database-sequences.md @@ -1,94 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Database Sequences' +redirect_to: '../cells/cells-feature-database-sequences.md' +remove_date: '2023-06-13' --- -DISCLAIMER: -This page may contain information related to upcoming products, features and -functionality. It is important to note that the information presented is for -informational purposes only, so please do not rely on the information for -purchasing or planning purposes. Just like with all projects, the items -mentioned on the page are subject to change or delay, and the development, -release, and timing of any products, features, or functionality remain at the -sole discretion of GitLab Inc. +This document was moved to [another location](../cells/cells-feature-database-sequences.md). -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. - -# Pods: Database Sequences - -GitLab today ensures that every database row create has unique ID, allowing -to access Merge Request, CI Job or Project by a known global ID. - -Pods will use many distinct and not connected databases, each of them having -a separate IDs for most of entities. - -It might be desirable to retain globally unique IDs for all database rows -to allow migrating resources between Pods in the future. - -## 1. Definition - -## 2. Data flow - -## 3. Proposal - -This are some preliminary ideas how we can retain unique IDs across the system. - -### 3.1. UUID - -Instead of using incremental sequences use UUID (128 bit) that is stored in database. - -- This might break existing IDs and requires adding UUID column for all existing tables. -- This makes all indexes larger as it requires storing 128 bit instead of 32/64 bit in index. - -### 3.2. Use Pod index encoded in ID - -Since significant number of tables already use 64 bit ID numbers we could use MSB to encode -Pod ID effectively enabling - -- This might limit amount of Pods that can be enabled in system, as we might decide to only - allocate 1024 possible Pod numbers. -- This might make IDs to be migratable between Pods, since even if entity from Pod 1 is migrated to Pod 100 - this ID would still be unique. -- If resources are migrated the ID itself will not be enough to decode Pod number and we would need - lookup table. -- This requires updating all IDs to 32 bits. - -### 3.3. Allocate sequence ranges from central place - -Each Pod might receive its own range of the sequences as they are consumed from a centrally managed place. -Once Pod consumes all IDs assigned for a given table it would be replenished and a next range would be allocated. -Ranges would be tracked to provide a faster lookup table if a random access pattern is required. - -- This might make IDs to be migratable between Pods, since even if entity from Pod 1 is migrated to Pod 100 - this ID would still be unique. -- If resources are migrated the ID itself will not be enough to decode Pod number and we would need - much more robust lookup table as we could be breaking previously assigned sequence ranges. -- This does not require updating all IDs to 64 bits. -- This adds some performance penalty to all `INSERT` statements in Postgres or at least from Rails as we need to check for the sequence number and potentially wait for our range to be refreshed from the ID server -- The available range will need to be stored and incremented in a centralized place so that concurrent transactions cannot possibly get the same value. - -### 3.4. Define only some tables to require unique IDs - -Maybe this is acceptable only for some tables to have a globally unique IDs. It could be projects, groups -and other top-level entities. All other tables like `merge_requests` would only offer Pod-local ID, -but when referenced outside it would rather use IID (an ID that is monotonic in context of a given resource, like project). - -- This makes the ID 10000 for `merge_requests` be present on all Pods, which might be sometimes confusing - as for uniqueness of the resource. -- This might make random access by ID (if ever needed) be impossible without using composite key, like: `project_id+merge_request_id`. -- This would require us to implement a transformation/generation of new ID if we need to migrate records to another pod. This can lead to very difficult migration processes when these IDs are also used as foreign keys for other records being migrated. -- If IDs need to change when moving between pods this means that any links to records by ID would no longer work even if those links included the `project_id`. -- If we plan to allow these ids to not be unique and change the unique constraint to be based on a composite key then we'd need to update all foreign key references to be based on the composite key - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-git-access.md b/doc/architecture/blueprints/pods/pods-feature-git-access.md index 9bda2d1de9c..1a0df0f9569 100644 --- a/doc/architecture/blueprints/pods/pods-feature-git-access.md +++ b/doc/architecture/blueprints/pods/pods-feature-git-access.md @@ -1,163 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Git Access' +redirect_to: '../cells/cells-feature-git-access.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/cells-feature-git-access.md). -# Pods: Git Access - -This document describes impact of Pods architecture on all Git access (over HTTPS and SSH) -patterns providing explanation of how potentially those features should be changed -to work well with Pods. - -## 1. Definition - -Git access is done through out the application. It can be an operation performed by the system -(read Git repository) or by user (create a new file via Web IDE, `git clone` or `git push` via command line). - -The Pods architecture defines that all Git repositories will be local to the Pod, -so no repository could be shared with another Pod. - -The Pods architecture will require that any Git operation done can only be handled by a Pod holding -the data. It means that any operation either via Web interface, API, or GraphQL needs to be routed -to the correct Pod. It means that any `git clone` or `git push` operation can only be performed -in a context of a Pod. - -## 2. Data flow - -The are various operations performed today by the GitLab on a Git repository. This describes -the data flow how they behave today to better represent the impact. - -It appears that Git access does require changes only to a few endpoints that are scoped to project. -There appear to be different types of repositories: - -- Project: assigned to Group -- Wiki: additional repository assigned to Project -- Design: similar to Wiki, additional repository assigned to Project -- Snippet: creates a virtual project to hold repository, likely tied to the User - -### 2.1. Git clone over HTTPS - -Execution of: `git clone` over HTTPS - -```mermaid -sequenceDiagram - User ->> Workhorse: GET /gitlab-org/gitlab.git/info/refs?service=git-upload-pack - Workhorse ->> Rails: GET /gitlab-org/gitlab.git/info/refs?service=git-upload-pack - Rails ->> Workhorse: 200 OK - Workhorse ->> Gitaly: RPC InfoRefsUploadPack - Gitaly ->> User: Response - User ->> Workhorse: POST /gitlab-org/gitlab.git/git-upload-pack - Workhorse ->> Gitaly: RPC PostUploadPackWithSidechannel - Gitaly ->> User: Response -``` - -### 2.2. Git clone over SSH - -Execution of: `git clone` over SSH - -```mermaid -sequenceDiagram - User ->> Git SSHD: ssh git@gitlab.com - Git SSHD ->> Rails: GET /api/v4/internal/authorized_keys - Rails ->> Git SSHD: 200 OK (list of accepted SSH keys) - Git SSHD ->> User: Accept SSH - User ->> Git SSHD: git clone over SSH - Git SSHD ->> Rails: POST /api/v4/internal/allowed?project=/gitlab-org/gitlab.git&service=git-upload-pack - Rails ->> Git SSHD: 200 OK - Git SSHD ->> Gitaly: RPC SSHUploadPackWithSidechannel - Gitaly ->> User: Response -``` - -### 2.3. Git push over HTTPS - -Execution of: `git push` over HTTPS - -```mermaid -sequenceDiagram - User ->> Workhorse: GET /gitlab-org/gitlab.git/info/refs?service=git-receive-pack - Workhorse ->> Rails: GET /gitlab-org/gitlab.git/info/refs?service=git-receive-pack - Rails ->> Workhorse: 200 OK - Workhorse ->> Gitaly: RPC PostReceivePack - Gitaly ->> Rails: POST /api/v4/internal/allowed?gl_repository=project-111&service=git-receive-pack - Gitaly ->> Rails: POST /api/v4/internal/pre_receive?gl_repository=project-111 - Gitaly ->> Rails: POST /api/v4/internal/post_receive?gl_repository=project-111 - Gitaly ->> User: Response -``` - -### 2.4. Git push over SSHD - -Execution of: `git clone` over SSH - -```mermaid -sequenceDiagram - User ->> Git SSHD: ssh git@gitlab.com - Git SSHD ->> Rails: GET /api/v4/internal/authorized_keys - Rails ->> Git SSHD: 200 OK (list of accepted SSH keys) - Git SSHD ->> User: Accept SSH - User ->> Git SSHD: git clone over SSH - Git SSHD ->> Rails: POST /api/v4/internal/allowed?project=/gitlab-org/gitlab.git&service=git-receive-pack - Rails ->> Git SSHD: 200 OK - Git SSHD ->> Gitaly: RPC ReceivePack - Gitaly ->> Rails: POST /api/v4/internal/allowed?gl_repository=project-111 - Gitaly ->> Rails: POST /api/v4/internal/pre_receive?gl_repository=project-111 - Gitaly ->> Rails: POST /api/v4/internal/post_receive?gl_repository=project-111 - Gitaly ->> User: Response -``` - -### 2.5. Create commit via Web - -Execution of `Add CHANGELOG` to repository: - -```mermaid -sequenceDiagram - Web ->> Puma: POST /gitlab-org/gitlab/-/create/main - Puma ->> Gitaly: RPC TreeEntry - Gitaly ->> Rails: POST /api/v4/internal/allowed?gl_repository=project-111 - Gitaly ->> Rails: POST /api/v4/internal/pre_receive?gl_repository=project-111 - Gitaly ->> Rails: POST /api/v4/internal/post_receive?gl_repository=project-111 - Gitaly ->> Puma: Response - Puma ->> Web: See CHANGELOG -``` - -## 3. Proposal - -The Pods stateless router proposal requires that any ambiguous path (that is not routable) -will be made to be routable. It means that at least the following paths will have to be updated -do introduce a routable entity (project, group, or organization). - -Change: - -- `/api/v4/internal/allowed` => `/api/v4/internal/projects/<gl_repository>/allowed` -- `/api/v4/internal/pre_receive` => `/api/v4/internal/projects/<gl_repository>/pre_receive` -- `/api/v4/internal/post_receive` => `/api/v4/internal/projects/<gl_repository>/post_receive` -- `/api/v4/internal/lfs_authenticate` => `/api/v4/internal/projects/<gl_repository>/lfs_authenticate` - -Where: - -- `gl_repository` can be `project-1111` (`Gitlab::GlRepository`) -- `gl_repository` in some cases might be a full path to repository as executed by GitLab Shell (`/gitlab-org/gitlab.git`) - -## 4. Evaluation - -Supporting Git repositories if a Pod can access only its own repositories does not appear to be complex. - -The one major complication is supporting snippets, but this likely falls in the same category as for the approach -to support user's personal namespaces. - -## 4.1. Pros - -1. The API used for supporting HTTPS/SSH and Hooks are well defined and can easily be made routable. - -## 4.2. Cons - -1. The sharing of repositories objects is limited to the given Pod and Gitaly node. -1. The across-Pods forks are likely impossible to be supported (discover: how this work today across different Gitaly node). +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-gitlab-pages.md b/doc/architecture/blueprints/pods/pods-feature-gitlab-pages.md index 932f996d8ba..4c7f162434e 100644 --- a/doc/architecture/blueprints/pods/pods-feature-gitlab-pages.md +++ b/doc/architecture/blueprints/pods/pods-feature-gitlab-pages.md @@ -1,29 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: GitLab Pages' +redirect_to: '../cells/cells-feature-gitlab-pages.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/cells-feature-gitlab-pages.md). -# Pods: GitLab Pages - -> TL;DR - -## 1. Definition - -## 2. Data flow - -## 3. Proposal - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-global-search.md b/doc/architecture/blueprints/pods/pods-feature-global-search.md index 5ea863ac646..035e95219e4 100644 --- a/doc/architecture/blueprints/pods/pods-feature-global-search.md +++ b/doc/architecture/blueprints/pods/pods-feature-global-search.md @@ -1,47 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Global search' +redirect_to: '../cells/cells-feature-global-search.md' +remove_date: '2023-06-13' --- -DISCLAIMER: -This page may contain information related to upcoming products, features and -functionality. It is important to note that the information presented is for -informational purposes only, so please do not rely on the information for -purchasing or planning purposes. Just like with all projects, the items -mentioned on the page are subject to change or delay, and the development, -release, and timing of any products, features, or functionality remain at the -sole discretion of GitLab Inc. +This document was moved to [another location](../cells/cells-feature-global-search.md). -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. - -# Pods: Global search - -When we introduce multiple Pods we intend to isolate all services related to -those Pods. This will include Elasticsearch which means our current global -search functionality will not work. It may be possible to implement aggregated -search across all pods, but it is unlikely to be performant to do fan-out -searches across all pods especially once you start to do pagination which -requires setting the correct offset and page number for each search. - -## 1. Definition - -## 2. Data flow - -## 3. Proposal - -Likely first versions of Pods will simply not support global searches and then -we may later consider if building global searches to support popular use cases -is worthwhile. - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-graphql.md b/doc/architecture/blueprints/pods/pods-feature-graphql.md index 87c8391fbb3..f0f01a2b120 100644 --- a/doc/architecture/blueprints/pods/pods-feature-graphql.md +++ b/doc/architecture/blueprints/pods/pods-feature-graphql.md @@ -1,94 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: GraphQL' +redirect_to: '../cells/cells-feature-graphql.md' +remove_date: '2023-06-13' --- -DISCLAIMER: -This page may contain information related to upcoming products, features and -functionality. It is important to note that the information presented is for -informational purposes only, so please do not rely on the information for -purchasing or planning purposes. Just like with all projects, the items -mentioned on the page are subject to change or delay, and the development, -release, and timing of any products, features, or functionality remain at the -sole discretion of GitLab Inc. +This document was moved to [another location](../cells/cells-feature-graphql.md). -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. - -# Pods: GraphQL - -GitLab extensively uses GraphQL to perform efficient data query operations. -GraphQL due to it's nature is not directly routable. The way how GitLab uses -it calls the `/api/graphql` endpoint, and only query or mutation of body request -might define where the data can be accessed. - -## 1. Definition - -## 2. Data flow - -## 3. Proposal - -There are at least two main ways to implement GraphQL in Pods architecture. - -### 3.1. GraphQL routable by endpoint - -Change `/api/graphql` to `/api/organization/<organization>/graphql`. - -- This breaks all existing usages of `/api/graphql` endpoint - since the API URI is changed. - -### 3.2. GraphQL routable by body - -As part of router parse GraphQL body to find a routable entity, like `project`. - -- This still makes the GraphQL query be executed only in context of a given Pod - and not allowing the data to be merged. - -```json -# Good example -{ - project(fullPath:"gitlab-org/gitlab") { - id - description - } -} - -# Bad example, since Merge Request is not routable -{ - mergeRequest(id: 1111) { - iid - description - } -} -``` - -### 3.3. Merging GraphQL Proxy - -Implement as part of router GraphQL Proxy which can parse body -and merge results from many Pods. - -- This might make pagination hard to achieve, or we might assume that - we execute many queries of which results are merged across all Pods. - -```json -{ - project(fullPath:"gitlab-org/gitlab"){ - id, description - } - group(fullPath:"gitlab-com") { - id, description - } -} -``` - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-organizations.md b/doc/architecture/blueprints/pods/pods-feature-organizations.md index a0a87458767..f801f739374 100644 --- a/doc/architecture/blueprints/pods/pods-feature-organizations.md +++ b/doc/architecture/blueprints/pods/pods-feature-organizations.md @@ -1,58 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Organizations' +redirect_to: '../cells/cells-feature-organizations.md' +remove_date: '2023-06-13' --- -DISCLAIMER: -This page may contain information related to upcoming products, features and -functionality. It is important to note that the information presented is for -informational purposes only, so please do not rely on the information for -purchasing or planning purposes. Just like with all projects, the items -mentioned on the page are subject to change or delay, and the development, -release, and timing of any products, features, or functionality remain at the -sole discretion of GitLab Inc. +This document was moved to [another location](../cells/cells-feature-organizations.md). -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. - -# Pods: Organizations - -One of the major designs of Pods architecture is strong isolation between Groups. -Organizations as described by this blueprint provides a way to have plausible UX -for joining together many Groups that are isolated from the rest of systems. - -## 1. Definition - -Pods do require that all groups and projects of a single organization can -only be stored on a single Pod since a Pod can only access data that it holds locally -and has very limited capabilities to read information from other Pods. - -Pods with Organizations do require strong isolation between organizations. - -It will have significant implications on various user-facing features, -like Todos, dropdowns allowing to select projects, references to other issues -or projects, or any other social functions present at GitLab. Today those functions -were able to reference anything in the whole system. With the introduction of -organizations such will be forbidden. - -This problem definition aims to answer effort and implications required to add -strong isolation between organizations to the system. Including features affected -and their data processing flow. The purpose is to ensure that our solution when -implemented consistently avoids data leakage between organizations residing on -a single Pod. - -## 2. Data flow - -## 3. Proposal - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-personal-namespaces.md b/doc/architecture/blueprints/pods/pods-feature-personal-namespaces.md index f78044bb551..237eb5f9d64 100644 --- a/doc/architecture/blueprints/pods/pods-feature-personal-namespaces.md +++ b/doc/architecture/blueprints/pods/pods-feature-personal-namespaces.md @@ -1,29 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Personal Namespaces' +redirect_to: '../cells/cells-feature-personal-namespaces.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/cells-feature-personal-namespaces.md). -# Pods: Personal Namespaces - -> TL;DR - -## 1. Definition - -## 2. Data flow - -## 3. Proposal - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-router-endpoints-classification.md b/doc/architecture/blueprints/pods/pods-feature-router-endpoints-classification.md index bf0969fcb38..b9e85c29481 100644 --- a/doc/architecture/blueprints/pods/pods-feature-router-endpoints-classification.md +++ b/doc/architecture/blueprints/pods/pods-feature-router-endpoints-classification.md @@ -1,46 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Router Endpoints Classification' +redirect_to: '../cells/cells-feature-router-endpoints-classification.md' +remove_date: '2023-06-13' --- -DISCLAIMER: -This page may contain information related to upcoming products, features and -functionality. It is important to note that the information presented is for -informational purposes only, so please do not rely on the information for -purchasing or planning purposes. Just like with all projects, the items -mentioned on the page are subject to change or delay, and the development, -release, and timing of any products, features, or functionality remain at the -sole discretion of GitLab Inc. +This document was moved to [another location](../cells/cells-feature-router-endpoints-classification.md). -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. - -# Pods: Router Endpoints Classification - -Classification of all endpoints is essential to properly route request -hitting load balancer of a GitLab installation to a Pod that can serve it. - -Each Pod should be able to decode each request and classify for which Pod -it belongs to. - -GitLab currently implements hundreds of endpoints. This document tries -to describe various techniques that can be implemented to allow the Rails -to provide this information efficiently. - -## 1. Definition - -## 2. Data flow - -## 3. Proposal - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-schema-changes.md b/doc/architecture/blueprints/pods/pods-feature-schema-changes.md index ae7c288028d..a57f76ad9d4 100644 --- a/doc/architecture/blueprints/pods/pods-feature-schema-changes.md +++ b/doc/architecture/blueprints/pods/pods-feature-schema-changes.md @@ -1,55 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Schema changes' +redirect_to: '../cells/cells-feature-schema-changes.md' +remove_date: '2023-06-13' --- -DISCLAIMER: -This page may contain information related to upcoming products, features and -functionality. It is important to note that the information presented is for -informational purposes only, so please do not rely on the information for -purchasing or planning purposes. Just like with all projects, the items -mentioned on the page are subject to change or delay, and the development, -release, and timing of any products, features, or functionality remain at the -sole discretion of GitLab Inc. +This document was moved to [another location](../cells/cells-feature-schema-changes.md). -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. - -# Pods: Schema changes - -When we introduce multiple Pods that own their own databases this will -complicate the process of making schema changes to Postgres and Elasticsearch. -Today we already need to be careful to make changes comply with our zero -downtime deployments. For example, -[when removing a column we need to make changes over 3 separate deployments](../../../development/database/avoiding_downtime_in_migrations.md#dropping-columns). -We have tooling like `post_migrate` that helps with these kinds of changes to -reduce the number of merge requests needed, but these will be complicated when -we are dealing with deploying multiple rails applications that will be at -different versions at any one time. This problem will be particularly tricky to -solve for shared databases like our plan to share the `users` related tables -among all Pods. - -A key benefit of Pods may be that it allows us to run different -customers on different versions of GitLab. We may choose to update our own pod -before all our customers giving us even more flexibility than our current -canary architecture. But doing this means that schema changes need to have even -more versions of backward compatibility support which could slow down -development as we need extra steps to make schema changes. - -## 1. Definition - -## 2. Data flow - -## 3. Proposal - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-secrets.md b/doc/architecture/blueprints/pods/pods-feature-secrets.md index f18a41dc0fb..f33b98add21 100644 --- a/doc/architecture/blueprints/pods/pods-feature-secrets.md +++ b/doc/architecture/blueprints/pods/pods-feature-secrets.md @@ -1,48 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Secrets' +redirect_to: '../cells/cells-feature-secrets.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/cells-feature-secrets.md). -# Pods: Secrets - -Where possible, each pod should have its own distinct set of secrets. -However, there will be some secrets that will be required to be the same for all -pods in the cluster - -## 1. Definition - -GitLab has a lot of -[secrets](https://docs.gitlab.com/charts/installation/secrets.html) that needs -to be configured. - -Some secrets are for inter-component communication, e.g. `GitLab Shell secret`, -and used only within a pod. - -Some secrets are used for features, e.g. `ci_jwt_signing_key`. - -## 2. Data flow - -## 3. Proposal - -1. Secrets used for features will need to be consistent across all pods, so that the UX is consistent. - 1. This is especially true for the `db_key_base` secret which is used for - encrypting data at rest in the database - so that projects that are - transferred to another pod will continue to work. We do not want to have - to re-encrypt such rows when we move projects/groups between pods. -1. Secrets which are used for intra-pod communication only should be uniquely generated - per-pod. - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-snippets.md b/doc/architecture/blueprints/pods/pods-feature-snippets.md index 1bb866ca958..42d3c401dba 100644 --- a/doc/architecture/blueprints/pods/pods-feature-snippets.md +++ b/doc/architecture/blueprints/pods/pods-feature-snippets.md @@ -1,29 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Snippets' +redirect_to: '../cells/cells-feature-snippets.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/cells-feature-snippets.md). -# Pods: Snippets - -> TL;DR - -## 1. Definition - -## 2. Data flow - -## 3. Proposal - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-template.md b/doc/architecture/blueprints/pods/pods-feature-template.md index dfae21b5406..acc8e329725 100644 --- a/doc/architecture/blueprints/pods/pods-feature-template.md +++ b/doc/architecture/blueprints/pods/pods-feature-template.md @@ -1,29 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Problem A' +redirect_to: '../cells/cells-feature-template.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/cells-feature-template.md). -# Pods: A - -> TL;DR - -## 1. Definition - -## 2. Data flow - -## 3. Proposal - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/pods-feature-uploads.md b/doc/architecture/blueprints/pods/pods-feature-uploads.md index 634f3ef9560..1de4c138843 100644 --- a/doc/architecture/blueprints/pods/pods-feature-uploads.md +++ b/doc/architecture/blueprints/pods/pods-feature-uploads.md @@ -1,29 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods: Uploads' +redirect_to: '../cells/cells-feature-uploads.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/cells-feature-uploads.md). -# Pods: Uploads - -> TL;DR - -## 1. Definition - -## 2. Data flow - -## 3. Proposal - -## 4. Evaluation - -## 4.1. Pros - -## 4.2. Cons +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/proposal-stateless-router-with-buffering-requests.md b/doc/architecture/blueprints/pods/proposal-stateless-router-with-buffering-requests.md index adc523e90c2..4c135c5dbc3 100644 --- a/doc/architecture/blueprints/pods/proposal-stateless-router-with-buffering-requests.md +++ b/doc/architecture/blueprints/pods/proposal-stateless-router-with-buffering-requests.md @@ -1,648 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods Stateless Router Proposal' +redirect_to: '../cells/proposal-stateless-router-with-buffering-requests.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/proposal-stateless-router-with-buffering-requests.md). -# Proposal: Stateless Router - -We will decompose `gitlab_users`, `gitlab_routes` and `gitlab_admin` related -tables so that they can be shared between all pods and allow any pod to -authenticate a user and route requests to the correct pod. Pods may receive -requests for the resources they don't own, but they know how to redirect back -to the correct pod. - -The router is stateless and does not read from the `routes` database which -means that all interactions with the database still happen from the Rails -monolith. This architecture also supports regions by allowing for low traffic -databases to be replicated across regions. - -Users are not directly exposed to the concept of Pods but instead they see -different data dependent on their chosen "organization". -[Organizations](index.md#organizations) will be a new model introduced to enforce isolation in the -application and allow us to decide which request route to which pod, since an -organization can only be on a single pod. - -## Differences - -The main difference between this proposal and the one [with learning routes](proposal-stateless-router-with-routes-learning.md) -is that this proposal always sends requests to any of the Pods. If the requests cannot be processed, -the requests will be bounced back with relevant headers. This requires that request to be buffered. -It allows that request decoding can be either via URI or Body of request by Rails. -This means that each request might be sent more than once and be processed more than once as result. - -The [with learning routes proposal](proposal-stateless-router-with-routes-learning.md) requires that -routable information is always encoded in URI, and the router sends a pre-flight request. - -## Summary in diagrams - -This shows how a user request routes via DNS to the nearest router and the router chooses a pod to send the request to. - -```mermaid -graph TD; - user((User)); - dns[DNS]; - router_us(Router); - router_eu(Router); - pod_us0{Pod US0}; - pod_us1{Pod US1}; - pod_eu0{Pod EU0}; - pod_eu1{Pod EU1}; - user-->dns; - dns-->router_us; - dns-->router_eu; - subgraph Europe - router_eu-->pod_eu0; - router_eu-->pod_eu1; - end - subgraph United States - router_us-->pod_us0; - router_us-->pod_us1; - end -``` - -<details><summary>More detail</summary> - -This shows that the router can actually send requests to any pod. The user will -get the closest router to them geographically. - -```mermaid -graph TD; - user((User)); - dns[DNS]; - router_us(Router); - router_eu(Router); - pod_us0{Pod US0}; - pod_us1{Pod US1}; - pod_eu0{Pod EU0}; - pod_eu1{Pod EU1}; - user-->dns; - dns-->router_us; - dns-->router_eu; - subgraph Europe - router_eu-->pod_eu0; - router_eu-->pod_eu1; - end - subgraph United States - router_us-->pod_us0; - router_us-->pod_us1; - end - router_eu-.->pod_us0; - router_eu-.->pod_us1; - router_us-.->pod_eu0; - router_us-.->pod_eu1; -``` - -</details> - -<details><summary>Even more detail</summary> - -This shows the databases. `gitlab_users` and `gitlab_routes` exist only in the -US region but are replicated to other regions. Replication does not have an -arrow because it's too hard to read the diagram. - -```mermaid -graph TD; - user((User)); - dns[DNS]; - router_us(Router); - router_eu(Router); - pod_us0{Pod US0}; - pod_us1{Pod US1}; - pod_eu0{Pod EU0}; - pod_eu1{Pod EU1}; - db_gitlab_users[(gitlab_users Primary)]; - db_gitlab_routes[(gitlab_routes Primary)]; - db_gitlab_users_replica[(gitlab_users Replica)]; - db_gitlab_routes_replica[(gitlab_routes Replica)]; - db_pod_us0[(gitlab_main/gitlab_ci Pod US0)]; - db_pod_us1[(gitlab_main/gitlab_ci Pod US1)]; - db_pod_eu0[(gitlab_main/gitlab_ci Pod EU0)]; - db_pod_eu1[(gitlab_main/gitlab_ci Pod EU1)]; - user-->dns; - dns-->router_us; - dns-->router_eu; - subgraph Europe - router_eu-->pod_eu0; - router_eu-->pod_eu1; - pod_eu0-->db_pod_eu0; - pod_eu0-->db_gitlab_users_replica; - pod_eu0-->db_gitlab_routes_replica; - pod_eu1-->db_gitlab_users_replica; - pod_eu1-->db_gitlab_routes_replica; - pod_eu1-->db_pod_eu1; - end - subgraph United States - router_us-->pod_us0; - router_us-->pod_us1; - pod_us0-->db_pod_us0; - pod_us0-->db_gitlab_users; - pod_us0-->db_gitlab_routes; - pod_us1-->db_gitlab_users; - pod_us1-->db_gitlab_routes; - pod_us1-->db_pod_us1; - end - router_eu-.->pod_us0; - router_eu-.->pod_us1; - router_us-.->pod_eu0; - router_us-.->pod_eu1; -``` - -</details> - -## Summary of changes - -1. Tables related to User data (including profile settings, authentication credentials, personal access tokens) are decomposed into a `gitlab_users` schema -1. The `routes` table is decomposed into `gitlab_routes` schema -1. The `application_settings` (and probably a few other instance level tables) are decomposed into `gitlab_admin` schema -1. A new column `routes.pod_id` is added to `routes` table -1. A new Router service exists to choose which pod to route a request to. -1. A new concept will be introduced in GitLab called an organization and a user can select a "default organization" and this will be a user level setting. The default organization is used to redirect users away from ambiguous routes like `/dashboard` to organization scoped routes like `/organizations/my-organization/-/dashboard`. Legacy users will have a special default organization that allows them to keep using global resources on `Pod US0`. All existing namespaces will initially move to this public organization. -1. If a pod receives a request for a `routes.pod_id` that it does not own it returns a `302` with `X-Gitlab-Pod-Redirect` header so that the router can send the request to the correct pod. The correct pod can also set a header `X-Gitlab-Pod-Cache` which contains information about how this request should be cached to remember the pod. For example if the request was `/gitlab-org/gitlab` then the header would encode `/gitlab-org/* => Pod US0` (for example, any requests starting with `/gitlab-org/` can always be routed to `Pod US0` -1. When the pod does not know (from the cache) which pod to send a request to it just picks a random pod within it's region -1. Writes to `gitlab_users` and `gitlab_routes` are sent to a primary PostgreSQL server in our `US` region but reads can come from replicas in the same region. This will add latency for these writes but we expect they are infrequent relative to the rest of GitLab. - -## Detailed explanation of default organization in the first iteration - -All users will get a new column `users.default_organization` which they can -control in user settings. We will introduce a concept of the -`GitLab.com Public` organization. This will be set as the default organization for all existing -users. This organization will allow the user to see data from all namespaces in -`Pod US0` (for example, our original GitLab.com instance). This behavior can be invisible to -existing users such that they don't even get told when they are viewing a -global page like `/dashboard` that it's even scoped to an organization. - -Any new users with a default organization other than `GitLab.com Public` will have -a distinct user experience and will be fully aware that every page they load is -only ever scoped to a single organization. These users can never -load any global pages like `/dashboard` and will end up being redirected to -`/organizations/<DEFAULT_ORGANIZATION>/-/dashboard`. This may also be the case -for legacy APIs and such users may only ever be able to use APIs scoped to a -organization. - -## Detailed explanation of Admin Area settings - -We believe that maintaining and synchronizing Admin Area settings will be -frustrating and painful so to avoid this we will decompose and share all Admin Area -settings in the `gitlab_admin` schema. This should be safe (similar to other -shared schemas) because these receive very little write traffic. - -In cases where different pods need different settings (for example, the -Elasticsearch URL), we will either decide to use a templated -format in the relevant `application_settings` row which allows it to be dynamic -per pod. Alternatively if that proves difficult we'll introduce a new table -called `per_pod_application_settings` and this will have 1 row per pod to allow -setting different settings per pod. It will still be part of the `gitlab_admin` -schema and shared which will allow us to centrally manage it and simplify -keeping settings in sync for all pods. - -## Pros - -1. Router is stateless and can live in many regions. We use Anycast DNS to resolve to nearest region for the user. -1. Pods can receive requests for namespaces in the wrong pod and the user - still gets the right response as well as caching at the router that - ensures the next request is sent to the correct pod so the next request - will go to the correct pod -1. The majority of the code still lives in `gitlab` rails codebase. The Router doesn't actually need to understand how GitLab URLs are composed. -1. Since the responsibility to read and write `gitlab_users`, - `gitlab_routes` and `gitlab_admin` still lives in Rails it means minimal - changes will be needed to the Rails application compared to extracting - services that need to isolate the domain models and build new interfaces. -1. Compared to a separate routing service this allows the Rails application - to encode more complex rules around how to map URLs to the correct pod - and may work for some existing API endpoints. -1. All the new infrastructure (just a router) is optional and a single-pod - self-managed installation does not even need to run the Router and there are - no other new services. - -## Cons - -1. `gitlab_users`, `gitlab_routes` and `gitlab_admin` databases may need to be - replicated across regions and writes need to go across regions. We need to - do an analysis on write TPS for the relevant tables to determine if this is - feasible. -1. Sharing access to the database from many different Pods means that they are - all coupled at the Postgres schema level and this means changes to the - database schema need to be done carefully in sync with the deployment of all - Pods. This limits us to ensure that Pods are kept in closely similar - versions compared to an architecture with shared services that have an API - we control. -1. Although most data is stored in the right region there can be requests - proxied from another region which may be an issue for certain types - of compliance. -1. Data in `gitlab_users` and `gitlab_routes` databases must be replicated in - all regions which may be an issue for certain types of compliance. -1. The router cache may need to be very large if we get a wide variety of URLs - (for example, long tail). In such a case we may need to implement a 2nd level of - caching in user cookies so their frequently accessed pages always go to the - right pod the first time. -1. Having shared database access for `gitlab_users` and `gitlab_routes` - from multiple pods is an unusual architecture decision compared to - extracting services that are called from multiple pods. -1. It is very likely we won't be able to find cacheable elements of a - GraphQL URL and often existing GraphQL endpoints are heavily dependent on - ids that won't be in the `routes` table so pods won't necessarily know - what pod has the data. As such we'll probably have to update our GraphQL - calls to include an organization context in the path like - `/api/organizations/<organization>/graphql`. -1. This architecture implies that implemented endpoints can only access data - that are readily accessible on a given Pod, but are unlikely - to aggregate information from many Pods. -1. All unknown routes are sent to the latest deployment which we assume to be `Pod US0`. - This is required as newly added endpoints will be only decodable by latest pod. - This Pod could later redirect to correct one that can serve the given request. - Since request processing might be heavy some Pods might receive significant amount - of traffic due to that. - -## Example database configuration - -Handling shared `gitlab_users`, `gitlab_routes` and `gitlab_admin` databases, while having dedicated `gitlab_main` and `gitlab_ci` databases should already be handled by the way we use `config/database.yml`. We should also, already be able to handle the dedicated EU replicas while having a single US primary for `gitlab_users` and `gitlab_routes`. Below is a snippet of part of the database configuration for the Pod architecture described above. - -<details><summary>Pod US0</summary> - -```yaml -# config/database.yml -production: - main: - host: postgres-main.pod-us0.primary.consul - load_balancing: - discovery: postgres-main.pod-us0.replicas.consul - ci: - host: postgres-ci.pod-us0.primary.consul - load_balancing: - discovery: postgres-ci.pod-us0.replicas.consul - users: - host: postgres-users-primary.consul - load_balancing: - discovery: postgres-users-replicas.us.consul - routes: - host: postgres-routes-primary.consul - load_balancing: - discovery: postgres-routes-replicas.us.consul - admin: - host: postgres-admin-primary.consul - load_balancing: - discovery: postgres-admin-replicas.us.consul -``` - -</details> - -<details><summary>Pod EU0</summary> - -```yaml -# config/database.yml -production: - main: - host: postgres-main.pod-eu0.primary.consul - load_balancing: - discovery: postgres-main.pod-eu0.replicas.consul - ci: - host: postgres-ci.pod-eu0.primary.consul - load_balancing: - discovery: postgres-ci.pod-eu0.replicas.consul - users: - host: postgres-users-primary.consul - load_balancing: - discovery: postgres-users-replicas.eu.consul - routes: - host: postgres-routes-primary.consul - load_balancing: - discovery: postgres-routes-replicas.eu.consul - admin: - host: postgres-admin-primary.consul - load_balancing: - discovery: postgres-admin-replicas.eu.consul -``` - -</details> - -## Request flows - -1. `gitlab-org` is a top level namespace and lives in `Pod US0` in the `GitLab.com Public` organization -1. `my-company` is a top level namespace and lives in `Pod EU0` in the `my-organization` organization - -### Experience for paying user that is part of `my-organization` - -Such a user will have a default organization set to `/my-organization` and will be -unable to load any global routes outside of this organization. They may load other -projects/namespaces but their MR/Todo/Issue counts at the top of the page will -not be correctly populated in the first iteration. The user will be aware of -this limitation. - -#### Navigates to `/my-company/my-project` while logged in - -1. User is in Europe so DNS resolves to the router in Europe -1. They request `/my-company/my-project` without the router cache, so the router chooses randomly `Pod EU1` -1. `Pod EU1` does not have `/my-company`, but it knows that it lives in `Pod EU0` so it redirects the router to `Pod EU0` -1. `Pod EU0` returns the correct response as well as setting the cache headers for the router `/my-company/* => Pod EU0` -1. The router now caches and remembers any request paths matching `/my-company/*` should go to `Pod EU0` - -```mermaid -sequenceDiagram - participant user as User - participant router_eu as Router EU - participant pod_eu0 as Pod EU0 - participant pod_eu1 as Pod EU1 - user->>router_eu: GET /my-company/my-project - router_eu->>pod_eu1: GET /my-company/my-project - pod_eu1->>router_eu: 302 /my-company/my-project X-Gitlab-Pod-Redirect={pod:Pod EU0} - router_eu->>pod_eu0: GET /my-company/my-project - pod_eu0->>user: <h1>My Project... X-Gitlab-Pod-Cache={path_prefix:/my-company/} -``` - -#### Navigates to `/my-company/my-project` while not logged in - -1. User is in Europe so DNS resolves to the router in Europe -1. The router does not have `/my-company/*` cached yet so it chooses randomly `Pod EU1` -1. `Pod EU1` redirects them through a login flow -1. Still they request `/my-company/my-project` without the router cache, so the router chooses a random pod `Pod EU1` -1. `Pod EU1` does not have `/my-company`, but it knows that it lives in `Pod EU0` so it redirects the router to `Pod EU0` -1. `Pod EU0` returns the correct response as well as setting the cache headers for the router `/my-company/* => Pod EU0` -1. The router now caches and remembers any request paths matching `/my-company/*` should go to `Pod EU0` - -```mermaid -sequenceDiagram - participant user as User - participant router_eu as Router EU - participant pod_eu0 as Pod EU0 - participant pod_eu1 as Pod EU1 - user->>router_eu: GET /my-company/my-project - router_eu->>pod_eu1: GET /my-company/my-project - pod_eu1->>user: 302 /users/sign_in?redirect=/my-company/my-project - user->>router_eu: GET /users/sign_in?redirect=/my-company/my-project - router_eu->>pod_eu1: GET /users/sign_in?redirect=/my-company/my-project - pod_eu1->>user: <h1>Sign in... - user->>router_eu: POST /users/sign_in?redirect=/my-company/my-project - router_eu->>pod_eu1: POST /users/sign_in?redirect=/my-company/my-project - pod_eu1->>user: 302 /my-company/my-project - user->>router_eu: GET /my-company/my-project - router_eu->>pod_eu1: GET /my-company/my-project - pod_eu1->>router_eu: 302 /my-company/my-project X-Gitlab-Pod-Redirect={pod:Pod EU0} - router_eu->>pod_eu0: GET /my-company/my-project - pod_eu0->>user: <h1>My Project... X-Gitlab-Pod-Cache={path_prefix:/my-company/} -``` - -#### Navigates to `/my-company/my-other-project` after last step - -1. User is in Europe so DNS resolves to the router in Europe -1. The router cache now has `/my-company/* => Pod EU0`, so the router chooses `Pod EU0` -1. `Pod EU0` returns the correct response as well as the cache header again - -```mermaid -sequenceDiagram - participant user as User - participant router_eu as Router EU - participant pod_eu0 as Pod EU0 - participant pod_eu1 as Pod EU1 - user->>router_eu: GET /my-company/my-project - router_eu->>pod_eu0: GET /my-company/my-project - pod_eu0->>user: <h1>My Project... X-Gitlab-Pod-Cache={path_prefix:/my-company/} -``` - -#### Navigates to `/gitlab-org/gitlab` after last step - -1. User is in Europe so DNS resolves to the router in Europe -1. The router has no cached value for this URL so randomly chooses `Pod EU0` -1. `Pod EU0` redirects the router to `Pod US0` -1. `Pod US0` returns the correct response as well as the cache header again - -```mermaid -sequenceDiagram - participant user as User - participant router_eu as Router EU - participant pod_eu0 as Pod EU0 - participant pod_us0 as Pod US0 - user->>router_eu: GET /gitlab-org/gitlab - router_eu->>pod_eu0: GET /gitlab-org/gitlab - pod_eu0->>router_eu: 302 /gitlab-org/gitlab X-Gitlab-Pod-Redirect={pod:Pod US0} - router_eu->>pod_us0: GET /gitlab-org/gitlab - pod_us0->>user: <h1>GitLab.org... X-Gitlab-Pod-Cache={path_prefix:/gitlab-org/} -``` - -In this case the user is not on their "default organization" so their TODO -counter will not include their normal todos. We may choose to highlight this in -the UI somewhere. A future iteration may be able to fetch that for them from -their default organization. - -#### Navigates to `/` - -1. User is in Europe so DNS resolves to the router in Europe -1. Router does not have a cache for `/` route (specifically rails never tells it to cache this route) -1. The Router choose `Pod EU0` randomly -1. The Rails application knows the users default organization is `/my-organization`, so - it redirects the user to `/organizations/my-organization/-/dashboard` -1. The Router has a cached value for `/organizations/my-organization/*` so it then sends the - request to `POD EU0` -1. `Pod EU0` serves up a new page `/organizations/my-organization/-/dashboard` which is the same - dashboard view we have today but scoped to an organization clearly in the UI -1. The user is (optionally) presented with a message saying that data on this page is only - from their default organization and that they can change their default - organization if it's not right. - -```mermaid -sequenceDiagram - participant user as User - participant router_eu as Router EU - participant pod_eu0 as Pod EU0 - user->>router_eu: GET / - router_eu->>pod_eu0: GET / - pod_eu0->>user: 302 /organizations/my-organization/-/dashboard - user->>router: GET /organizations/my-organization/-/dashboard - router->>pod_eu0: GET /organizations/my-organization/-/dashboard - pod_eu0->>user: <h1>My Company Dashboard... X-Gitlab-Pod-Cache={path_prefix:/organizations/my-organization/} -``` - -#### Navigates to `/dashboard` - -As above, they will end up on `/organizations/my-organization/-/dashboard` as -the rails application will already redirect `/` to the dashboard page. - -### Navigates to `/not-my-company/not-my-project` while logged in (but they don't have access since this project/group is private) - -1. User is in Europe so DNS resolves to the router in Europe -1. The router knows that `/not-my-company` lives in `Pod US1` so sends the request to this -1. The user does not have access so `Pod US1` returns 404 - -```mermaid -sequenceDiagram - participant user as User - participant router_eu as Router EU - participant pod_us1 as Pod US1 - user->>router_eu: GET /not-my-company/not-my-project - router_eu->>pod_us1: GET /not-my-company/not-my-project - pod_us1->>user: 404 -``` - -#### Creates a new top level namespace - -The user will be asked which organization they want the namespace to belong to. -If they select `my-organization` then it will end up on the same pod as all -other namespaces in `my-organization`. If they select nothing we default to -`GitLab.com Public` and it is clear to the user that this is isolated from -their existing organization such that they won't be able to see data from both -on a single page. - -### Experience for GitLab team member that is part of `/gitlab-org` - -Such a user is considered a legacy user and has their default organization set to -`GitLab.com Public`. This is a "meta" organization that does not really exist but -the Rails application knows to interpret this organization to mean that they are -allowed to use legacy global functionality like `/dashboard` to see data across -namespaces located on `Pod US0`. The rails backend also knows that the default pod to render any ambiguous -routes like `/dashboard` is `Pod US0`. Lastly the user will be allowed to -navigate to organizations on another pod like `/my-organization` but when they do the -user will see a message indicating that some data may be missing (for example, the -MRs/Issues/Todos) counts. - -#### Navigates to `/gitlab-org/gitlab` while not logged in - -1. User is in the US so DNS resolves to the US router -1. The router knows that `/gitlab-org` lives in `Pod US0` so sends the request - to this pod -1. `Pod US0` serves up the response - -```mermaid -sequenceDiagram - participant user as User - participant router_us as Router US - participant pod_us0 as Pod US0 - user->>router_us: GET /gitlab-org/gitlab - router_us->>pod_us0: GET /gitlab-org/gitlab - pod_us0->>user: <h1>GitLab.org... X-Gitlab-Pod-Cache={path_prefix:/gitlab-org/} -``` - -#### Navigates to `/` - -1. User is in US so DNS resolves to the router in US -1. Router does not have a cache for `/` route (specifically rails never tells it to cache this route) -1. The Router chooses `Pod US1` randomly -1. The Rails application knows the users default organization is `GitLab.com Public`, so - it redirects the user to `/dashboards` (only legacy users can see - `/dashboard` global view) -1. Router does not have a cache for `/dashboard` route (specifically rails never tells it to cache this route) -1. The Router chooses `Pod US1` randomly -1. The Rails application knows the users default organization is `GitLab.com Public`, so - it allows the user to load `/dashboards` (only legacy users can see - `/dashboard` global view) and redirects to router the legacy pod which is `Pod US0` -1. `Pod US0` serves up the global view dashboard page `/dashboard` which is the same - dashboard view we have today - -```mermaid -sequenceDiagram - participant user as User - participant router_us as Router US - participant pod_us0 as Pod US0 - participant pod_us1 as Pod US1 - user->>router_us: GET / - router_us->>pod_us1: GET / - pod_us1->>user: 302 /dashboard - user->>router_us: GET /dashboard - router_us->>pod_us1: GET /dashboard - pod_us1->>router_us: 302 /dashboard X-Gitlab-Pod-Redirect={pod:Pod US0} - router_us->>pod_us0: GET /dashboard - pod_us0->>user: <h1>Dashboard... -``` - -#### Navigates to `/my-company/my-other-project` while logged in (but they don't have access since this project is private) - -They get a 404. - -### Experience for non-authenticated users - -Flow is similar to authenticated users except global routes like `/dashboard` will -redirect to the login page as there is no default organization to choose from. - -### A new customers signs up - -They will be asked if they are already part of an organization or if they'd -like to create one. If they choose neither they end up no the default -`GitLab.com Public` organization. - -### An organization is moved from 1 pod to another - -TODO - -### GraphQL/API requests which don't include the namespace in the URL - -TODO - -### The autocomplete suggestion functionality in the search bar which remembers recent issues/MRs - -TODO - -### Global search - -TODO - -## Administrator - -### Loads `/admin` page - -1. Router picks a random pod `Pod US0` -1. Pod US0 redirects user to `/admin/pods/podus0` -1. Pod US0 renders an Admin Area page and also returns a cache header to cache `/admin/podss/podus0/* => Pod US0`. The Admin Area page contains a dropdown list showing other pods they could select and it changes the query parameter. - -Admin Area settings in Postgres are all shared across all pods to avoid -divergence but we still make it clear in the URL and UI which pod is serving -the Admin Area page as there is dynamic data being generated from these pages and -the operator may want to view a specific pod. - -## More Technical Problems To Solve - -### Replicating User Sessions Between All Pods - -Today user sessions live in Redis but each pod will have their own Redis instance. We already use a dedicated Redis instance for sessions so we could consider sharing this with all pods like we do with `gitlab_users` PostgreSQL database. But an important consideration will be latency as we would still want to mostly fetch sessions from the same region. - -An alternative might be that user sessions get moved to a JWT payload that encodes all the session data but this has downsides. For example, it is difficult to expire a user session, when their password changes or for other reasons, if the session lives in a JWT controlled by the user. - -### How do we migrate between Pods - -Migrating data between pods will need to factor all data stores: - -1. PostgreSQL -1. Redis Shared State -1. Gitaly -1. Elasticsearch - -### Is it still possible to leak the existence of private groups via a timing attack? - -If you have router in EU, and you know that EU router by default redirects -to EU located Pods, you know their latency (lets assume 10 ms). Now, if your -request is bounced back and redirected to US which has different latency -(lets assume that roundtrip will be around 60 ms) you can deduce that 404 was -returned by US Pod and know that your 404 is in fact 403. - -We may defer this until we actually implement a pod in a different region. Such timing attacks are already theoretically possible with the way we do permission checks today but the timing difference is probably too small to be able to detect. - -One technique to mitigate this risk might be to have the router add a random -delay to any request that returns 404 from a pod. - -## Should runners be shared across all pods? - -We have 2 options and we should decide which is easier: - -1. Decompose runner registration and queuing tables and share them across all - pods. This may have implications for scalability, and we'd need to consider - if this would include group/project runners as this may have scalability - concerns as these are high traffic tables that would need to be shared. -1. Runners are registered per-pod and, we probably have a separate fleet of - runners for every pod or just register the same runners to many pods which - may have implications for queueing - -## How do we guarantee unique ids across all pods for things that cannot conflict? - -This project assumes at least namespaces and projects have unique ids across -all pods as many requests need to be routed based on their ID. Since those -tables are across different databases then guaranteeing a unique ID will -require a new solution. There are likely other tables where unique IDs are -necessary and depending on how we resolve routing for GraphQL and other APIs -and other design goals it may be determined that we want the primary key to be -unique for all tables. +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/pods/proposal-stateless-router-with-routes-learning.md b/doc/architecture/blueprints/pods/proposal-stateless-router-with-routes-learning.md index 1156e65f6aa..093d5d7acc6 100644 --- a/doc/architecture/blueprints/pods/proposal-stateless-router-with-routes-learning.md +++ b/doc/architecture/blueprints/pods/proposal-stateless-router-with-routes-learning.md @@ -1,672 +1,11 @@ --- -stage: enablement -group: pods -comments: false -description: 'Pods Stateless Router Proposal' +redirect_to: '../cells/proposal-stateless-router-with-routes-learning.md' +remove_date: '2023-06-13' --- -This document is a work-in-progress and represents a very early state of the -Pods design. Significant aspects are not documented, though we expect to add -them in the future. This is one possible architecture for Pods, and we intend to -contrast this with alternatives before deciding which approach to implement. -This documentation will be kept even if we decide not to implement this so that -we can document the reasons for not choosing this approach. +This document was moved to [another location](../cells/proposal-stateless-router-with-routes-learning.md). -# Proposal: Stateless Router - -We will decompose `gitlab_users`, `gitlab_routes` and `gitlab_admin` related -tables so that they can be shared between all pods and allow any pod to -authenticate a user and route requests to the correct pod. Pods may receive -requests for the resources they don't own, but they know how to redirect back -to the correct pod. - -The router is stateless and does not read from the `routes` database which -means that all interactions with the database still happen from the Rails -monolith. This architecture also supports regions by allowing for low traffic -databases to be replicated across regions. - -Users are not directly exposed to the concept of Pods but instead they see -different data dependent on their chosen "organization". -[Organizations](index.md#organizations) will be a new model introduced to enforce isolation in the -application and allow us to decide which request route to which pod, since an -organization can only be on a single pod. - -## Differences - -The main difference between this proposal and one [with buffering requests](proposal-stateless-router-with-buffering-requests.md) -is that this proposal uses a pre-flight API request (`/api/v4/pods/learn`) to redirect the request body to the correct Pod. -This means that each request is sent exactly once to be processed, but the URI is used to decode which Pod it should be directed. - -## Summary in diagrams - -This shows how a user request routes via DNS to the nearest router and the router chooses a pod to send the request to. - -```mermaid -graph TD; - user((User)); - dns[DNS]; - router_us(Router); - router_eu(Router); - pod_us0{Pod US0}; - pod_us1{Pod US1}; - pod_eu0{Pod EU0}; - pod_eu1{Pod EU1}; - user-->dns; - dns-->router_us; - dns-->router_eu; - subgraph Europe - router_eu-->pod_eu0; - router_eu-->pod_eu1; - end - subgraph United States - router_us-->pod_us0; - router_us-->pod_us1; - end -``` - -### More detail - -This shows that the router can actually send requests to any pod. The user will -get the closest router to them geographically. - -```mermaid -graph TD; - user((User)); - dns[DNS]; - router_us(Router); - router_eu(Router); - pod_us0{Pod US0}; - pod_us1{Pod US1}; - pod_eu0{Pod EU0}; - pod_eu1{Pod EU1}; - user-->dns; - dns-->router_us; - dns-->router_eu; - subgraph Europe - router_eu-->pod_eu0; - router_eu-->pod_eu1; - end - subgraph United States - router_us-->pod_us0; - router_us-->pod_us1; - end - router_eu-.->pod_us0; - router_eu-.->pod_us1; - router_us-.->pod_eu0; - router_us-.->pod_eu1; -``` - -### Even more detail - -This shows the databases. `gitlab_users` and `gitlab_routes` exist only in the -US region but are replicated to other regions. Replication does not have an -arrow because it's too hard to read the diagram. - -```mermaid -graph TD; - user((User)); - dns[DNS]; - router_us(Router); - router_eu(Router); - pod_us0{Pod US0}; - pod_us1{Pod US1}; - pod_eu0{Pod EU0}; - pod_eu1{Pod EU1}; - db_gitlab_users[(gitlab_users Primary)]; - db_gitlab_routes[(gitlab_routes Primary)]; - db_gitlab_users_replica[(gitlab_users Replica)]; - db_gitlab_routes_replica[(gitlab_routes Replica)]; - db_pod_us0[(gitlab_main/gitlab_ci Pod US0)]; - db_pod_us1[(gitlab_main/gitlab_ci Pod US1)]; - db_pod_eu0[(gitlab_main/gitlab_ci Pod EU0)]; - db_pod_eu1[(gitlab_main/gitlab_ci Pod EU1)]; - user-->dns; - dns-->router_us; - dns-->router_eu; - subgraph Europe - router_eu-->pod_eu0; - router_eu-->pod_eu1; - pod_eu0-->db_pod_eu0; - pod_eu0-->db_gitlab_users_replica; - pod_eu0-->db_gitlab_routes_replica; - pod_eu1-->db_gitlab_users_replica; - pod_eu1-->db_gitlab_routes_replica; - pod_eu1-->db_pod_eu1; - end - subgraph United States - router_us-->pod_us0; - router_us-->pod_us1; - pod_us0-->db_pod_us0; - pod_us0-->db_gitlab_users; - pod_us0-->db_gitlab_routes; - pod_us1-->db_gitlab_users; - pod_us1-->db_gitlab_routes; - pod_us1-->db_pod_us1; - end - router_eu-.->pod_us0; - router_eu-.->pod_us1; - router_us-.->pod_eu0; - router_us-.->pod_eu1; -``` - -## Summary of changes - -1. Tables related to User data (including profile settings, authentication credentials, personal access tokens) are decomposed into a `gitlab_users` schema -1. The `routes` table is decomposed into `gitlab_routes` schema -1. The `application_settings` (and probably a few other instance level tables) are decomposed into `gitlab_admin` schema -1. A new column `routes.pod_id` is added to `routes` table -1. A new Router service exists to choose which pod to route a request to. -1. If a router receives a new request it will send `/api/v4/pods/learn?method=GET&path_info=/group-org/project` to learn which Pod can process it -1. A new concept will be introduced in GitLab called an organization -1. We require all existing endpoints to be routable by URI, or be fixed to a specific Pod for processing. This requires changing ambiguous endpoints like `/dashboard` to be scoped like `/organizations/my-organization/-/dashboard` -1. Endpoints like `/admin` would be routed always to the specific Pod, like `pod_0` -1. Each Pod can respond to `/api/v4/pods/learn` and classify each endpoint -1. Writes to `gitlab_users` and `gitlab_routes` are sent to a primary PostgreSQL server in our `US` region but reads can come from replicas in the same region. This will add latency for these writes but we expect they are infrequent relative to the rest of GitLab. - -## Pre-flight request learning - -While processing a request the URI will be decoded and a pre-flight request -will be sent for each non-cached endpoint. - -When asking for the endpoint GitLab Rails will return information about -the routable path. GitLab Rails will decode `path_info` and match it to -an existing endpoint and find a routable entity (like project). The router will -treat this as short-lived cache information. - -1. Prefix match: `/api/v4/pods/learn?method=GET&path_info=/gitlab-org/gitlab-test/-/issues` - - ```json - { - "path": "/gitlab-org/gitlab-test", - "pod": "pod_0", - "source": "routable" - } - ``` - -1. Some endpoints might require an exact match: `/api/v4/pods/learn?method=GET&path_info=/-/profile` - - ```json - { - "path": "/-/profile", - "pod": "pod_0", - "source": "fixed", - "exact": true - } - ``` - -## Detailed explanation of default organization in the first iteration - -All users will get a new column `users.default_organization` which they can -control in user settings. We will introduce a concept of the -`GitLab.com Public` organization. This will be set as the default organization for all existing -users. This organization will allow the user to see data from all namespaces in -`Pod US0` (ie. our original GitLab.com instance). This behavior can be invisible to -existing users such that they don't even get told when they are viewing a -global page like `/dashboard` that it's even scoped to an organization. - -Any new users with a default organization other than `GitLab.com Public` will have -a distinct user experience and will be fully aware that every page they load is -only ever scoped to a single organization. These users can never -load any global pages like `/dashboard` and will end up being redirected to -`/organizations/<DEFAULT_ORGANIZATION>/-/dashboard`. This may also be the case -for legacy APIs and such users may only ever be able to use APIs scoped to a -organization. - -## Detailed explanation of Admin Area settings - -We believe that maintaining and synchronizing Admin Area settings will be -frustrating and painful so to avoid this we will decompose and share all Admin Area -settings in the `gitlab_admin` schema. This should be safe (similar to other -shared schemas) because these receive very little write traffic. - -In cases where different pods need different settings (eg. the -Elasticsearch URL), we will either decide to use a templated -format in the relevant `application_settings` row which allows it to be dynamic -per pod. Alternatively if that proves difficult we'll introduce a new table -called `per_pod_application_settings` and this will have 1 row per pod to allow -setting different settings per pod. It will still be part of the `gitlab_admin` -schema and shared which will allow us to centrally manage it and simplify -keeping settings in sync for all pods. - -## Pros - -1. Router is stateless and can live in many regions. We use Anycast DNS to resolve to nearest region for the user. -1. Pods can receive requests for namespaces in the wrong pod and the user - still gets the right response as well as caching at the router that - ensures the next request is sent to the correct pod so the next request - will go to the correct pod -1. The majority of the code still lives in `gitlab` rails codebase. The Router doesn't actually need to understand how GitLab URLs are composed. -1. Since the responsibility to read and write `gitlab_users`, - `gitlab_routes` and `gitlab_admin` still lives in Rails it means minimal - changes will be needed to the Rails application compared to extracting - services that need to isolate the domain models and build new interfaces. -1. Compared to a separate routing service this allows the Rails application - to encode more complex rules around how to map URLs to the correct pod - and may work for some existing API endpoints. -1. All the new infrastructure (just a router) is optional and a single-pod - self-managed installation does not even need to run the Router and there are - no other new services. - -## Cons - -1. `gitlab_users`, `gitlab_routes` and `gitlab_admin` databases may need to be - replicated across regions and writes need to go across regions. We need to - do an analysis on write TPS for the relevant tables to determine if this is - feasible. -1. Sharing access to the database from many different Pods means that they are - all coupled at the Postgres schema level and this means changes to the - database schema need to be done carefully in sync with the deployment of all - Pods. This limits us to ensure that Pods are kept in closely similar - versions compared to an architecture with shared services that have an API - we control. -1. Although most data is stored in the right region there can be requests - proxied from another region which may be an issue for certain types - of compliance. -1. Data in `gitlab_users` and `gitlab_routes` databases must be replicated in - all regions which may be an issue for certain types of compliance. -1. The router cache may need to be very large if we get a wide variety of URLs - (ie. long tail). In such a case we may need to implement a 2nd level of - caching in user cookies so their frequently accessed pages always go to the - right pod the first time. -1. Having shared database access for `gitlab_users` and `gitlab_routes` - from multiple pods is an unusual architecture decision compared to - extracting services that are called from multiple pods. -1. It is very likely we won't be able to find cacheable elements of a - GraphQL URL and often existing GraphQL endpoints are heavily dependent on - ids that won't be in the `routes` table so pods won't necessarily know - what pod has the data. As such we'll probably have to update our GraphQL - calls to include an organization context in the path like - `/api/organizations/<organization>/graphql`. -1. This architecture implies that implemented endpoints can only access data - that are readily accessible on a given Pod, but are unlikely - to aggregate information from many Pods. -1. All unknown routes are sent to the latest deployment which we assume to be `Pod US0`. - This is required as newly added endpoints will be only decodable by latest pod. - Likely this is not a problem for the `/pods/learn` is it is lightweight - to process and this should not cause a performance impact. - -## Example database configuration - -Handling shared `gitlab_users`, `gitlab_routes` and `gitlab_admin` databases, while having dedicated `gitlab_main` and `gitlab_ci` databases should already be handled by the way we use `config/database.yml`. We should also, already be able to handle the dedicated EU replicas while having a single US primary for `gitlab_users` and `gitlab_routes`. Below is a snippet of part of the database configuration for the Pod architecture described above. - -**Pod US0**: - -```yaml -# config/database.yml -production: - main: - host: postgres-main.pod-us0.primary.consul - load_balancing: - discovery: postgres-main.pod-us0.replicas.consul - ci: - host: postgres-ci.pod-us0.primary.consul - load_balancing: - discovery: postgres-ci.pod-us0.replicas.consul - users: - host: postgres-users-primary.consul - load_balancing: - discovery: postgres-users-replicas.us.consul - routes: - host: postgres-routes-primary.consul - load_balancing: - discovery: postgres-routes-replicas.us.consul - admin: - host: postgres-admin-primary.consul - load_balancing: - discovery: postgres-admin-replicas.us.consul -``` - -**Pod EU0**: - -```yaml -# config/database.yml -production: - main: - host: postgres-main.pod-eu0.primary.consul - load_balancing: - discovery: postgres-main.pod-eu0.replicas.consul - ci: - host: postgres-ci.pod-eu0.primary.consul - load_balancing: - discovery: postgres-ci.pod-eu0.replicas.consul - users: - host: postgres-users-primary.consul - load_balancing: - discovery: postgres-users-replicas.eu.consul - routes: - host: postgres-routes-primary.consul - load_balancing: - discovery: postgres-routes-replicas.eu.consul - admin: - host: postgres-admin-primary.consul - load_balancing: - discovery: postgres-admin-replicas.eu.consul -``` - -## Request flows - -1. `gitlab-org` is a top level namespace and lives in `Pod US0` in the `GitLab.com Public` organization -1. `my-company` is a top level namespace and lives in `Pod EU0` in the `my-organization` organization - -### Experience for paying user that is part of `my-organization` - -Such a user will have a default organization set to `/my-organization` and will be -unable to load any global routes outside of this organization. They may load other -projects/namespaces but their MR/Todo/Issue counts at the top of the page will -not be correctly populated in the first iteration. The user will be aware of -this limitation. - -#### Navigates to `/my-company/my-project` while logged in - -1. User is in Europe so DNS resolves to the router in Europe -1. They request `/my-company/my-project` without the router cache, so the router chooses randomly `Pod EU1` -1. The `/pods/learn` is sent to `Pod EU1`, which responds that resource lives on `Pod EU0` -1. `Pod EU0` returns the correct response -1. The router now caches and remembers any request paths matching `/my-company/*` should go to `Pod EU0` - -```mermaid -sequenceDiagram - participant user as User - participant router_eu as Router EU - participant pod_eu0 as Pod EU0 - participant pod_eu1 as Pod EU1 - user->>router_eu: GET /my-company/my-project - router_eu->>pod_eu1: /api/v4/pods/learn?method=GET&path_info=/my-company/my-project - pod_eu1->>router_eu: {path: "/my-company", pod: "pod_eu0", source: "routable"} - router_eu->>pod_eu0: GET /my-company/my-project - pod_eu0->>user: <h1>My Project... -``` - -#### Navigates to `/my-company/my-project` while not logged in - -1. User is in Europe so DNS resolves to the router in Europe -1. The router does not have `/my-company/*` cached yet so it chooses randomly `Pod EU1` -1. The `/pods/learn` is sent to `Pod EU1`, which responds that resource lives on `Pod EU0` -1. `Pod EU0` redirects them through a login flow -1. User requests `/users/sign_in`, uses random Pod to run `/pods/learn` -1. The `Pod EU1` responds with `pod_0` as a fixed route -1. User after login requests `/my-company/my-project` which is cached and stored in `Pod EU0` -1. `Pod EU0` returns the correct response - -```mermaid -sequenceDiagram - participant user as User - participant router_eu as Router EU - participant pod_eu0 as Pod EU0 - participant pod_eu1 as Pod EU1 - user->>router_eu: GET /my-company/my-project - router_eu->>pod_eu1: /api/v4/pods/learn?method=GET&path_info=/my-company/my-project - pod_eu1->>router_eu: {path: "/my-company", pod: "pod_eu0", source: "routable"} - router_eu->>pod_eu0: GET /my-company/my-project - pod_eu0->>user: 302 /users/sign_in?redirect=/my-company/my-project - user->>router_eu: GET /users/sign_in?redirect=/my-company/my-project - router_eu->>pod_eu1: /api/v4/pods/learn?method=GET&path_info=/users/sign_in - pod_eu1->>router_eu: {path: "/users", pod: "pod_eu0", source: "fixed"} - router_eu->>pod_eu0: GET /users/sign_in?redirect=/my-company/my-project - pod_eu0-->>user: <h1>Sign in... - user->>router_eu: POST /users/sign_in?redirect=/my-company/my-project - router_eu->>pod_eu0: POST /users/sign_in?redirect=/my-company/my-project - pod_eu0->>user: 302 /my-company/my-project - user->>router_eu: GET /my-company/my-project - router_eu->>pod_eu0: GET /my-company/my-project - router_eu->>pod_eu0: GET /my-company/my-project - pod_eu0->>user: <h1>My Project... -``` - -#### Navigates to `/my-company/my-other-project` after last step - -1. User is in Europe so DNS resolves to the router in Europe -1. The router cache now has `/my-company/* => Pod EU0`, so the router chooses `Pod EU0` -1. `Pod EU0` returns the correct response as well as the cache header again - -```mermaid -sequenceDiagram - participant user as User - participant router_eu as Router EU - participant pod_eu0 as Pod EU0 - participant pod_eu1 as Pod EU1 - user->>router_eu: GET /my-company/my-project - router_eu->>pod_eu0: GET /my-company/my-project - pod_eu0->>user: <h1>My Project... -``` - -#### Navigates to `/gitlab-org/gitlab` after last step - -1. User is in Europe so DNS resolves to the router in Europe -1. The router has no cached value for this URL so randomly chooses `Pod EU0` -1. `Pod EU0` redirects the router to `Pod US0` -1. `Pod US0` returns the correct response as well as the cache header again - -```mermaid -sequenceDiagram - participant user as User - participant router_eu as Router EU - participant pod_eu0 as Pod EU0 - participant pod_us0 as Pod US0 - user->>router_eu: GET /gitlab-org/gitlab - router_eu->>pod_eu0: /api/v4/pods/learn?method=GET&path_info=/gitlab-org/gitlab - pod_eu0->>router_eu: {path: "/gitlab-org", pod: "pod_us0", source: "routable"} - router_eu->>pod_us0: GET /gitlab-org/gitlab - pod_us0->>user: <h1>GitLab.org... -``` - -In this case the user is not on their "default organization" so their TODO -counter will not include their normal todos. We may choose to highlight this in -the UI somewhere. A future iteration may be able to fetch that for them from -their default organization. - -#### Navigates to `/` - -1. User is in Europe so DNS resolves to the router in Europe -1. Router does not have a cache for `/` route (specifically rails never tells it to cache this route) -1. The Router choose `Pod EU0` randomly -1. The Rails application knows the users default organization is `/my-organization`, so - it redirects the user to `/organizations/my-organization/-/dashboard` -1. The Router has a cached value for `/organizations/my-organization/*` so it then sends the - request to `POD EU0` -1. `Pod EU0` serves up a new page `/organizations/my-organization/-/dashboard` which is the same - dashboard view we have today but scoped to an organization clearly in the UI -1. The user is (optionally) presented with a message saying that data on this page is only - from their default organization and that they can change their default - organization if it's not right. - -```mermaid -sequenceDiagram - participant user as User - participant router_eu as Router EU - participant pod_eu0 as Pod EU0 - user->>router_eu: GET / - router_eu->>pod_eu0: GET / - pod_eu0->>user: 302 /organizations/my-organization/-/dashboard - user->>router: GET /organizations/my-organization/-/dashboard - router->>pod_eu0: GET /organizations/my-organization/-/dashboard - pod_eu0->>user: <h1>My Company Dashboard... X-Gitlab-Pod-Cache={path_prefix:/organizations/my-organization/} -``` - -#### Navigates to `/dashboard` - -As above, they will end up on `/organizations/my-organization/-/dashboard` as -the rails application will already redirect `/` to the dashboard page. - -### Navigates to `/not-my-company/not-my-project` while logged in (but they don't have access since this project/group is private) - -1. User is in Europe so DNS resolves to the router in Europe -1. The router knows that `/not-my-company` lives in `Pod US1` so sends the request to this -1. The user does not have access so `Pod US1` returns 404 - -```mermaid -sequenceDiagram - participant user as User - participant router_eu as Router EU - participant pod_us1 as Pod US1 - user->>router_eu: GET /not-my-company/not-my-project - router_eu->>pod_us1: GET /not-my-company/not-my-project - pod_us1->>user: 404 -``` - -#### Creates a new top level namespace - -The user will be asked which organization they want the namespace to belong to. -If they select `my-organization` then it will end up on the same pod as all -other namespaces in `my-organization`. If they select nothing we default to -`GitLab.com Public` and it is clear to the user that this is isolated from -their existing organization such that they won't be able to see data from both -on a single page. - -### Experience for GitLab team member that is part of `/gitlab-org` - -Such a user is considered a legacy user and has their default organization set to -`GitLab.com Public`. This is a "meta" organization that does not really exist but -the Rails application knows to interpret this organization to mean that they are -allowed to use legacy global functionality like `/dashboard` to see data across -namespaces located on `Pod US0`. The rails backend also knows that the default pod to render any ambiguous -routes like `/dashboard` is `Pod US0`. Lastly the user will be allowed to -navigate to organizations on another pod like `/my-organization` but when they do the -user will see a message indicating that some data may be missing (eg. the -MRs/Issues/Todos) counts. - -#### Navigates to `/gitlab-org/gitlab` while not logged in - -1. User is in the US so DNS resolves to the US router -1. The router knows that `/gitlab-org` lives in `Pod US0` so sends the request - to this pod -1. `Pod US0` serves up the response - -```mermaid -sequenceDiagram - participant user as User - participant router_us as Router US - participant pod_us0 as Pod US0 - user->>router_us: GET /gitlab-org/gitlab - router_us->>pod_us0: GET /gitlab-org/gitlab - pod_us0->>user: <h1>GitLab.org... -``` - -#### Navigates to `/` - -1. User is in US so DNS resolves to the router in US -1. Router does not have a cache for `/` route (specifically rails never tells it to cache this route) -1. The Router chooses `Pod US1` randomly -1. The Rails application knows the users default organization is `GitLab.com Public`, so - it redirects the user to `/dashboards` (only legacy users can see - `/dashboard` global view) -1. Router does not have a cache for `/dashboard` route (specifically rails never tells it to cache this route) -1. The Router chooses `Pod US1` randomly -1. The Rails application knows the users default organization is `GitLab.com Public`, so - it allows the user to load `/dashboards` (only legacy users can see - `/dashboard` global view) and redirects to router the legacy pod which is `Pod US0` -1. `Pod US0` serves up the global view dashboard page `/dashboard` which is the same - dashboard view we have today - -```mermaid -sequenceDiagram - participant user as User - participant router_us as Router US - participant pod_us0 as Pod US0 - participant pod_us1 as Pod US1 - user->>router_us: GET / - router_us->>pod_us1: GET / - pod_us1->>user: 302 /dashboard - user->>router_us: GET /dashboard - router_us->>pod_us1: /api/v4/pods/learn?method=GET&path_info=/dashboard - pod_us1->>router_us: {path: "/dashboard", pod: "pod_us0", source: "routable"} - router_us->>pod_us0: GET /dashboard - pod_us0->>user: <h1>Dashboard... -``` - -#### Navigates to `/my-company/my-other-project` while logged in (but they don't have access since this project is private) - -They get a 404. - -### Experience for non-authenticated users - -Flow is similar to logged in users except global routes like `/dashboard` will -redirect to the login page as there is no default organization to choose from. - -### A new customers signs up - -They will be asked if they are already part of an organization or if they'd -like to create one. If they choose neither they end up no the default -`GitLab.com Public` organization. - -### An organization is moved from 1 pod to another - -TODO - -### GraphQL/API requests which don't include the namespace in the URL - -TODO - -### The autocomplete suggestion functionality in the search bar which remembers recent issues/MRs - -TODO - -### Global search - -TODO - -## Administrator - -### Loads `/admin` page - -1. The `/admin` is locked to `Pod US0` -1. Some endpoints of `/admin`, like Projects in Admin are scoped to a Pod - and users needs to choose the correct one in a dropdown, which results in endpoint - like `/admin/pods/pod_0/projects`. - -Admin Area settings in Postgres are all shared across all pods to avoid -divergence but we still make it clear in the URL and UI which pod is serving -the Admin Area page as there is dynamic data being generated from these pages and -the operator may want to view a specific pod. - -## More Technical Problems To Solve - -### Replicating User Sessions Between All Pods - -Today user sessions live in Redis but each pod will have their own Redis instance. We already use a dedicated Redis instance for sessions so we could consider sharing this with all pods like we do with `gitlab_users` PostgreSQL database. But an important consideration will be latency as we would still want to mostly fetch sessions from the same region. - -An alternative might be that user sessions get moved to a JWT payload that encodes all the session data but this has downsides. For example, it is difficult to expire a user session, when their password changes or for other reasons, if the session lives in a JWT controlled by the user. - -### How do we migrate between Pods - -Migrating data between pods will need to factor all data stores: - -1. PostgreSQL -1. Redis Shared State -1. Gitaly -1. Elasticsearch - -### Is it still possible to leak the existence of private groups via a timing attack? - -If you have router in EU, and you know that EU router by default redirects -to EU located Pods, you know their latency (lets assume 10 ms). Now, if your -request is bounced back and redirected to US which has different latency -(lets assume that roundtrip will be around 60 ms) you can deduce that 404 was -returned by US Pod and know that your 404 is in fact 403. - -We may defer this until we actually implement a pod in a different region. Such timing attacks are already theoretically possible with the way we do permission checks today but the timing difference is probably too small to be able to detect. - -One technique to mitigate this risk might be to have the router add a random -delay to any request that returns 404 from a pod. - -## Should runners be shared across all pods? - -We have 2 options and we should decide which is easier: - -1. Decompose runner registration and queuing tables and share them across all - pods. This may have implications for scalability, and we'd need to consider - if this would include group/project runners as this may have scalability - concerns as these are high traffic tables that would need to be shared. -1. Runners are registered per-pod and, we probably have a separate fleet of - runners for every pod or just register the same runners to many pods which - may have implications for queueing - -## How do we guarantee unique ids across all pods for things that cannot conflict? - -This project assumes at least namespaces and projects have unique ids across -all pods as many requests need to be routed based on their ID. Since those -tables are across different databases then guaranteeing a unique ID will -require a new solution. There are likely other tables where unique IDs are -necessary and depending on how we resolve routing for GraphQL and other APIs -and other design goals it may be determined that we want the primary key to be -unique for all tables. +<!-- This redirect file can be deleted after <2023-06-13>. --> +<!-- Redirects that point to other docs in the same project expire in three months. --> +<!-- Redirects that point to docs in a different project or site (link is not relative and starts with `https:`) expire in one year. --> +<!-- Before deletion, see: https://docs.gitlab.com/ee/development/documentation/redirects.html --> diff --git a/doc/architecture/blueprints/rate_limiting/index.md b/doc/architecture/blueprints/rate_limiting/index.md index b466a54e922..17808267032 100644 --- a/doc/architecture/blueprints/rate_limiting/index.md +++ b/doc/architecture/blueprints/rate_limiting/index.md @@ -8,6 +8,8 @@ owning-stage: "~devops::enablement" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # Next Rate Limiting Architecture ## Summary @@ -375,7 +377,7 @@ hierarchy. Choosing a proper solution will require a thoughtful research. - Implementing a separate Go library which uses the same backend (for example, Redis) for rate limiting. 1. **SDK for Satellite Services (Owning Team)** - - Build Golang SDK. + - Build Go SDK. - Create examples showcasing usage of the new rate limits SDK. 1. **Team fan out for Satellite Services (Stage Groups)** diff --git a/doc/architecture/blueprints/remote_development/img/remote_dev_15_7.png b/doc/architecture/blueprints/remote_development/img/remote_dev_15_7.png Binary files differindex d0849ded94f..f36bfa24998 100644 --- a/doc/architecture/blueprints/remote_development/img/remote_dev_15_7.png +++ b/doc/architecture/blueprints/remote_development/img/remote_dev_15_7.png diff --git a/doc/architecture/blueprints/remote_development/index.md b/doc/architecture/blueprints/remote_development/index.md index 162ae04f6b6..e2647551a95 100644 --- a/doc/architecture/blueprints/remote_development/index.md +++ b/doc/architecture/blueprints/remote_development/index.md @@ -8,6 +8,8 @@ owning-stage: "~devops::create" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # Remote Development ## Summary @@ -40,6 +42,64 @@ As a [new Software Developer to a team such as Sasha](https://about.gitlab.com/h  +## Architecture + +```plantuml +@startuml +node "Kubernetes" { + [Ingress Controller] --> [GitLab Workspaces Proxy] : Decrypt Traffic + + note right of "Ingress Controller" + Customers can choose + an ingress controller + of their choice + end note + + note top of "GitLab Workspaces Proxy" + Authenticate and + authorize user traffic + end note + + [GitLab Workspaces Proxy] ..> [Workspace n] : Forward traffic\nfor workspace n + [GitLab Workspaces Proxy] ..> [Workspace 2] : Forward traffic\nfor workspace 2 + [GitLab Workspaces Proxy] --> [Workspace 1] : Forward traffic\nfor workspace 1 + + [Agentk] .up.> [Workspace n] : Applies kubernetes resources\nfor workspace n + [Agentk] .up.> [Workspace 2] : Applies kubernetes resources\nfor workspace 2 + [Agentk] .up.> [Workspace 1] : Applies kubernetes resources\nfor workspace 1 + + [Agentk] --> [Kubernetes API Server] : Interact and get/apply\nKubernetes resources +} + +node "GitLab" { + [Nginx] --> [GitLab Rails] : Forward + [GitLab Rails] --> [Postgres] : Access database + [GitLab Rails] --> [Gitaly] : Fetch files + [KAS] -up-> [GitLab Rails] : Proxy +} + +[Agentk] -up-> [KAS] : Initiate reconciliation loop +"Load Balancer IP" --> [Ingress Controller] +[Browser] --> [Nginx] : Browse GitLab +[Browser] -right-> "Domain IP" : Browse workspace URL +"Domain IP" .right.> "Load Balancer IP" +[GitLab Workspaces Proxy] ..> [GitLab Rails] : Authenticate and authorize\nthe user accessing the workspace. + +note top of "Domain IP" + For local development, workspace URL + is [workspace-name].workspaces.localdev.me + which resolves to localhost (127.0.0.1) +end note + +note top of "Load Balancer IP" + For local development, + it includes all local loopback interfaces + e.g. 127.0.0.1, 172.16.123.1, 192.168.0.1, etc. +end note + +@enduml +``` + ## Terminology We use the following terms to describe components and properties of the Remote Development architecture. @@ -68,17 +128,6 @@ Container/VM-based developer machines providing all the tools and dependencies n - A workspace should be a combination of resources that support cloud-based development environment. - Workspaces are constrained by the amount of resources provided to them. -### Legacy Web IDE - -The current production [Web IDE](../../../user/project/web_ide/index.md). - -#### Legacy Web IDE properties - -An advanced editor with commit staging that currently supports: - -- [Live Preview](../../../user/project/web_ide/index.md#live-preview-removed) -- [Interactive Web Terminals](../../../user/project/web_ide/index.md#interactive-web-terminals-for-the-web-ide) - ### Web IDE VS Code for web - replacement of our current legacy Web IDE. @@ -137,145 +186,6 @@ As a zero-install development environment that runs in your browser, Remote Deve GitLab.com is only hosted within the United States of America. Organizations located in other regions have voiced demand for local SaaS offerings. BYO infrastructure helps work in conjunction with [GitLab Regions](https://gitlab.com/groups/gitlab-org/-/epics/6037) because a user's workspace may be deployed within different geographies. The ability to deploy workspaces to different geographies might also help to solve data residency and compliance problems. -## High-level architecture problems to solve - -A number of technical issues need to be resolved to implement a stable Remote Development offering. This section will be expanded. - -- Who is our main persona for BYO infrastructure? -- How do users authenticate? -- How do we support more than one IDE? -- How are workspaces provisioned? -- How can workspaces implement disaster recovery capabilities? -- If we cannot use SSH, what are the viable alternatives for establishing a secure WebSocket connection? -- Are we running into any limitations in functionality with the Web IDE by not having it running in the container itself? For example, are we going to get code completion, linting, and language server type features to work with our approach? -- How will our environments be provisioned, managed, created, destroyed, etc.? -- To what extent do we need to provide the user with a UI to interact with the provisioned environments? -- How will the files inside the workspace get live updated based on changes in the Web IDE? Are we going to use a [CRDT](https://en.wikipedia.org/wiki/Conflict-free_replicated_data_type)-like setup to patch files in a container? Are we going to generate a diff and send it though a WebSocket connection? - -## Iteration plan - -We can't ship the entire Remote Development architecture in one go - it is too large. Instead, we are adopting an iteration plan that provides value along the way. - -- Use GitLab Agent for Kubernetes Remote Development Module. -- Integrate Remote Development with the UI and Web IDE. -- Improve security and usability. - -### High-level approach - -The nuts and bolts are being worked out at [Remote Development GA4K Architecture](https://gitlab.com/gitlab-org/remote-development/gitlab-remote-development-docs/-/blob/main/doc/architecture.md) to keep a SSoT. Once we have hammered out the details, we'll replace this section with the diagram in the above repository. - -### Iteration 0: [GitLab Agent for Kubernetes Remote Development Module (plumbing)](https://gitlab.com/groups/gitlab-org/-/epics/9138) - -#### Goals - -- Use the [GitLab Agent](../../../user/clusters/agent/index.md) integration. -- Create a workspace in a Kubernetes cluster based on a `devfile` in a public repository. -- Install the IDE and dependencies as defined. -- Report the status of the environment (via the terminal or through an endpoint). -- Connect to an IDE in the workspace. - -#### Requirements - -- Remote environment running on a Kubernetes cluster based on a `devfile` in a repo. - -These are **not** part of Iteration 0: - -- Authentication/authorization with GitLab and a user. -- Integration of Remote Development with the GitLab UI and Web IDE. -- Using GA4K instead of an Ingress controller. - -#### Assumptions - -- We will use [`devworkspace-operator` v0.17.0 (latest version)](https://github.com/devfile/devworkspace-operator/releases/tag/v0.17.0). A prerequisite is [`cert-manager`](https://github.com/devfile/devworkspace-operator#with-yaml-resources). -- We have an Ingress controller ([Ingress-NGINX](https://github.com/kubernetes/ingress-nginx)), which is accessible over the network. -- The initial server is stubbed. - -#### Success criteria - -- Using GA4K to communicate with the Kubernetes API from the `remote_dev` agent module. -- All calls to the Kubernetes API are done through GA4K. -- A workspace in a Kubernetes cluster created using DevWorkspace Operator. - -### Iteration 1: [Rails endpoints, authentication, and authorization](https://gitlab.com/groups/gitlab-org/-/epics/9323) - -#### Goals - -- Add endpoints in Rails to accept work from a user. -- Poll Rails for work from KAS. -- Add authentication and authorization to the workspaces created in the Kubernetes cluster. -- Extend the GA4K `remote_dev` agent module to accept more types of work (get details of a workspace, list workspaces for a user, etc). -- Build an editor injector for the GitLab fork of VS Code. - -#### Requirements - -- [GitLab Agent for Kubernetes Remote Development Module (plumbing)](https://gitlab.com/groups/gitlab-org/-/epics/9138) is complete. - -These are **not** part of Iteration 1: - -- Integration of Remote Development with the GitLab UI and Web IDE. -- Using GA4K instead of an Ingress controller. - -#### Assumptions - -- TBA - -#### Success criteria - -- Poll Rails for work from KAS. -- Rails endpoints to create/delete/get/list workspaces. -- All requests are correctly authenticated and authorized except where the user has requested the traffic to be public (for example, opening a server while developing and making it public). -- A user can create a workspace, start a server on that workspace, and have that traffic become private/internal/public. -- We are using the GitLab fork of VS Code as an editor. - -### Iteration 2: [Integrate Remote Development with the UI and Web IDE](https://gitlab.com/groups/gitlab-org/-/epics/9169) - -#### Goals - -- Allow users full control of their workspaces via the GitLab UI. - -#### Requirements - -- [GitLab Agent for Kubernetes Remote Development Module](https://gitlab.com/groups/gitlab-org/-/epics/9138). - -These are **not** part of Iteration 2: - -- Usability improvements -- Security improvements - -#### Success criteria - -- Be able to list/create/delete/stop/start/restart workspaces from the UI. -- Be able to create workspaces for the user in the Web IDE. -- Allow the Web IDE terminal to connect to different containers in the workspace. -- Configure DevWorkspace Operator for user-expected configuration (30-minute workspace timeout, a separate persistent volume for each workspace that is deleted when the workspace is deleted, etc.). - -### Iteration 3: [Improve security and usability](https://gitlab.com/groups/gitlab-org/-/epics/9170) - -#### Goals - -- Improve security and usability of our Remote Development solution. - -#### Requirements - -- [Integrate Remote Development with the UI and Web IDE](https://gitlab.com/groups/gitlab-org/-/epics/9169) is complete. - -#### Assumptions - -- We are allowing for internal feedback and closed/early customer feedback that can be iterated on. -- We have explored or are exploring the feasibility of using GA4K with Ingresses in [Solving Ingress problems for Remote Development](https://gitlab.com/gitlab-org/gitlab/-/issues/378998). -- We have explored or are exploring Kata containers for providing root access to workspace users in [Investigate Kata Containers / Firecracker / gVisor](https://gitlab.com/gitlab-org/gitlab/-/issues/367043). -- We have explored or are exploring how Ingress/Egress requests cannot be misused from [resources within or outside the cluster](https://gitlab.com/gitlab-org/remote-development/gitlab-remote-development-docs/-/blob/main/doc/securing-the-workspace.md) (security hardening). - -#### Success criteria - -Add options to: - -- Create different classes of workspaces (1gb-2cpu, 4gb-8cpu, etc.). -- Vertically scale up workspace resources. -- Inject secrets from a GitLab user/group/repository. -- Configure timeouts of workspaces at multiple levels. -- Allow users to expose endpoints in their workspace (for example, not allow anyone in the organization to expose any endpoint publicly). - ## Market analysis We have conducted a market analysis to understand the broader market and what others can offer us by way of open-source libraries, integrations, or partnership opportunities. We have broken down the effort into a set of issues where we investigate each potential competitor/pathway/partnership as a spike. @@ -283,13 +193,15 @@ We have conducted a market analysis to understand the broader market and what ot - [Market analysis](https://gitlab.com/groups/gitlab-org/-/epics/8131) - [YouTube results](https://www.youtube.com/playlist?list=PL05JrBw4t0KrRQhnSYRNh1s1mEUypx67-) -### Next Steps +### Implementation -While our spike proved fruitful, we have paused this investigation until we reach our goals in [Viable Maturity](https://gitlab.com/groups/gitlab-org/-/epics/9190). +- [Viable Maturity Epic](https://gitlab.com/groups/gitlab-org/-/epics/9190) to track progress. +- [Documentation](https://gitlab.com/gitlab-org/remote-development/gitlab-remote-development-docs) +explaining the architecture and implementation details. -## Che versus a custom-built solution +## Che vs. DevWorkspace Operatoor vs. Custom-Built Solution -After an investigation into using [Che](https://gitlab.com/gitlab-org/gitlab/-/issues/366052) as our backend to accelerate Remote Development, we ultimately opted to [write our own custom-built solution](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/97449#note_1131215629). +After an investigation into using [Che](https://gitlab.com/gitlab-org/gitlab/-/issues/366052) as our backend to accelerate Remote Development, we ultimately opted to [write our own custom-built solution using DevWorkspace Operator](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/97449#note_1131215629). Some advantages of us opting to write our own custom-built solution are: @@ -297,6 +209,10 @@ Some advantages of us opting to write our own custom-built solution are: - It is easier to add support for other configurations apart from `devfile` in the future if the need arises. - We have the ability to choose which tech stack to use (for example, instead of using Traefik which is used in Che, explore NGINX itself or use GitLab Agent for Kubernetes). +After writing our own custom-built solution using DevWorkspace Operator, +we decided to [remove the dependency on DevWorkspace Operator](https://gitlab.com/groups/gitlab-org/-/epics/9895) +and thus the transitive dependency of Cert Manager. + ## Links - [Remote Development presentation](https://docs.google.com/presentation/d/1XHH_ZilZPufQoWVWViv3evipI-BnAvRQrdvzlhBuumw/edit#slide=id.g131f2bb72e4_0_8) @@ -304,7 +220,7 @@ Some advantages of us opting to write our own custom-built solution are: - [Minimal Maturity epic](https://gitlab.com/groups/gitlab-org/-/epics/9189) - [Viable Maturity epic](https://gitlab.com/groups/gitlab-org/-/epics/9190) - [Complete Maturity epic](https://gitlab.com/groups/gitlab-org/-/epics/9191) -- [Bi-weekly sync](https://docs.google.com/document/d/1hWVvksIc7VzZjG-0iSlzBnLpyr-OjwBVCYMxsBB3h_E/edit#) +- [Remote Development sync](https://docs.google.com/document/d/1hWVvksIc7VzZjG-0iSlzBnLpyr-OjwBVCYMxsBB3h_E/edit#) - [Market analysis and architecture](https://gitlab.com/groups/gitlab-org/-/epics/8131) - [GA4K Architecture](https://gitlab.com/gitlab-org/remote-development/gitlab-remote-development-docs/-/blob/main/doc/architecture.md) - [BYO infrastructure](https://gitlab.com/groups/gitlab-org/-/epics/8290) diff --git a/doc/architecture/blueprints/runner_scaling/index.md b/doc/architecture/blueprints/runner_scaling/index.md index 53401d80e34..de1203843aa 100644 --- a/doc/architecture/blueprints/runner_scaling/index.md +++ b/doc/architecture/blueprints/runner_scaling/index.md @@ -8,6 +8,8 @@ owning-stage: "~devops::verify" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # Next Runner Auto-scaling Architecture ## Summary @@ -214,12 +216,12 @@ sequence diagram.  -On the diagrams above we see that currently a GitLab Runner Manager runs on a +On the diagrams above we see that currently a runner manager runs on a machine that has access to a cloud provider's API. It is using Docker Machine to provision new Virtual Machines with Docker Engine installed and it configures the Docker daemon there to allow external authenticated requests. It stores credentials to such ephemeral Docker environments on disk. Once a -machine has been provisioned and made available for GitLab Runner Manager to +machine has been provisioned and made available for the runner manager to run builds, it is using one of the existing executors to run a user-provided script. In auto-scaling, this is typically done using the Docker executor. @@ -281,7 +283,7 @@ coupled with the VM lifecycle and job routing logic. Creating idle capacity happens as a side-effect of calling [`Acquire`](https://gitlab.com/gitlab-org/gitlab-runner/-/blob/267f40d871cd260dd063f7fbd36a921fedc62241/executors/docker/machine/provider.go#L449) on the `machineProvider` while binding a job to a VM. There is also no current abstraction for in-VM job execution. VM-specific -commands are generated by the Runner Manager using the [`GenerateShellScript`](https://gitlab.com/gitlab-org/gitlab-runner/-/blob/267f40d871cd260dd063f7fbd36a921fedc62241/common/build.go#L336) +commands are generated by the runner manager using the [`GenerateShellScript`](https://gitlab.com/gitlab-org/gitlab-runner/-/blob/267f40d871cd260dd063f7fbd36a921fedc62241/common/build.go#L336) function and [injected](https://gitlab.com/gitlab-org/gitlab-runner/-/blob/267f40d871cd260dd063f7fbd36a921fedc62241/common/build.go#L373) into the VM as the manager drives the job execution stages. diff --git a/doc/architecture/blueprints/runner_tokens/index.md b/doc/architecture/blueprints/runner_tokens/index.md index 69a10674d7d..0d3cc9c3e17 100644 --- a/doc/architecture/blueprints/runner_tokens/index.md +++ b/doc/architecture/blueprints/runner_tokens/index.md @@ -8,6 +8,8 @@ owning-stage: "~devops::verify" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # Next GitLab Runner Token Architecture ## Summary @@ -183,14 +185,17 @@ CREATE TABLE ci_runners ( ) ``` -The `ci_builds_metadata` table shall reference `ci_runner_machines`. +A new `p_ci_runner_machine_builds` table joins the `ci_runner_machines` and `ci_builds` tables, to avoid +adding more pressure to those tables. We might consider a more efficient way to store `contacted_at` than updating the existing record. ```sql -CREATE TABLE ci_builds_metadata ( - ... +CREATE TABLE p_ci_runner_machine_builds ( + partition_id bigint DEFAULT 100 NOT NULL, + build_id bigint NOT NULL, runner_machine_id bigint NOT NULL -); +) +PARTITION BY LIST (partition_id); CREATE TABLE ci_runner_machines ( id bigint NOT NULL, @@ -370,44 +375,55 @@ scope. | GitLab Rails app | `%15.8` | Create database migration to add `config` column to `ci_runner_machines` table. | | GitLab Runner | `%15.9` | Start sending `system_id` value in `POST /jobs/request` request and other follow-up requests that require identifying the unique system. | | GitLab Rails app | `%15.9` | Create service similar to `StaleGroupRunnersPruneCronWorker` service to clean up `ci_runner_machines` records instead of `ci_runners` records.<br/>Existing service continues to exist but focuses only on legacy runners. | -| GitLab Rails app | `%15.9` | [Feature flag] Rollout of `create_runner_machine`. | +| GitLab Rails app | `%15.9` | Implement the `create_runner_machine` [feature flag](../../../administration/feature_flags.md). | | GitLab Rails app | `%15.9` | Create `ci_runner_machines` record in `POST /runners/verify` request if the runner token is prefixed with `glrt-`. | | GitLab Rails app | `%15.9` | Use runner token + `system_id` JSON parameters in `POST /jobs/request` request in the [heartbeat request](https://gitlab.com/gitlab-org/gitlab/blob/c73c96a8ffd515295842d72a3635a8ae873d688c/lib/api/ci/helpers/runner.rb#L14-20) to update the `ci_runner_machines` cache/table. | -| GitLab Rails app | `%15.9` | [Feature flag] Enable runner creation workflow (`create_runner_workflow`). | +| GitLab Rails app | `%15.9` | Implement the `create_runner_workflow_for_admin` [feature flag](../../../administration/feature_flags.md). | | GitLab Rails app | `%15.9` | Implement `create_{instance|group|project}_runner` permissions. | | GitLab Rails app | `%15.9` | Rename `ci_runner_machines.machine_xid` column to `system_xid` to be consistent with `system_id` passed in APIs. | -| GitLab Rails app | `%15.10` | Drop `ci_runner_machines.machine_xid` column. | -| GitLab Rails app | `%15.11` | Remove the ignore rule for `ci_runner_machines.machine_xid` column. | +| GitLab Rails app | `%15.10` | Remove the ignore rule for `ci_runner_machines.machine_xid` column. | +| GitLab Rails app | `%15.10` | Replace `ci_builds_metadata.runner_machine_id` with a new join table. | +| GitLab Rails app | `%15.11` | Drop `ci_builds_metadata.runner_machine_id` column. | +| GitLab Rails app | `%16.0` | Remove the ignore rule for `ci_builds_metadata.runner_machine_id` column. | ### Stage 4 - Create runners from the UI | Component | Milestone | Changes | |------------------|----------:|---------| -| GitLab Rails app | `%15.9` | Implement new GraphQL user-authenticated API to create a new runner. | | GitLab Rails app | `%15.9` | [Add prefix to newly generated runner authentication tokens](https://gitlab.com/gitlab-org/gitlab/-/issues/383198). | +| GitLab Rails app | `%15.9` | Add new runner field for with token that is used in registration | +| GitLab Rails app | `%15.9` | Implement new GraphQL user-authenticated API to create a new runner. | | GitLab Rails app | `%15.10` | Return token and runner ID information from `/runners/verify` REST endpoint. | | GitLab Runner | `%15.10` | [Modify register command to allow new flow with glrt- prefixed authentication tokens](https://gitlab.com/gitlab-org/gitlab-runner/-/issues/29613). | -| GitLab Rails app | `%15.10` | Implement UI to create new runner. | -| GitLab Rails app | `%15.10` | GraphQL changes to `CiRunner` type. | -| GitLab Rails app | `%15.10` | UI changes to runner details view (listing of platform, architecture, IP address, etc.) (?) | +| GitLab Runner | `%15.10` | Make the `gitlab-runner register` command happen in a single operation. | +| GitLab Rails app | `%15.10` | Define feature flag and policies for "New Runner creation workflow" for groups and projects. | +| GitLab Rails app | `%15.10` | Only update runner `contacted_at` and `status` when polled for jobs. | +| GitLab Rails app | `%15.10` | Add GraphQL type to represent runner machines under `CiRunner`. | +| GitLab Rails app | `%15.11` | Implement UI to create new instance runner. | +| GitLab Rails app | `%15.11` | Update service and mutation to accept groups and projects. | +| GitLab Rails app | `%15.11` | Implement UI to create new group/project runners. | +| GitLab Rails app | `%15.11` | Add runner_machine field to CiJob GraphQL type. | +| GitLab Rails app | `%15.11` | UI changes to runner details view (listing of platform, architecture, IP address, etc.) (?) | | GitLab Rails app | `%15.11` | Adapt `POST /api/v4/runners` REST endpoint to accept a request from an authorized user with a scope instead of a registration token. | +| GitLab Runner | `%15.11` | Handle `glrt-` runner tokens in `unregister` command. | +| GitLab Runner | `%15.11` | Runner asks for registration token when a `glrt-` runner token is passed in `--token`. | +| GitLab Rails app | `%15.11` | Move from 'runner machine' terminology to 'runner manager'. | ### Stage 5 - Optional disabling of registration token | Component | Milestone | Changes | |------------------|----------:|---------| -| GitLab Rails app | `%15.11` | Adapt `register_{group|project}_runner` permissions to take [application setting](https://gitlab.com/gitlab-org/gitlab/-/issues/386712) in consideration. | -| GitLab Rails app | `%15.11` | Add UI to allow disabling use of registration tokens at project or group level. | -| GitLab Rails app | `%15.11` | Introduce `:enforce_create_runner_workflow` feature flag (disabled by default) to control whether use of registration tokens is allowed. | -| GitLab Rails app | `%15.11` | Make [`POST /api/v4/runners` endpoint](../../../api/runners.md#register-a-new-runner) permanently return `HTTP 410 Gone` if either `allow_runner_registration_token` setting or `:enforce_create_runner_workflow` feature flag disables registration tokens.<br/>A future v5 version of the API should return `HTTP 404 Not Found`. | -| GitLab Rails app | `%15.11` | Start refusing job requests that don't include a unique ID, if either `allow_runner_registration_token` setting or `:enforce_create_runner_workflow` feature flag disables registration tokens. | -| GitLab Rails app | `%15.11` | Hide legacy UI showing registration with a registration token, if `:enforce_create_runner_workflow` feature flag disables registration tokens. | +| GitLab Rails app | `%16.0` | Adapt `register_{group|project}_runner` permissions to take [application setting](https://gitlab.com/gitlab-org/gitlab/-/issues/386712) in consideration. | +| GitLab Rails app | | Add UI to allow disabling use of registration tokens at project or group level. | +| GitLab Rails app | | Introduce `:enforce_create_runner_workflow` feature flag (disabled by default) to control whether use of registration tokens is allowed. | +| GitLab Rails app | | Make [`POST /api/v4/runners` endpoint](../../../api/runners.md#register-a-new-runner) permanently return `HTTP 410 Gone` if either `allow_runner_registration_token` setting or `:enforce_create_runner_workflow` feature flag disables registration tokens.<br/>A future v5 version of the API should return `HTTP 404 Not Found`. | +| GitLab Rails app | | Start refusing job requests that don't include a unique ID, if either `allow_runner_registration_token` setting or `:enforce_create_runner_workflow` feature flag disables registration tokens. | +| GitLab Rails app | | Hide legacy UI showing registration with a registration token, if `:enforce_create_runner_workflow` feature flag disables registration tokens. | ### Stage 6 - Enforcement | Component | Milestone | Changes | |------------------|----------:|---------| -| GitLab Runner | `%16.0` | Do not allow runner to start if `.runner_system_id` file cannot be written. | | GitLab Rails app | `%16.6` | Enable `:enforce_create_runner_workflow` feature flag by default. | | GitLab Rails app | `%16.6` | Start reject job requests that don't include `system_id` value. | @@ -495,7 +511,7 @@ gitlab-runner register --executor "shell" \ --url "https://gitlab.com/" \ --non-interactive \ - --registration-token="grlt-2CR8_eVxiioB1QmzPZwa" + --registration-token="glrt-2CR8_eVxiioB1QmzPZwa" ``` ### How does this change impact auto-scaling scenarios? diff --git a/doc/architecture/blueprints/secret_detection/index.md b/doc/architecture/blueprints/secret_detection/index.md index 26551367a7c..fc97ca71d7f 100644 --- a/doc/architecture/blueprints/secret_detection/index.md +++ b/doc/architecture/blueprints/secret_detection/index.md @@ -1,5 +1,5 @@ --- -status: proposed +status: ongoing creation-date: "2022-11-25" authors: [ "@theoretick" ] coach: "@DylanGriffith" @@ -8,6 +8,8 @@ owning-stage: "~devops::secure" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # Secret Detection as a platform-wide experience ## Summary @@ -24,7 +26,7 @@ job logs, and project management features such as issues, epics, and MRs. ### Goals -- Support asynchronous secret detection for: +- Support asynchronous secret detection for the following scan targets: - push events - issuable creation - issuable updates @@ -47,6 +49,24 @@ Scanned object types beyond the scope of this MVC include: - Snippets - Wikis +#### Management UI + +Development of an independent interface for managing secrets is out of scope +for this blueprint. Any detections will be managed using the existing +Vulnerability Management UI. + +Management of detected secrets will remain distinct from the +[Secret Management feature capability](../../../ci/secrets/index.md) as +"detected" secrets are categorically distinct from actively "managed" secrets. +When a detected secret is identified, it has already been compromised due to +their presence in the target object (that is a repository). Alternatively, managed +secrets should be stored with stricter standards for secure storage, including +encryption and masking when visible (such as job logs or in the UI). + +As a long-term priority we should consider unifying the management of the two +secret types however that work is out of scope for the current blueprints goals, +which remain focused on active detection. + ## Proposal To achieve scalable secret detection for a variety of domain objects a dedicated @@ -67,6 +87,7 @@ as self-managed instances. - Secure authentication to GitLab.com infrastructure - Performance of scanning against large blobs - Performance of scanning against volume of domain objects (such as push frequency) +- Queueing of scan requests ## Design and implementation details @@ -74,13 +95,13 @@ The critical paths as outlined under [goals above](#goals) cover two major objec types: Git blobs (corresponding to push events) and arbitrary text blobs. The detection flow for push events relies on subscribing to the PostReceive hook -and enqueueing Sidekiq requests to the `SecretScanningService`. The `SecretScanningService` +to enqueue Sidekiq requests to the `SecretScanningService`. The `SecretScanningService` service fetches enqueued refs, queries Gitaly for the ref blob contents, scans the commit contents, and notifies the Rails application when a secret is detected. See [Push event detection flow](#push-event-detection-flow) for sequence. The detection flow for arbitrary text blobs, such as issue comments, relies on -subscribing to `Notes::PostProcessService` (or equivalent service) and enqueueing +subscribing to `Notes::PostProcessService` (or equivalent service) to enqueue Sidekiq requests to the `SecretScanningService` to process the text blob by object type and primary key of domain object. The `SecretScanningService` service fetches the relevant text blob, scans the contents, and notifies the Rails application when a secret @@ -92,7 +113,7 @@ around scanning during streaming and the added complexity in buffering lookbacks for arbitrary trace chunks. In any case of detection, the Rails application manually creates a vulnerability -using the `Vulnerabilities::ManuallyCreateService` to surface the finding within the +using the `Vulnerabilities::ManuallyCreateService` to surface the finding in the existing Vulnerability Management UI. See [technical discovery](https://gitlab.com/gitlab-org/gitlab/-/issues/376716) @@ -115,7 +136,7 @@ Token types to identify in order of importance: ### Detection engine Our current secret detection offering utilizes [Gitleaks](https://github.com/zricethezav/gitleaks/) -for all secret scanning within pipeline contexts. By using its `--no-git` configuration +for all secret scanning in pipeline contexts. By using its `--no-git` configuration we can scan arbitrary text blobs outside of a repository context and continue to utilize it for non-pipeline scanning. @@ -123,6 +144,23 @@ Given our existing familiarity with the tool and its extensibility, it should remain our engine of choice. Changes to the detection engine are out of scope unless benchmarking unveils performance concerns. +Notable alternatives include high-performance regex engines such as [hyperscan](https://github.com/intel/hyperscan) or it's portable fork [vectorscan](https://github.com/VectorCamp/vectorscan). + +### High-level architecture + +The implementation of the secret scanning service is highly dependent on the outcomes of our benchmarking +and capacity planning against both GitLab.com and our +[Reference Architectures](../../../administration/reference_architectures/index.md). +As the scanning capability must be an on-by-default component of both our SaaS and self-managed +instances [the PoC](#iterations), the deployment characteristics must be considered to determine whether +this is a standalone component or executed as a subprocess of the existing Sidekiq worker fleet +(similar to the implementation of our Elasticsearch indexing service). + +Similarly, the scan target volume will require a robust and scalable enqueueing system to limit resource consumption. + +See [this thread](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/105142#note_1194863310) +for past discussion around scaling approaches. + ### Push event detection flow ```mermaid @@ -151,17 +189,20 @@ sequenceDiagram ## Iterations -1. Requirements definition for detection coverage and actions -1. PoC of secret scanning service - 1. gRPC commit retrieval from Gitaly - 1. blob scanning - 1. benchmarking of issuables, comments, job logs and blobs to gain confidence that the total costs will be viable -1. Implementation of secret scanning service MVC (targeting individual commits) -1. Security and readiness review -1. Deployment and monitoring -1. Implementation of secret scanning service MVC (targeting arbitrary text blobs) -1. Deployment and monitoring -1. High priority domain object rollout (priority `TBD`) - 1. Issuable comments - 1. Issuable bodies - 1. Job logs +- ✓ Define [requirements for detection coverage and actions](https://gitlab.com/gitlab-org/gitlab/-/issues/376716) +- ✓ Implement [Clientside detection of GitLab tokens in comments/issues](https://gitlab.com/gitlab-org/gitlab/-/issues/368434) +- PoC of secret scanning service + - Benchmarking of issuables, comments, job logs and blobs to gain confidence that the total costs will be viable + - Capacity planning for addition of service component to Reference Architectures headroom + - Service capabilities + - gRPC commit retrieval from Gitaly + - blob scanning +- Implementation of secret scanning service MVC (targeting individual commits) +- Security and readiness review +- Deployment and monitoring +- Implementation of secret scanning service MVC (targeting arbitrary text blobs) +- Deployment and monitoring +- High priority domain object rollout (priority `TBD`) + - Issuable comments + - Issuable bodies + - Job logs diff --git a/doc/architecture/blueprints/work_items/index.md b/doc/architecture/blueprints/work_items/index.md index 2c854ecea59..f067d9fab52 100644 --- a/doc/architecture/blueprints/work_items/index.md +++ b/doc/architecture/blueprints/work_items/index.md @@ -8,6 +8,8 @@ owning-stage: "~devops::plan" participating-stages: [] --- +<!-- vale gitlab.FutureTense = NO --> + # Work Items This document is a work-in-progress. Some aspects are not documented, though we expect to add them in the future. diff --git a/doc/architecture/index.md b/doc/architecture/index.md index 2467ba33fae..9fccd1c21d1 100644 --- a/doc/architecture/index.md +++ b/doc/architecture/index.md @@ -1,6 +1,5 @@ --- feedback: false -comments: false toc: false --- |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}